반응형
내 맘대로 Introduction

2020년 StyleFlow 에서 styleGAN latent space를 잘만 컨트롤하면 원하는 condition을 넣어 원하는 이미지를 생성할 수 있다는 가능성을 보여준 이후, 2021년 이 가능성을 aging condition으로 특화한 논문이다.
StyleFlow는 z->w 과정에서 condition을 주어 이미지를 생성하는 것이므로, 시작이 random gaussian noise다. 따라서 condition만 만족하고 나머지는 랜덤이다. 얼굴이나 스타일 안경, 이런건 랜덤 생성이다.
이 SAM 이라는 논문은 image->w로 가는 네트워크를 학습한다. 따라서 image + condition -> w를 학습해서 image 특성은 유지하되 condition이 추가된 이미지를 생성해내도록 했다. 여기서 condition은 age로 한정했고.
모든 GAN 논문이 latent z에서 시작했다가 image to z를 거치는 자연스러운 순서가 여기에서도 드러난다.
메모
 |
|
 |
핵심은 간단하고 나머지는 pre-trained network들을 갖다붙였다. 핵심은 styleflow에서 핵심으로 사용했던 Microsoft face api attribute, a와 이미지를 입력으로 받아 residual w를 찾아내는 Encoder를 학습하는 것 이 encoder다 image to w를 담당하는 본체 다만 scratch부터 학습하면 효율이 떨어지니 pixel2style2pixel encoder(이것도 비슷한 목적의 image to w 네트워크인데, 이 저자의 이전작임) 를 갖다붙인 후 residual을 계산하도록 했다. 생성된 이미지가 원하는 이미지가 맞는지 비교하면 되는데, 이때 GT가 없으므로, cyclir 하게 loss를 구성했다. -> 15 살 -> 85살 -> 15살 돌아왔을 때 제 이미지랑 동일한지 확인. |
  |
face attribute 중 나이만 사용했고 5~100살 범위 내에서만 사용했다. 이미지 뒤에 H, W 맞춰서 concat해줘서 HW4 형태로 입력되게. 수식(5)와 같이 생성 완료된 이미지에 직접 걸어줄 SUPERVISION이 없으므로 한번 더 입력 이미지 나이로 변환해서 CYCLIC 비교. 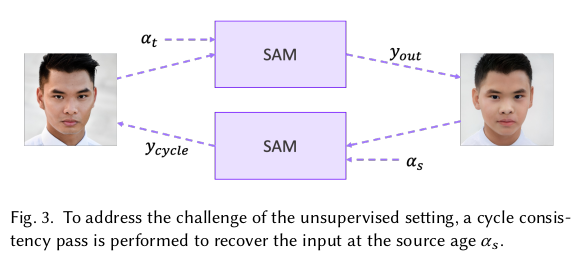 |
 |
네트워크 구조는 p2s2p 네트워크랑 거의 동일한 FPN 구조 CNN갖다 붙여서 사용함. |
  |
수식(7)은 좀 난해한데, 나이 변경 전 과 후 이미지 pixel 비교를 한다. 이건 identity 유지 강화를 위해 약간 perceptual한 loss인 듯 수식(8)은 perceptual loss. |
 |
identity 유지를 위해서 face recognition 네트워크 통과했을 때 feature가 비슷한지 loss face api 써서 생성된 이미지 나이 뽑아봤을 때, 생성에 사용된 나이랑 같은지 loss  |
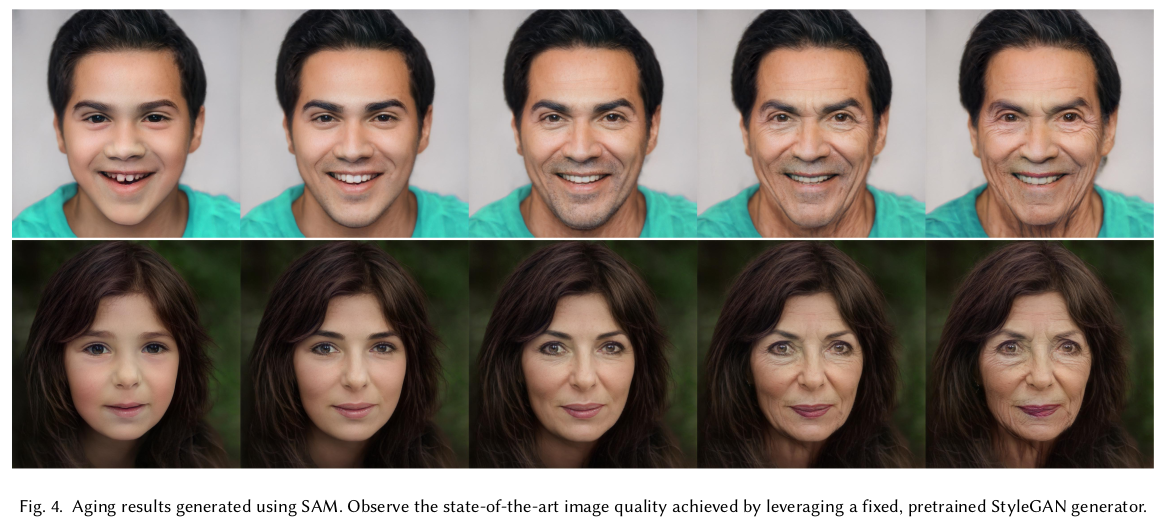  |
 |
 |
 |
 |
반응형