반응형
내 맘대로 Introduction

이 논문도 Meta 에서 나온 논문인데 query point 위치를 주어진 video sequence 내내 tracking 하는 논문. arbitrary 2D point 입력을 받을 수 있는 구조인데 transformer로 구현되어 있어서 사실 상 N개의 지정 위치를 동시에 tracking할 수 있다. 사용해본 결과, 성능이 엄청 좋고 학습 시에 사용한 synthetic dataset이 사람과 동물을 다수 포함하고 있기 때문에 지형, 지물 뿐만 아니라 사람도 잘한다. close-up face도 잘됨.
query point feature를 처음 첫 프레임에서 뽑아서 learnable로 계속 열어두고, 각 프레임마다 query point feature + 현재 예측 상태의 point feature를 transformer로 decoding해서 계속 track point를 업데이트하는 방식. 어찌 보면 심플하지만 완성도가 높다.
메모
|
|
|
P가 이미지 2D query point (track 하고 싶은 점. 사용자가 지정.) 이후 t+1에서의 P 위치를 delta P를 예측하면서 계속 업데이트 해나감. |
|
일단 시작은 각 이미지를 CNN으로 feature화 함 feature pyramid 형태로 만듦. |
|
tracked feature라고 query point 개수만큼 learable feature를 만들어 둚. - 그냥 image feature에서 grid-sample해서 쓸 수도 있지만 그러면 첫 프레임에 bias가 걸리니까. point feature마다 지속적으로 업데이트되고 수렴할 수 있도록 learnable로 열어두는 방식. 초기화를 첫 프레임에서 grid-sample 하는 것으로 함. |
|
image feature, track feature가 준비완료 되었고, transformer 입력은 grid-sample(image feuatre) <-> track feature간의 correlation을 만든다. correlation 계산 시 patch 단위로 해서 receptive field 넓게 봄 + feature pyramid 각 scale마다 다 concat |
|
최종적으로 1. 첫프레임과 T프레임 간 point residual 2. confidence 3. track feature 4. spatial correlation feature 5. pos_emb(1.) 6. 첫프레임 point 7. 현 프레임 id t 이렇게 7개를 concat한게 token이 돼서 trasnformer 입력으로 들어감 -- 출력은 첫프레임 -> T프레임으로 변화하는 residual들. ---- 독특하게 confidence는 residual 더하는 식으로업데이트되게 하지 않았고 그냥 마지막에 한번 딱 예측하도록 했다 -> 이게 cotracker3에서는 다시 업데이트되도록 해놔가지고 그냥 큰 의미는 없는 듯. |
 |
|
  |
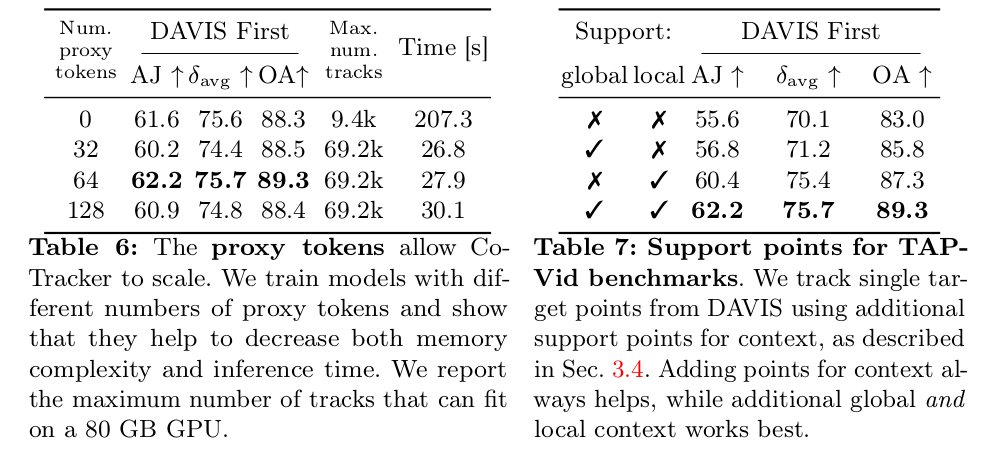
근데 이게 time dimension도 있고, correlation 때문에 spatial dimension도 있고 query point 끼리 self-attention 때문에 point dimension까지 있는 상태라 attention weight dimension이 무지막지 하다. 거의 학습 불가능 이를 해결하기 위해서 attention을 dimension별로 따로따로 처리하는 attention으로 구현해서 복잡도를 낮춤. -------- 추가적으로 point N은 엄청 큰 값이 들어오기 때문에 약간의 dimension reduction 느낌으로 proxy token이라는 걸 만들고 얘랑 cross attention한 값을 사용했다. N -> K proxy token dimension으로 주는 효과. |
  |
학습은 당연히 비디오로 하는데 (GT가 있는 synthetic video) 메모리의 한계 상 T 프레임씩 끊어서 학습을 해야만 함. 이 때 전체 길이 T' 을 T단위로 나눈다음 그룹 0학습은 그대로 하고, 그룹1 학습할 때는 그룹0 최종 결과를 초기값으로 쓰는 방식으로 꼬리 물도록 디자인해서 학습했다고 함. --- loss는 transformer가 M번 반복 해서 attention할 텐데, 초반에 loss weight를 크게 주고 후반에는 낮춰서 처음부터 잘맞추도록 scale다운 해주고 L2 loss로 계산함. |
  |
학습 때 query point는 데이터셋을 따르거나, 별도의 feature point extractor로 써서 학습하면 되지만 실제 사용할 때는 사용자 입력을 받으면 됨. 단 사용자 입력이 너무 작으면 학습 때 보던 개수랑 차이가 너무 심해서 성능이 조금 떨어짐 -> 이를 보상하기위해서 이미지 전체에 regular point + 사용자 입력 point 주변에서 local point들을 임의로 자동 추가해서 쪽수를 맞춰주고 inference했다고 함. |
  |
   |
반응형