반응형
내 맘대로 Introduction

MeshAnything 코드를 뜯어보다가 이 논문의 encoder를 사용하는 것을 보고 읽어보았는데 아이디어가 좋은 것 같다. 다루는 문제는 image to mesh 혹은 text to mesh 문제인데 image/text latent에서 바로 mesh로 가는 방식 대신 중간 매개체로 3D shape latent를 구해놓는 것이 핵심이다. 또한 3D shape latent가 image/text latent와의 유사성을 유지하도록 강제함으로써 기존 방대한 양으로 구해둔 image/text prior도 취할 수 있도록 했다.
image/text보다 mesh에 더 가까운 차원인 3D shape latent로부터 diffusion해서 mesh를 만들기 때문에 divide-and-conquer 전략 느낌으로 각개격파라서 성능이 좋다.
전체 구조는 VAE와 Diffusion인데, VAE가 3D point cloud로부터 3D shape latent space를 구축하고 mesh로 decoding하는 역할, diffusion은 noise로부터 3d shape latent를 생성해내는 역할이다. (최종적으로는 Diffusion + VAE decoder를 사용하는 구조)
메모
 |
|
 |
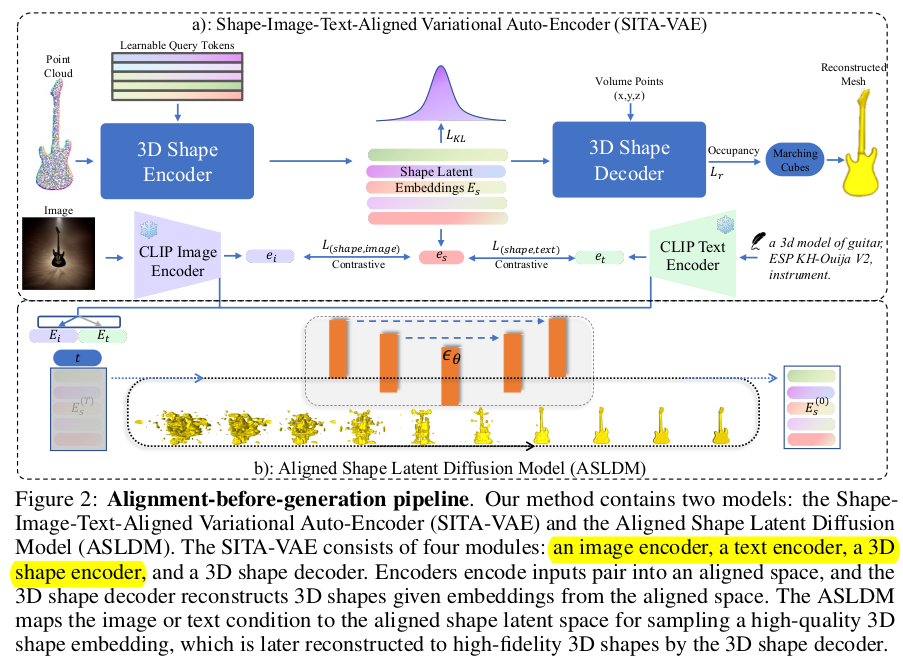
image/text 에서 mesh로 바로 가는 것을 지적하며 중간 3D shape latent를 만드는 방식을 소개 VAE로 3D shape latent space를 만든 뒤, Diffusion으로 3D shape latent sampling -> mesh 순서다. diffusion 시 image/text conditioned 3d shape latent generation이라서 전체 프레임워크는 image to mesh, text to mesh 그대로 유지하게 된다. |
  |
여기서 3D shape latent space 구축이 제일 중요한데, 단순히 point cloud 데이터만으로 학습시키면 데이터 규모가 작기 때문에 latent space 구축이 어렵다. image/text latent space의 힘을 빌리는 것이 현명함 따라서 3D shape latent 가 같은 대상의 렌더링 이미지에서 뽑아낸 CLIP latent와 유사하도록 강제했다. |
 |
뽑아낸 3D shape latent가 CLIP 과 비슷하도록 contrastive loss 걸어주기 |
 |
이것으로 끝나면 3d shape latent는 그냥 image/text latent를 흉내내는 하위 latent가 되어버리므로, 독자적으로 3D에 대한 정보를 더 들고 있도록 보강해줘야 됨. (image/text prior ++가 되도록) 그 방식을 3d shape latent를 갖고 SDF를 예측하는 decoder를 추가하는 것. 3d shape latent + xyz query로부터 mesh를 직접적으로 결정하는 SDF를 예측하도록 학습하면서 3D shape latent가 image/text latent를 닮아가되 본질인 3D 정보 함축도 할 수 있도록 유도함. |
  |
위와 같이 VAE를 학습시켜 3D shape latent space를 만들어두었지만, 입력이 3d point가 있어야만 하는 상황... mesh를 생성해내고 싶은데 point cloud가 있을리 만무하니 chicken and egg problem이 되어버렸다. ----------- 정답은 diffusion으로 3D shape latent 를 만들어내는 것이다. 3D point cloud 입력에서 만드는 것이 아니라 diffusion으로 무한히 생성해내는 식으로 문제를 풀었다. 이 과정에서 image/text condition을 받도록만 해주면 image to mesh, text to mesh가 바로 가능. |
  |
데이터셋은 shape net에서 5만개, 카툰몬스터에서 811개 구했다고 한다. mesh geometry는 바꿀 수 없지만 texture만 바꾸면 CLIP feature의 다양성을 더 확보할 수 있기 때문에 texture만 바꿔준다. ---------- controlnet으로 렌더링된 depth 이미지를 기반으로 texture 바뀐 이미지 찍어내는 방식. (요즘 이런 방식의 데이터 augmentation이 많이 보인다.) |
 |
|
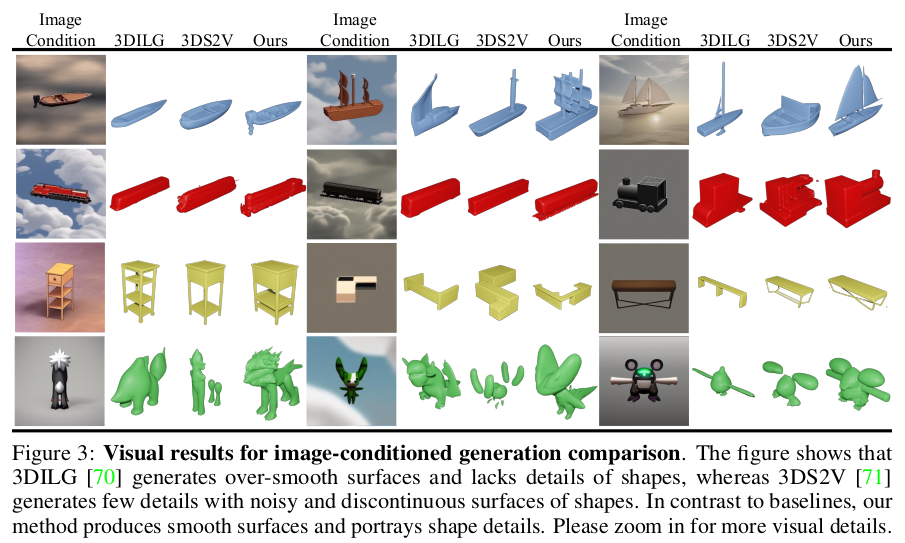 |
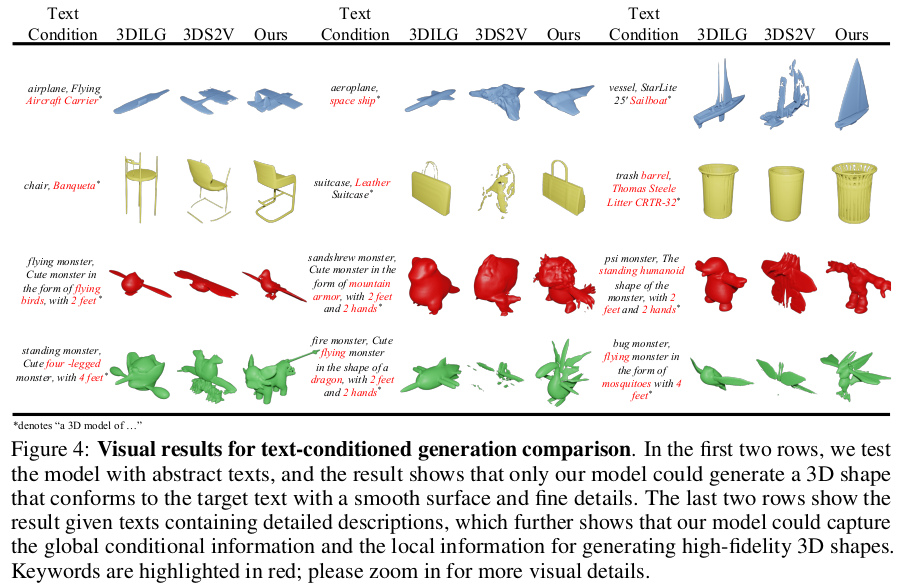 |
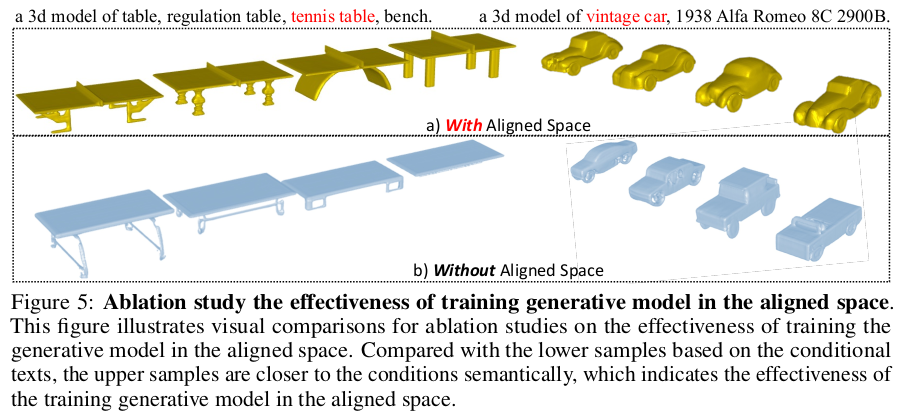 |
 |
 |
반응형