반응형
내 맘대로 Introduction

이 논문 역시 Adobe에서 낸 것인데 인턴 기간 중 작성된 것으로, 아직 어디 publish된 것 같진 않다. 내용 측면에서 GS-LRM의 힘을 크게 받았고, 입력 단의 multiview human image를 잘 생성하는 diffusion model을 만들었다 정도에 머물러서 이 역시 technical report에 가까운 느낌이다. 하지만 역시나 완성도는 매우 높아보인다. GS-LRM이 대단하긴하구나.
일단 Adobe의 synthetic은 더 이상 synthetic이라고 안 봐도 될 것 같다. 퀄리티가 확실히 다르다. 데이터가 최고구나.
메모
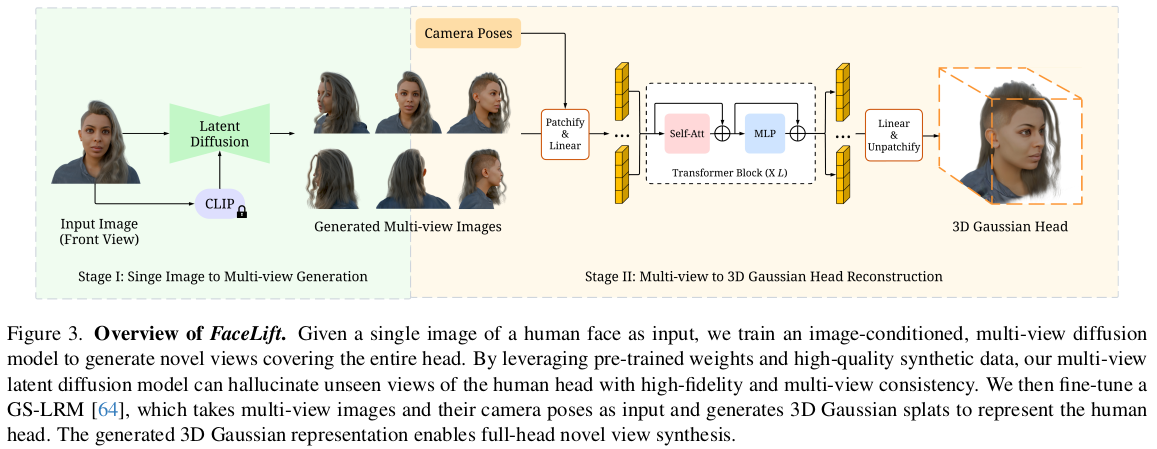 우측 그림은 GS-LRM이다. |
|
  |
아예 적고 시작한다. SD Tuning + GS-LRM이라고. 인턴 기간이 매우 짧았을텐데, 그 기간 동안 논문까지는 아니더라도 이 정도 완성도의 뭔가를 만들어냈다는게 대단하다. 논문이 뭐 대수냐. 이런 완성도 있는 걸 만들어 내는게 더 중요하지. |
 |
데이터셋은 디자이너가 직접 제작한 3D Head asset 200개고 각각 스타일링을 다르게 해서 50배 뻥튀기했다. 그리고 Blender 상에서 빡세게 렌더링. 32개 뷰를 학습에서 사용했다고 한다. 정해진 값은 아니고 동시에 사용한 것일 뿐. 사실상 무한 시점. ----- 근데 512 512 해상도를 32장이나 먹고 이걸 attention으로 처리하는 GS-LRM은 얼마나 크다는 거냐.... 메모리를 얼마나 쓴겨...  |
  |
SD V2-1-unCLIP 가져와서 튜닝 시작 multiview attention 뗘와서 장착 학습은 무한 시점 데이터로 학습 생성은 전면부를 45도 간격으로 생성 뒤통수는 90도 간격으로 생성 아무래도 얼굴이 중요하니까 전면부에 이미지 생성을 더두고 뒤에 GS-LRM 도 얼굴에 집중할 수 있게 한 듯. |
  |
여긴 뭐 그냥 GS-LRM recap이다. 변형 없음 objaverse에 사전 학습된 GS-LRM을 사람 데이터만 먹여서 한 번 튜닝했다. 디테일은 역시 ....감춰져 있겠지. |
 |
 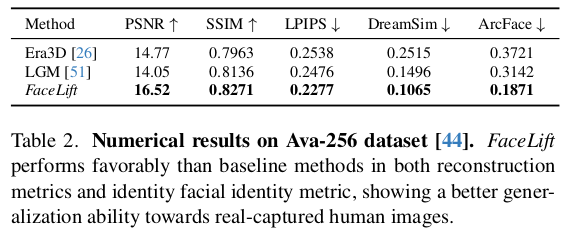 그러면 짜잔하고 이런 다른 MV- GEN 생성을 압도하는 결과물이 나온다. PSNR같은게 높을 수 밖에 없는게 다른 애들은 mesh로 나오고, 얘는 GS로 나오기 때문에 성공만 한다면 평가에서 유리할 수 밖에 없음. |
 |
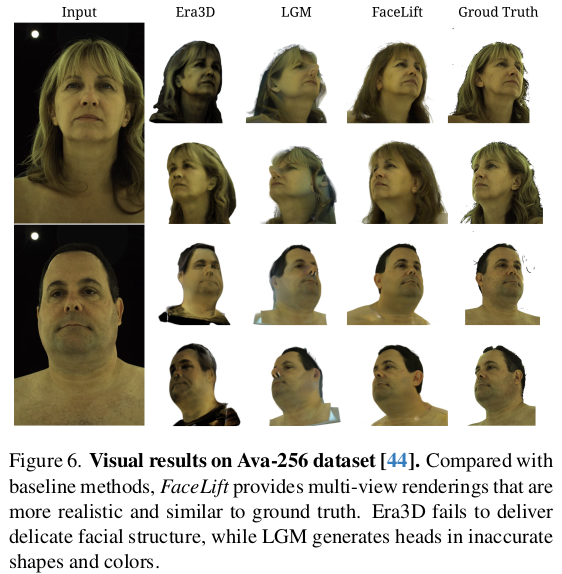 |
 |
 |
 |
 |
 전면부에 +-45도를 더 둔이유가 이게 아닐까. |
 와....finetune 없어도 GS-LRM이 아예 잘되는구나.. 대단하다. |
반응형