반응형
내 맘대로 Introduction

이 논문은 MAE의 많은 후속 연구와 같이 어떻게 하면 self-supervised learning을 효과적으로 이미지에 적용할 수 있을지 고민한 논문이다. 여느 논문들과 달리 MAE를 연구한 그룹에서 낸 후속 연구격이라 신뢰도가 높다. 저자에 LeCun이 들어있는 것도 한 몫한다.
많은 데이터를 사용하는 학습이고 모델이 transformer다 보니 연산량도 작지 않기 때문에, 성능 뿐만 아니라 학습에 걸리는 시간도 문제인데 이 두 가지 문제를 해결하고자 한 듯하다.
핵심 아이디어는 어찌 보면 간단하다. 1) random masking 대신 patch masking을 하고 patch 단위로 비교 2) 비교할 때 복원한 이미지 상의 pixel loss가 아닌 feature level에서 loss를 사용한 점. 보이는 영역의 정보를 활요에 "어디에, 뭐가" 있는지 집중하기 좋은 patch masking. pixel level에서 비교하면 불필요한 정보까지도 복원해야 하기 때문에 난이도가 높은데 그보다 semantic level인 feature space에서 loss를 걸어줆으로써 효율을 쓸어올린다.
메모
 |
|
  |
self supervised learning에 사용되는 여러 컨셉을 비교한다. 먼저 (a), 이미지 A와 B를 각각 encoder로 feature화 하고 이를 feature level에서 비교하는 것. -> trivial feature (논문에서는 flat)으로 수렴해버리는 collapse가 잘 일어나는 단점이 있다. |
 이건 MAE와 같이 이미지 A를 encoding-decoding 한 결과를 이미지 B와 pixel level에서 비교하는 방식이다. 추가되는 z는 mask token이나 position embedding이 된다. -> 지금까지 가장 신뢰도 높게 사용되는 방식 |
 이 둘을 합친 방식, 이미지 A,B에 각각 encoder가 있고 A embedding을 masking 후 decoding된다. decoded feature A vs feature B. |
  그림을 되게 잘 그려서 이해가 쉬움. masking을 하고 복원할 target patch position embedding (z)를 더해준 다음 encoding 원본에서 target patch 부분 encoder한 것과 비교 이 때 context encoder과 target encoder는 완전히 별개의 network가 아니고 exponential moving average 방식으로 전파된 weight를 갖는 네트워크 -> DINO에서 쓴 컨셉이다. |
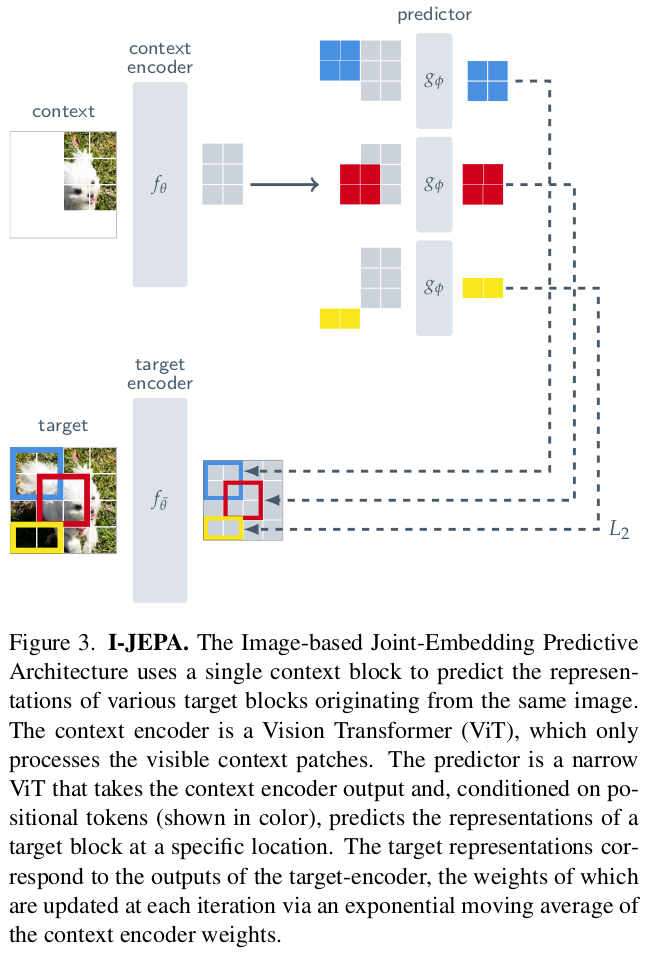 |
  |
target은 모든 pixel을 patch16화 하고 랜덤으로 선별한다. patch token 상에서 random size block으로 뗘와서 사용 |
 |
 |
  block 단위로 decoding해서 feature를 만들고 B feature와 비교 |
 loss는 역시 간단. 여기서 target encoder는 backprop으로 업데이트되는 방식이 아니다 보니 target feature는 stop gradient 상태다. EMA로 업데이트. |
 |
 |
 |
 |
 |
 |
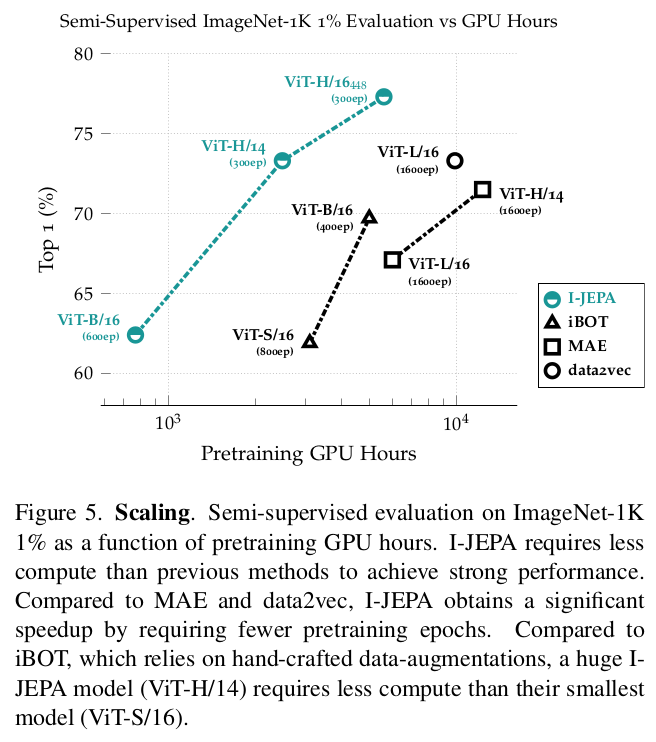 |
 |
 |
|
 |
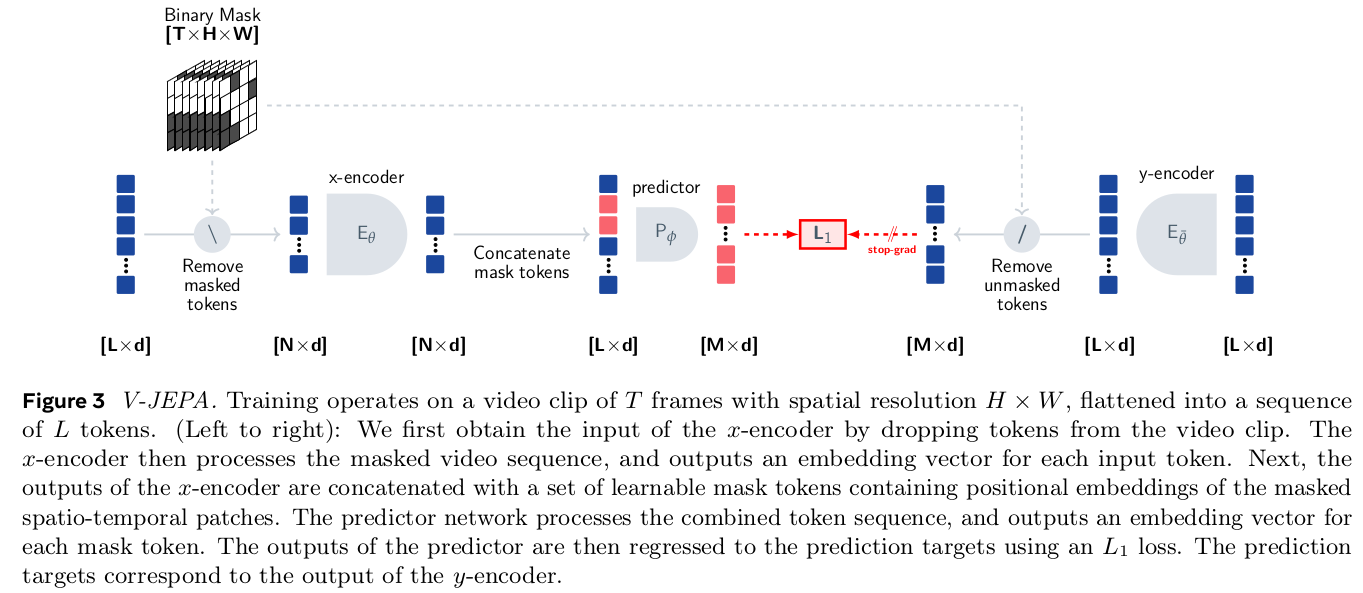
이를 video (time dimension)으로 확장한 논문도 하나 있는데 거의 다 비슷하다. 입력이 patch에서 cube가 됐다는 점과 loss가 l1 loss로 변했다는 점이다. |
 |
반응형