반응형
내 맘대로 Introduction

디즈니에서 만든 aging 네트워크 논문을 읽다가, 핵심 참조 논문이어서 여기까지 내려왔다.
이 논문은 2020년 논문으로 StyleGAN2가 폭발적인 인기를 얻던 시절, StyleGAN2 latent space를 해석하는 논문이다. 다른 말로, styleGAN2의 latent space에서 원하는 조건을 만족하는 latent를 찾아내고 결과적으로 원하는 이미지를 생성하도록 유도하는 방법을 설명한다. 마치 요즘 diffusion model에 IPAdapter나 controlnet을 붙여서 conditioned image generation을 하는 것과 같다. StyleGAN2 버전 condition 주는 방법이다.
핵심 아이디어는 pre-trained styleGAN의 latent z to intermediate latent w 관계를 interpretable하게 찾아주는 normalizing flow 네트워크를 학습하는 것이다. z->w, w->z 과정을 손쉽게 오고 갈 수 있도록 만드는 것인데, 이 과정에서 face attribute를 명시적으로 입력으로 넣어줌으로써 나중에 inference 시에 face attribute만 조절하면 z->w 로 이미지를 만들거나, w->z->w로 이미지를 만들어낼 수 있는 방식이다.
이제는 normalizing flow가 뭔지 어쩌구 저쩌구 이해하고, 그러기 보다 이런 식으로 condition을 주었었다 라고 컨셉만 이해하면 될 듯. 나도 대충 읽었다.
메모
 |
styleGAN에 컨디션을 넣는 방식은 다른 연구도 있지만, 얼굴에 한정에서 identity 변화나 불필요한 영역의 변화를 막기엔 조금 부족하다. 이건 generation 모델의 한계. 따라서 이 한계를 극복하기 위해서 latent를 찾아낼 때 정말 섬세하게 찾아낼 수 있도로 가이드하는 방법이 필요함. |
  |
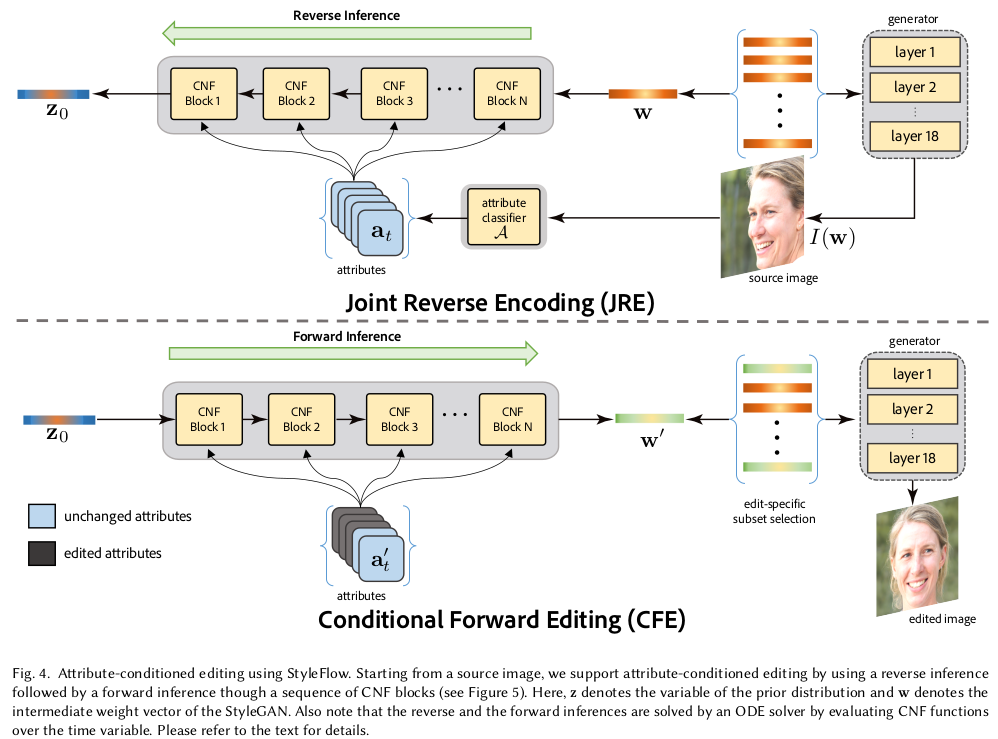
핵심 아이디어는 일단 시작이 되는 latent z (from normal distr.)와 이미지 생성을 직접 결정하는 latent w 간의 mapping 관계를 명확하게 파악하는 것이다. z가 어떻게 w가 되고, w가 어떻게 z가 되는지를 알아야, z를 원하는 방향으로 유도시켜 원하는 w로 만들 수 있기 때문 -------------- 이 때 normalizing flow 를 계산하는 것을 이용한다. normalizing flow는 쉽게 말하면 분포<->분포 간의 mapping을 표현하는 flow다. z->w 를 계산할 수 있는 mapping function이라고 볼 수 있는데, 장점은 z->w를 찾아둔다면 수식적으로 w->z로 계산할 수 있다는 것이다. z->w, w->z가 둘 다 된다는 것은 변환관계가 1 to 1 mapping된다는 것이므로 확률적인게 아니라 명확하게 표현된다는 의미. -------------- z -> w, w->z 과정에서 네트워크는 face attribute, a를 입력으로 굳이 받도록 설정을 해뒀는데 이렇게 해서 학습을 할 경우, 나중에 face attribute를 사람이 조절할 수 있게 되어 controlability가 생긴다. 사실 이 controlability를 얻기 위해서 z->w를 파악하는 것. |
   |
normalizing flow를 이해하기 위한 간략 설명은 다음과 같다. 먼저 discrete 으로 보면, 수식(3)과 같이 z->w는 mapping function의 gradient가 뒤에 따라부튼 형식으로 표현된다. 이 때 mapping function이 여러 layer로 구성된 function이라고 가정한다면 수식(4)와 같이 굳이 summation 형태로도 표현할 수 있다. -> 이건 왜 이렇게 하냐면 mapping function (=network)를 뒤에서 네트워크를 여러 layer 붙여서 설계하기 때문 MLP를 function에 대입해서 풀면 최종적으로 수식(6)과 같이 정리할 수 있다. MLP가 z->w를 표현하지만 이렇게 찾아내고 나면 w->z도 가능. |
 |
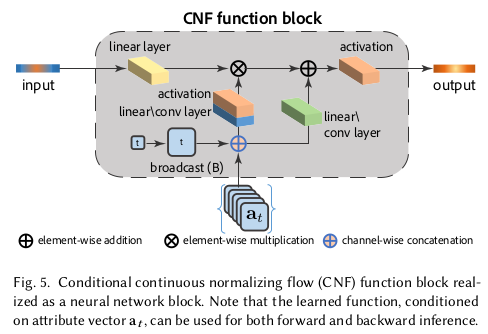
이를 continuous로 확장하면 수식 (7)과 같음. ------------ 여기서 CNF 쓴다고 하는데 명시적으로 time 개념이 없고 여기선 K 번 layer를 반복하는 것만 있기 때문에 사실상 DNF랑 큰 차이 없다. time step, dt를 얼마로 지정하느냐는 결국 K를 몇개로 지정할거나와 같은 이야기 일 것. 오히려 저 mapping function이 MLP가 아니라 conv layer가 조합된 복잡한 네트워크로 바꿔서 사용했다는 것이 더 차이점. |
  |
학습 데이터는 10000장, StyleGAN에서 막 생성해서 만듦 -> Microsoft Face API 사용해서 gender, pitch, yaw, eyeglasses, age, facial hair, expression, baldness를 숫자값으로 뽑아둠 |
 |
|
 |
   말이 어려운데, 위 그림처럼 z->w 왔다갔다 할 때 해당 이미지에서 추출한 face attribute를 concat해줬다. 모든 attribute를 concat해서 다 넣어주는게 더 성능 좋음. |
  |
 z->w forward 방식으로 batch 5, 10 epoch, 10000장 학습 z->w forward에 사용되는 mapping function이 MLP였다면 수식(6)으로 gradient 계산이 끝났겠지만 그림 5와 같이 뭐가 얽혀있기 때문에 gradient 계산이 빡셈 이건 ODE solver를 붙여서 따로 계산해서 사용했음. |
 |
|
 |
 |
  |
 |
 |
반응형