반응형
내 맘대로 Introduction
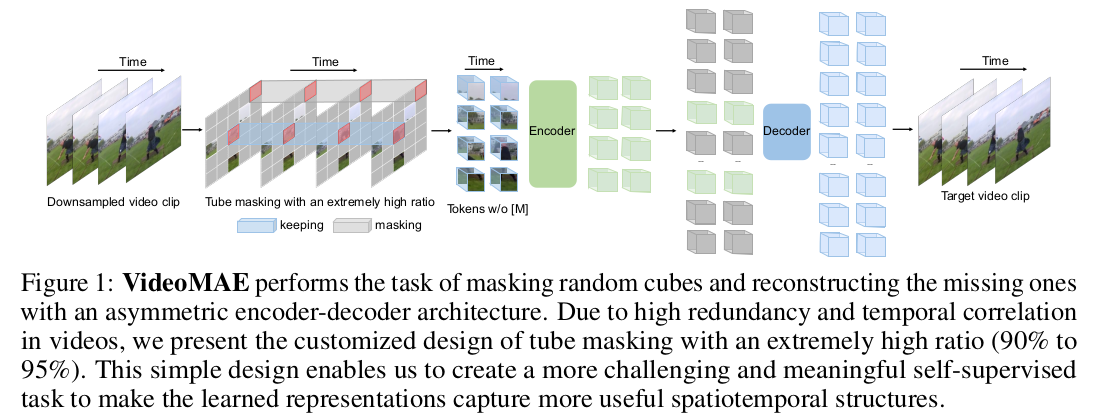
SSL 방법의 인기가 올라가는 시기에 video 데이터에 적용 가능한 masked auto encoding 기법을 고민한 내용이다. 사실 특별하다기 보다 직관적으로 떠올렸을 때 이렇게 하면 될 것 같다... 싶은 방식대로 한 방식이라서 누구보다 빠르게 선점한게 눈에 띈다.
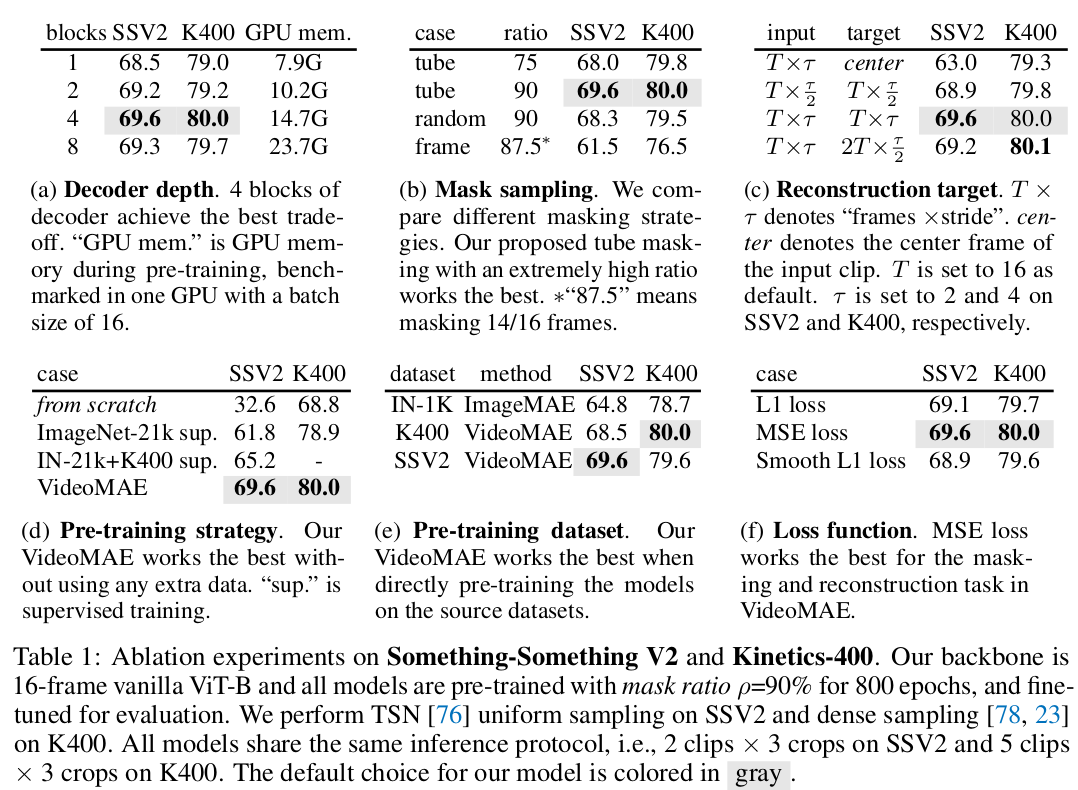
핵심 아이디어는 t frames을 쌓은 뒤, 같은 위치의 이미지 patch를 masking 하고, token화 할 때도 같은 위치 이미지 patch끼리 쌓아서 사용한 점이다. 인접 프레임의 다른 patch를 보고 복붙하듯이 학습될 여지가 더 많으므로 masking ratio를 90%까지 올리는 것이 효과가 좋았다고 발견한 것도 약간의 포인트다.
메모
 |
비디오 인접 프레임을 쌓는 방식은 masking한다 한들 인접 프레임 다른 patch를 복붙해서 배울 여지가 너무 크므로 조금 더 섬세한 설계가 필요하다고 한다. 움직임에 대한 prior를 배운다고 해서 인접 프레임 간의 모션은 작기 때문에 의미있는 수준으로 배우진 못할 것. (뭔가가 더 필요하다.) -> high masking ratio 라는 답변인데, 이게 앞선 지적의 모든 점을 해결하는 파훼법인지는 모르겠다. |
 |
|
   |
사실 내용은 별거 없다. 글을 다 읽어보지 않아도 대충 알겠는 내용이라서 대충 기록한다. time 축에 따라서 같은 위치의 patch를 묶고 token화 한다. 이 time도 조금 나누어서 T/2 크기로 token화 한다. + high masking 90%로 학습. -------- 놀랍게도 이게 내용 끝이다. |
 |
 |
 |
v2도 곧 공개되었었는데, decoder에도 masking을 추가했다는 점이 다르다. 이유는 학습 때 쓰이는 메모리가 너무 크기 때문이다. MAE 학습해보면 알겠지만 224x224 해상도를 patch 사이즈 16으로만 해도 메모리를 장난 아니게 먹는다. video 입력으로 확장할 때는 아무리 masking을 많이 한다고해도 부족했을 것. 그 점을 개선하기 위해서 학습 단계에서 decoder에 까지 마스킹하는 방식을 제안했다. |
 |
||
| 약간의 차이를 두기 위해 마스킹하는 방식을 decoder에는 다르게 적용했는데 running cell masking이라고 위 그림처럼 직전 frame에서 masking했던 위치를 shift하면서 마스킹하는 방식이다. action recognition 쪽에서 나온 방식 |
 |
| 전체적인 성능이 향상된 결과를 보이는데, 모델 크기와 데이터 크기를 같이 키운 뒤의 결과이기 때문에 필연적인 결과라고 볼 수도 있겠다. decoder masking 추가의 결과라고 보기엔 살짝... |
반응형