반응형
내 맘대로 Introduction

Masked autoencoder가 ViT의 pre-train 기법으로 자리매김하는 와중에, 똑같은 방법론이 CNN에는 적용될 수 없을까 고민한 논문. Computation resource 때문에 CNN을 써야만 하는 상황에서 확실한 방법론이 있다면 꽤 유용할 것 같다는 생각이다.
핵심은 Masked autoencoding 컨셉은 그대로 가져오되, convolution kernel이 masked region에서는 feature를 뽑지 않도록 sparse convolution으로 억제하는 방식을 적용한 것이다. 커널이 masked region을 처리하는 순간 feature extraction을 방해할 뿐만 아니라, layer를 거듭할 수록 그 효과가 점점 확산되기 때문에 단순히 masking만 하는 방식이 CNN에서는 안 먹혔던 것. sparse convolution이라는 개념을 여기다 갖다 붙여서 커널이 오로지 visible region에서만 feature를 뽑도록 했다.
메모
 |
|
  |
컨셉을 똑같다. unlabeled image에 masking를 랜덤하게 씌우고 decoder가 이 영역을 복원하도록 하는 작업을 반복하는 것. 다만 CNN은 convolution kernel이 mask region에서도 값을 뽑을 수 밖에 없기 때문에 (transformer는 attention이 알아서 걸러내지만) mask region이 visible regino과 완벽히 구분되지 못한다는 문제가 있음 (연산이 불필요하게 masked region에서도 유지된다는 부수적인 문제도 있음) --- 이를 해결하기 위해서 mask region pixel의 id를 저장해둔 뒤, kernel이 씌워질 때 해당 id인 pixel 값은 무시되도록 처리하는 기존 sparse convolution을 사용했다. -> 다시 말해 기본 convolution을 masked region을 무시하는 sparse convolution으로 교체하기만 하고 그대로 MAE 처럼 학습하면 된다는 말. |
 |
|
 |
구조는 pyramid 구조로 정하고 예시를 보여줌. ->기존 CNN은 pyramid 구조를 가져가는게 기본이기 때문에 모든 CNN 구조에 사용 가능하다는 점을 암시적으로 보여줌. |
 |
decoder에서 복원할 떄는 masked region에 각 level 별 mask embedding 채워준 뒤 복원함. |
 |
loss는 masked region에서만 L2 loss |
 |
 |
 |
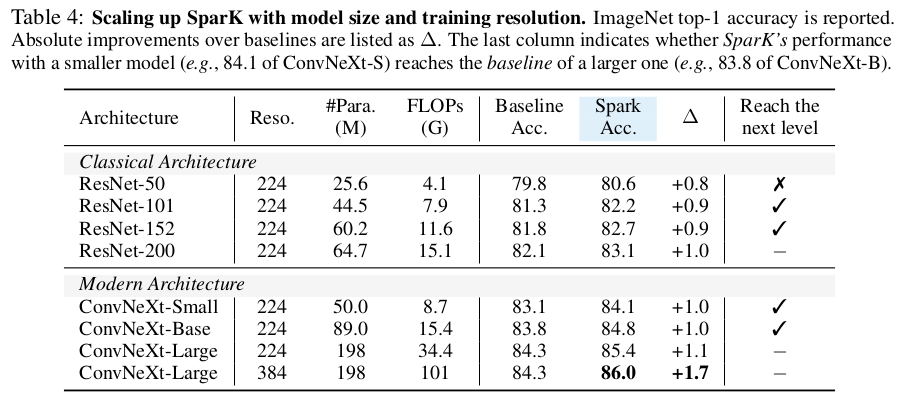 |
 |
 |
반응형