반응형
내 맘대로 Introduction

CVPR2025에서 많이 샤라웃됐던 논문. 아주 실용적인 목적을 사용성도 좋게 만들었고 성능도 좋아서 내가 봐도 눈에 띈다. 아주 좋은 컨셉의 좋은 논문.
핵심 내용은 3DGS가 부족한 렌더링 결과를 보일 때가 많은데, 부족한 렌더링 결과를 diffusion prior를 이용해 realistic하게 복원하는 것이다. 이게 가능하다면 부족한 렌더링 결과를 모델로 보정한 뒤, 다시 한번 3DGS 최적화를 돌리면 3DGS를 개선할 수 있다. 단순히 이미지만 취득하고 싶을 경우에는 postprocessing 개념으로 뒤에 붙이기만 해도 된다.
한마디로 좋은 결과물 3DGS 결과물을 얻고 싶을 때 활용하기 좋은 도구로써 아주 의미가 있다.
메모
 |
|
 |
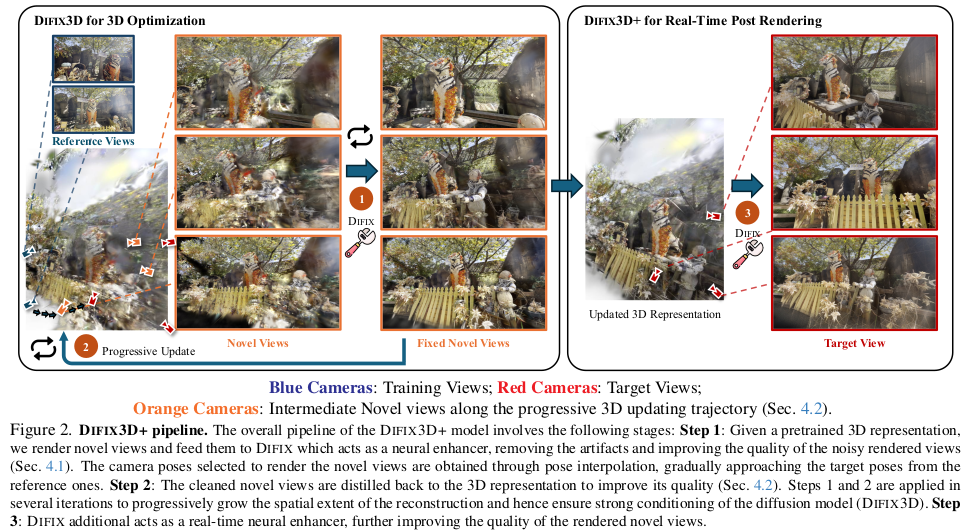
불완전 3DGS 렌더링 이미지를 single step으로 realistic image로 바꿔주는 SD-Turbo tuning 모델을 만들자. 만들어두면 3DGS 복원 optimization에 끼워넣어 쓸 수도있고 후처리로 inference 시에 쓸 수도 있다. |
  |
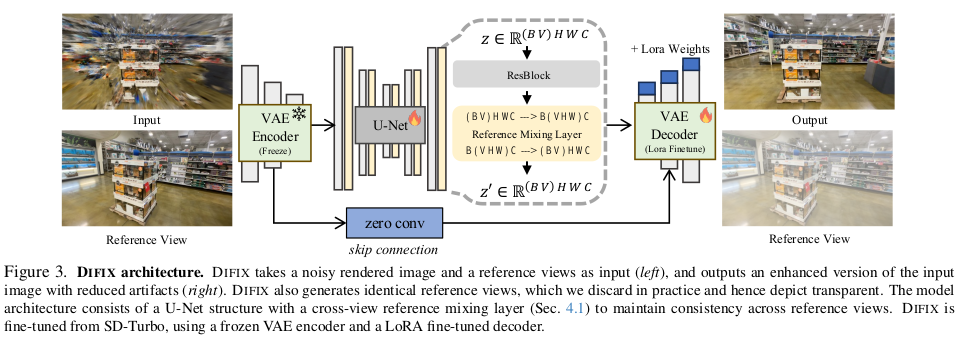
튜닝할 때 단순히 single input single output으로 구성할 수 도 있지만 조금 더 뛰어난 성능을 위해 multiview input으로 바꿨다. 정확히는 1개 시점은 noisy rendering이고 나머지 N-1개는 멀쩡한 real 이미지를 넣어서 학습했다. 그리고 VIEW * HEIGHT * WEIGHT 로 aggregation하고 attention을 걸어주는 식이다. 의도하는 것은 다른 시점의 정보를 끌어와서 noisy rendering 시점의 이미지를 개선하는데 활용하도록 하는 것. 이건 video나 multiview diffusion model에서 주로 쓰던 방식인데 이렇게 활용했다. (아이디어 좋음) |
 |
 |
pretrained backbone은 SD-Turbo다. 경험적으로 SD시리즈 중에 SD-Turbo가 최근에 많이 쓰이는 듯 한데 잘 고른 것 같다. 렌더링된 이미지가 이미 일종의 noise가 더해진 이미지기 때문에 별도의 noise를 더하지 않고 그대로 입력으로 사용하며 단 한번만 denoise한다. 3DGS 렌더링 artifact들이 diffusion noise와 비슷하게 볼 수도 있다는 점에서 렌더링 이미지는 상당히 denoise가 많이 된 상태라고 볼 수 있고 single step만 업데이트해서 끝내겠단 마인드. 그래서 time step도 작게 준다. 200. 이렇게 하면 inference 시간이 확 줄어드니까 좋다. |
  |
loss는 이게 끝. 캬~ 진짜 아이디어 하나로 승부 본 논문인데 진짜 기가 막힌다. |
 |
데이터셋을 만들 때는 25%~75%만 학습시킨 모델을 수두룩하게 만들어 놓고 활용했다고 함. 이 복원 시간과 용량이 이 논문 작성할 때 가장 오래 걸렸을 듯. |
  |
이후 DIFIX3D가 붙은 것은 사실 새로운 알고리즘적 내용은 아니도 앞에 학습시킨 모델을 어떻게 활용하냐의 내용이다. 각 시점을 렌더링한 뒤 후처리 처럼 모델로 REALISTIC하게 바꿀 경우에 대개 만족스럽지만 3DGS consistency를 중요하게 생각한다면 아쉬울 수 있다. |
  그래서 그 경우 아예 3DGS 복원 과정에 DIFIX를 추가해서 보정된 이미지를 복원에 활용할 수 있도록 해버리면 좋다. |
 그리고 진짜 최최최종으로 한 번더 "DIFIX로 만든 3DGS로 만든 렌더링을 DIFIX로 보정한다." ㅋㅋ |
 |
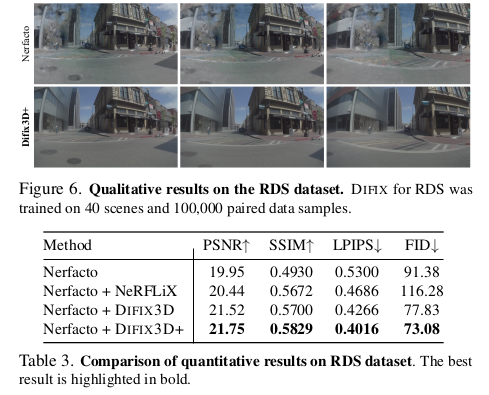
 데모도 그렇고 직접 써봤는데 잘되긴 한다. |
 복원 중간 과정에 DIFIX를 끼워넣는 순간 입력 이미지의 퀄리티에 영향을 덜 받기 때문에 항상 좋은 결과를 얻을 수 있음. |
|
 |
 |
 |
 |
반응형