반응형
내 맘대로 Introduction

이 논문은 진짜 여러모로 유명하다. diffusion이 생성형 시장을 독식하고 있는 와중에 일각에서 autoregressive transformer로 돌파하려는 시도가 있었다. 근데 눈에 띄는 성과를 거두지 못하고 연산량 문제도 있어서 "굳이?"라는 시선을 받고 말았는데 이 논문을 기점으로 diffusion을 넘어설 수 있지 않을까란 기대가 생겼다. 또 유명한 이유는 1저자의 도덕성 문제로 대서특필된 바 있다. bytedance에 금전적인 피해를 끼치고 다른 실험들을 망치면서까지 실험해서 낸 논문으로 별명이 붙었다.
핵심은 image token을 flatten에서 1D로 처리하는 것이 아니라 coarse to fine token으로 만들어서 접근한 것. + autoregressive model 특징에 딱 맞게 이전 정보로 미래 정보를 추정하도록, 즉 과거 정보는 참조 못하도록 제한한 것이다. 아이디어도 깔끔하고, 이해하기 쉬워서 논문의 분량은 짧다. 이걸 실험적으로 증명하기 위한 막대한 GPU/TPU와 데이터, 실험 횟수가 눈에 띈다.
이번에 OpenAI에서 새로 낸 생성형 모델도 왠지 AR model 쓴 것 같다. Diffusion 방식을 고수했는데 이렇게 성능이 뛰었을리가...?
메모
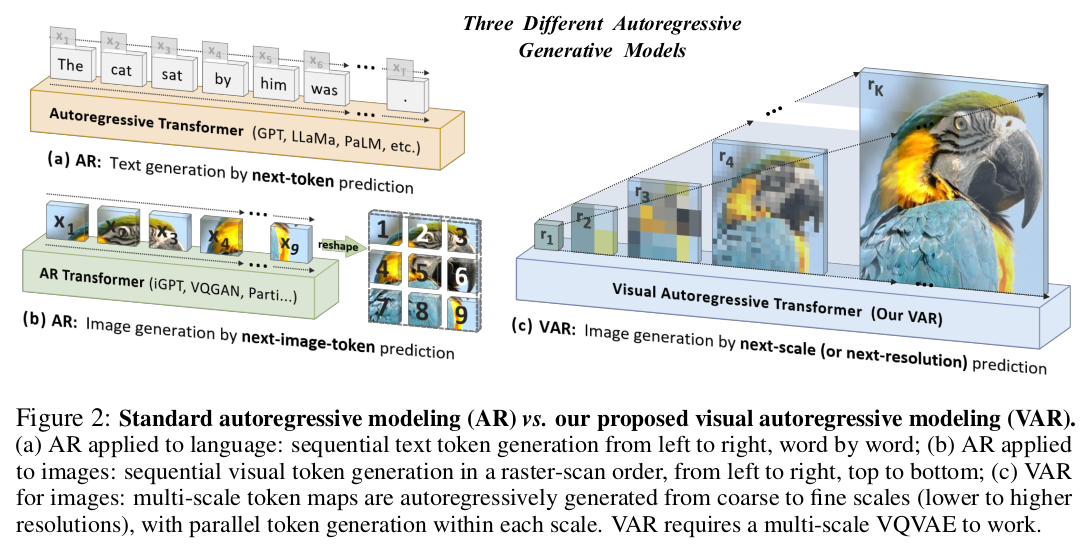 |
AR 모델은 쉽게 말하면 GPT 구조인데 이전 정보로 다음 올 내용을 예측하는 구조다. (a) 이를 그대로 이미지에 이식한 것이 (b)인데 token을 가로 줄 방향으로 펼쳐서 그대로 똑같은 방식으로 예측하는 방식 |
  |
근데 이렇게 하면 문제가 3가지가 두드러진다. 1) 이전 정보로 미래 정보를 예측한다는 컨셉인데 image token을 만드는 과정에서 Conv가 끼기 때문에 어쩔수 없이 전후좌우 (이미지 입장에선 미래 정보)가 섞일 수 밖에 없다. -> 컨셉에 안맞는다. bidirectional input에서 시작할 수 밖에 없음 2) 이전 정보로 미래정보를 예측한다는 컨셉을 지키도록 한다 해도 본질적으로 이렇게 이미지를 가로로 펼치는 방식으로 하면 이미지 하단이 미래, 이미지 상단이 이전이 되므로 상단->하단으로 가는 생성밖에 못한다. -> 이미지 상단을 inpainting한다고 하면 불가능함 -> 구조적으로 문제 3) 2D를 1D로 만들면서 attention 량이 엄청 늘어나 버림. 메모리/연산량 소모가 너무 크다. |
 |
그래서 제안하는 컨셉이 이미지를 정해진 patch size로 토큰화 하는 것이 아니라 여러 scale patch로 토큰화 한다음, 작은 토큰이 이전 큰 토큰이 미래 라고 가정하고 coarse-to-fine autoregressive하게 푼다. 한 마디로 패러다임 쉬프트. (아주 좋은 듯) |
 |
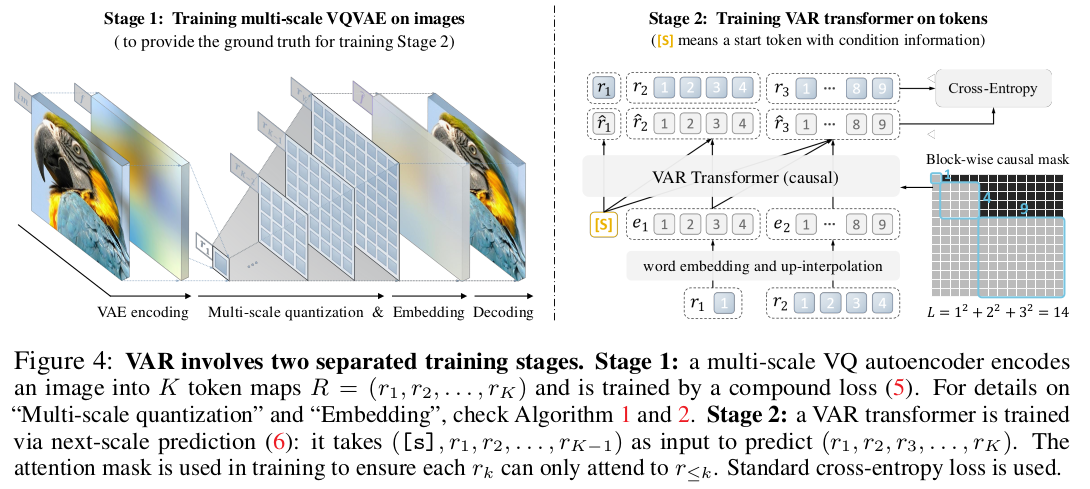
들어가기 전 배경지식 중 필요한 것은 구현할 때 image feature (token feature)를 VQGAN 처럼 vocabulary feature를 만들고 시작했다는 점. 이렇게 한 이유는, AR 모델은 이렇게 구성하는 것이 정석이라고 많은 논문들로 증명됐음. 따라서 그 컨셉을 그대로 물려 받기 위해 voca를 구성한 것. |
 |
수식으로 적으면 가장 해상도가 낮은 coarse token을 입력으로 그보다 하나 더 해상도가 높아진 fine token을 예측하고, 이 둘이 또 입력으로 들어가서 그 다음. 그다음 해상도를 예측하는 방식이다. 여기서 K를 높일수록 고해상도로 학습 됨. --- block wise causal mask는 attention을 가할 때 이전 token은 masked out되고, 미래 token과만 연산되도록 하는 mask임 attention 마스크가 NxN인데 이중 일부가 0으로 되어있다고 생각하면 됨. weight matrix에 곱해버리면 순식간에 모든 attention이 masking됨. |
  |
각 해상도의 픽셀은 voca 내 nearest feature로 채워진다. 모든 해상도에게 voca는 공유된다. |
 |
|
| image feature를 맨처음 CNN으로 뽑고 bilinear interpolation으로 해상도를 낮춘다음 nearest voca 찾음. decoding할때는 bilinear upsampling만 하면 성능이 구림. CNN을 조금 붙여서 upsampling에 복원력을 조금 더 추가 |
 |
voca는 4096개 GPT2 구조에 VQGAN 사용 |
 |
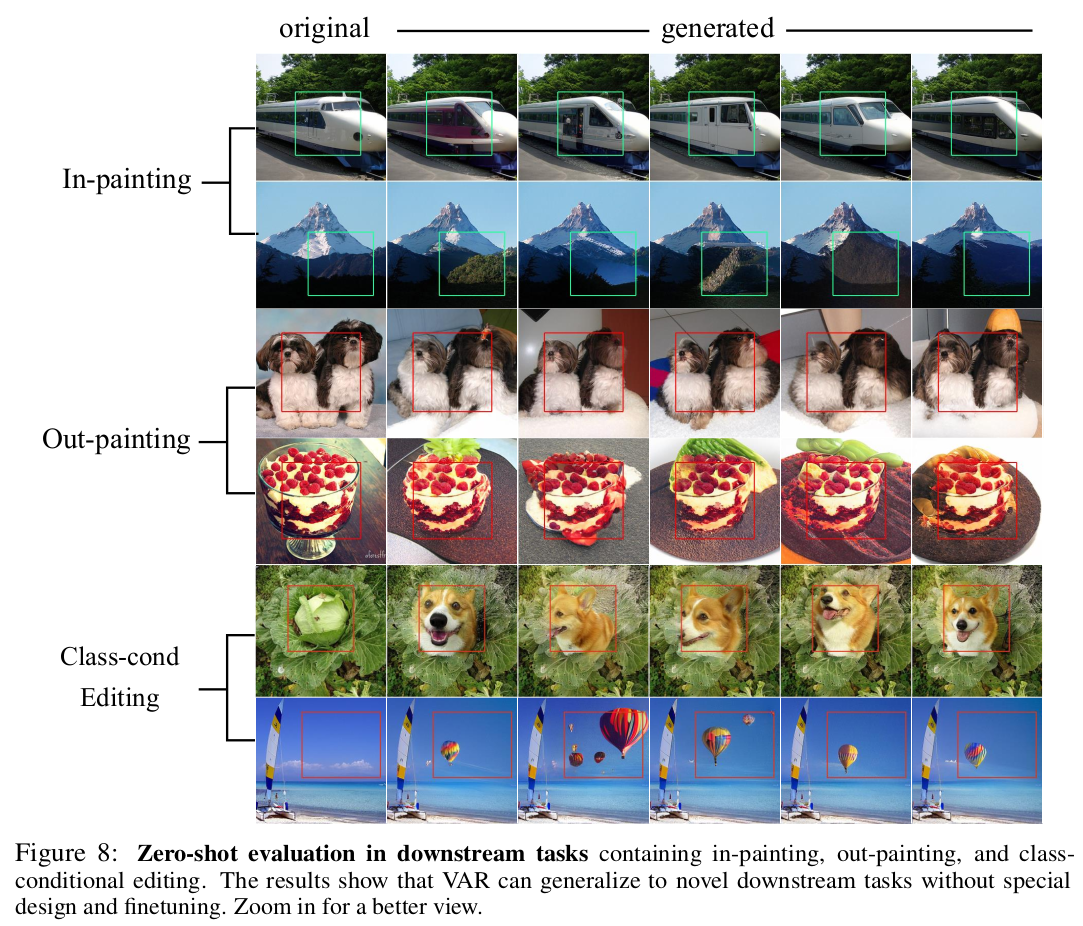  |
반응형