반응형
내 맘대로 Introduction

Cotracker를 갈고 닦아서 버전 3까지 만들었다. 핵심 내용이나 구조는 거의 동일하고, 학습 방법론 + unlabeled data 추가가 관건. 요즘 이런 실험적인 성능 향상도 contribution으로 인정 받아 논문화되는 경우가 많은 것 같다.
메모
  |
Cotracker랑 거의 동일하나 track feature라고 불리던 Q를 과감히 없애버림. 단순히 image feature + correlation feature 만으로 해결함 -> 실험적으로 이렇게 해도 성능 달성이 되었기 때문에 뺀 듯. |
 |
학습할 때, 1. 일단 1개 학습해둠. 2. 이걸로 pseudo labelling을 엄청 함 3. 통합해서 다시 학습함 이 과정을 반복하는 식으로 unlabel 데이터를 활용했다. 이 때 pseudo label을 생성하는 모델을 A,B,C,D...등 여러개 둬서 마지막에 학습하는 애들은 모든 teacher를 보고 배우게 만듦. ---- 핵심 전제가 이미 teacher도 완성급으로 잘된다는 것. |
 |
데이터셋은 100k개 비디오 30초 짜리를 모아서 pseudo label만들어서 사용함 앞선 synthetic 데이터는 당연히 사용 -------- teacher model은 cotracker1, 3 ,TAPIR 3개 썼다. |
 |
학습 때 query point는 synthetic이라면 있겠지만 in-the-wild video면 마땅한 query point 샘플링 규칙이 없다. SIFT 써서 생성해서 학습함. -> 이게 장점이 도드라지는 point 위주로 뽑아주니까 얼추 주요 point를 추리는 것 뿐만 아니라 -> 대략 video 가 쓸만 한지 아닌지 그 개수로 파악할 수 있는 힌트를 줌. |
 |
|
  |
전체 구조는 cotracker1이랑 거의 같고 track feature Q가 사라진 대신 image feature + correlation feature를 단순히 concat하고 끝나는게 아니라 MLP로 한번 aggregation하는 layer가 추가됐다. -> 다시 말해서 track feature에 담았던 query point feature를 즉석에서 MLP가 뽑아내주도록 학습한 방식 -> learnable NxD feature가 사라진거라서 연산량이 많이 줄어든다. 메모리도 그렇고. |
 |
첫프레임 image feature에서 patch sampling T 프레임 image feature에서 patch sampling correlation 계산 (dimension 엄청 커짐) MLP로 aggregation (dimension reduction) |
  |
input token도 많이 단순화 됨 cotracker 1에서는 넣을 수 있는 걸 다 넣어서 현위치, residual, 현위치를 pos_emb한 것, track feature 등등 되게 길었는데 여기서 거두절미하고 t-1 -> t t - > t+1 point residual만 pos-emb correlation feature, confidence, visibility 끝이다. visibility가 추가된 것도 하나 포인트 여기서 cotracker1이랑 다르게 confidence visiblity도 iterative update로 만들어두었다. (다시 회귀한것) |
 |
loss는 완전 동일 occlusion (visiblity가 너무 낮을 경우)만 처리해줌. |
 |
하나 팁은 teacher를 만들려고 학습을 처음할 때 confidence, visiblity는 딱히 학습 안했다고 한다. -> C, V는 student가 스스로 배우는 것 |
 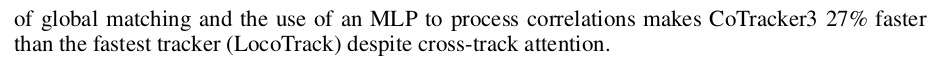 |
잘라낼 것을 많이 잘라내면서도 in-the-wild 데이터로 성능을 끌어올려서 속도만 27퍼센트나 빠라진 결과. |
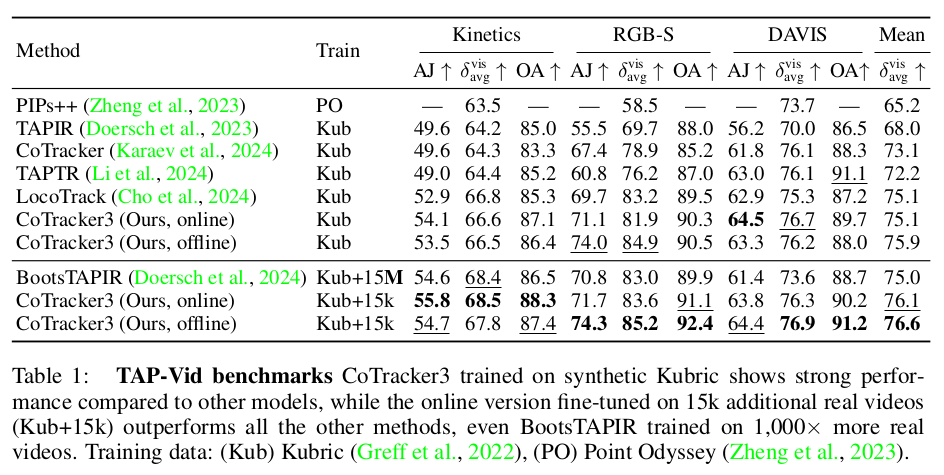  |
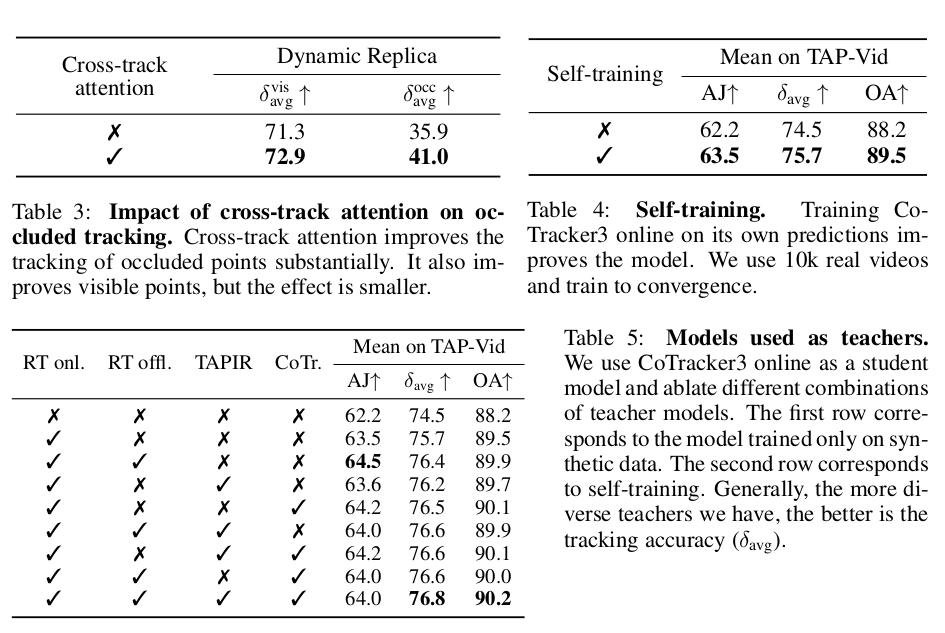  |
반응형