반응형
내 맘대로 Introduction

요근래 3DGS + 3DGAN을 합친 논문들이 눈에 띄던 중 하나의 궁금증이 생겼었다. DINOv2 같이 좋은 feature extractor를 generator 쪽 말고 discriminator 쪽에도 쓰면 더 좋아지나? 생각해냈을 때 오... 그럴 듯한데? 라고 생각하고 곧장 논문 거리인가 뒤져보았는데 역시 있었다. 이 논문과 다음 포스팅으로 정리할 TIGER라는 논문 2개가 대표적으로 최근에 나와 같은 고민을 한 듯하다. 어찌 보면 삽질 시작하기 전에 미리 확인해준 사람들이 있어서 다행인 것 같다.
핵심 내용은 discriminator에 pretrained backbone을 추가했을 때 GAN 학습 양상이 어떻게 변화하는지 관찰하는 것이다. 결론부터 말하면 이 논문에서는 학습 속도 즉, 수렴 속도와 성능을 위주로 비교했다. 제일 궁금한 것은 그 어려운 GAN 학습 안정성 확보가 쉬워지냐 어려워지냐인데 그것에 대한 비교가 없어 아쉽다.
generator의 구조가 바뀌어도 잘 동작한다는 점에서 어느 정도 학습 안정성이 증가한다고 볼 수도 있겠으나, 다른 GAN에서 가져온 generator 구조여서 이미 검증된 것들만 실험한 것이 아쉽다. 그냥 아무거나 갖다 붙여도 학습이 되는지가 궁금.
메모
 |
결론부터 던지는데 안정성, 수렴속도, 디장니 초이스가 증가한다는 결론. |
   |
핵심 가정은 foundation model이 갖고 있는 feature extraction 능력은 discriminator 라고 반갑지 않을리 없다는 것. 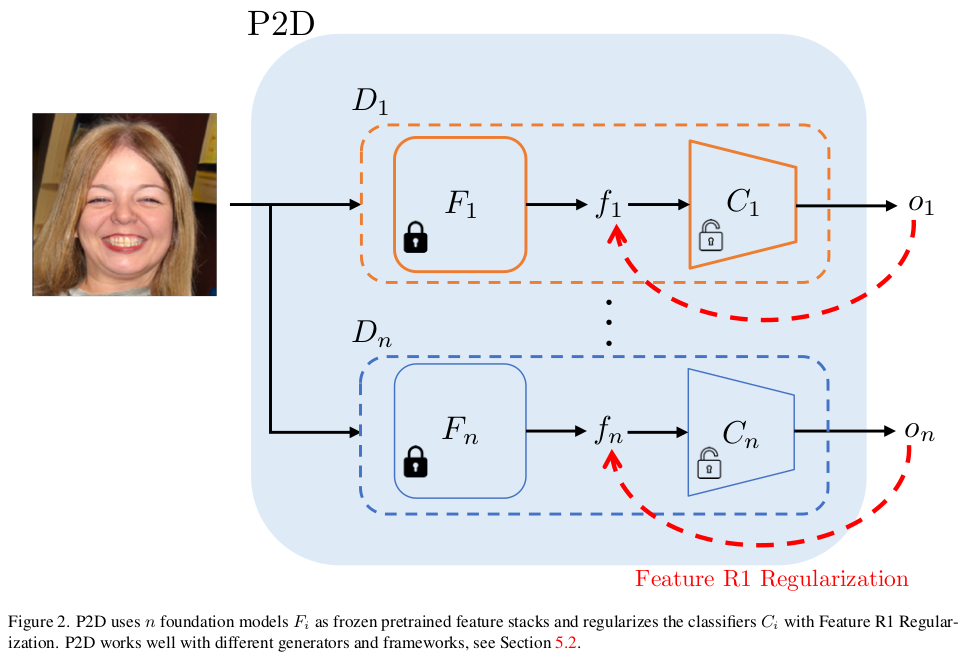 discriminator 안에 이런 식으로 multiple foundation model을 넣어두고 그 feature를 갖고 discrimination하는 구조로 변경해서 그 효과를 관찰해본다. |
 |
안정적인 학습을 위해 GAN 분야에서 국룰인 R1 regularzation. discriminator에서 발생하는 gradient의 크기를 억제해서 discriminator가 날뛰는 것을 막는 작용인데 fronzen foundation model이 중간에 박혀있으므로 이미지에 대한 gradient가 아닌 feature에 대한 gradient로 바꿔서 사용했다는 점이 차이. |
 |
여기서 N개의 discriminator를 동시에 쓰는 설정이기 때문에 각각 discriminator weighting을 해줘야 한다. 이걸 D마다 할당된 pretrained model feature의 norm을 보고 설정해줬다고 함. 단순한 걸 인정했는지 본인들도 heuristic이라고 했다. |
 loss는 참고만 |
 이 부분이 논문의 신빙성을 조금 떨어뜨리는데, discriminator의 효과를 관찰하는데 검증된 논문들의 generator 구조만 가져오는 것 뿐만 아니라 pretrained generator weight도 일부 가져와서 썼다는 것이다. 이렇게 되면 뭐가 뭐 때문에 좋아졌는지 모를텐데 왜 이렇게 했을까. |
 |
 |
 |
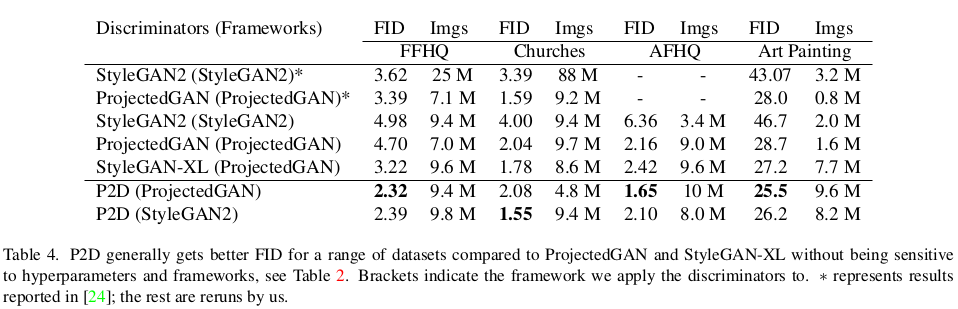
| 성능은 결국 좋아진다는 결론인데, 내가 볼 때 유의미한 분석은 수렴 속도는 확실히 빨라진다는 것. 역시 의미가 있다. |
반응형