반응형
내 맘대로 Introduction

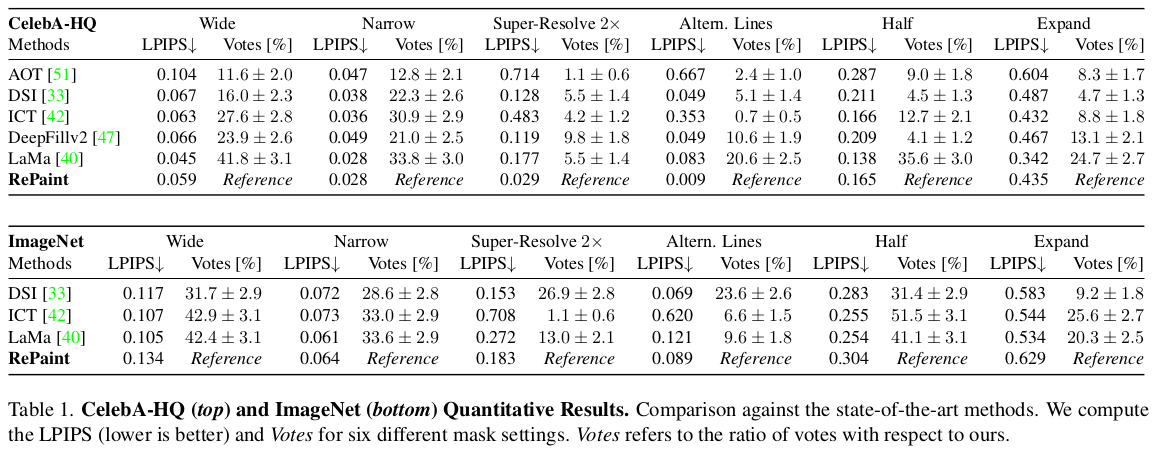
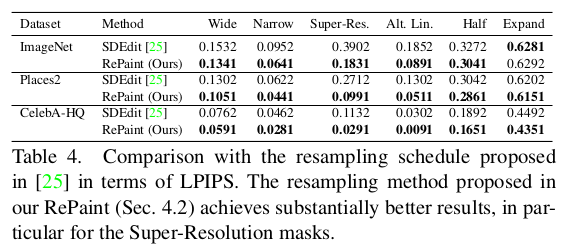
이 논문은 제목에서 바로 알 수 있다시피 DDPM 즉, diffusion model을 이용해서 이미지 inpainting하는 방법을 설명한다. 특이한 것은 별도의 튜닝이나 재학습, loss 추가 이런 것이 없다. 기존 학습 완료된 DDPM을 "어떻게 활용하면" 아무런 수정없이 inpainting 문제를 풀 수 있는지 아이디어를 설명하는 논문이다.간단하지만 효과적이고 납득 또한 가능한 방법.
inference 시간만 늘어나는 단점이 있다.
메모
  |
 위 그림이 직관적으로 바로 설명을 해버린다. denoising 과정에서 나온 noisy image 상에서 masked region은 그대로 냅두고, 그 외 영역은 깨끗한 이미지 + noise로 forward noising으로 채우는 방식을 반복하는 것이다. denoising 과정에서 지맘대로 복원할텐데, 자꾸 mask 아닌 영역은 원본에서 뗘와서 바꿔치기 해주는 식. 결국 학습 완료된 diffusion model의 denoising 과정에서 원본 출신의 noise로 바꿔치기하는 과정을 끼워넣은 것. ----------- 원본으로부터 온 noise를 기반으로 masked region noise를 채울 때, 자연스럽게 생성하길 기대하는 것. |
 |
|
  |
근데 이 방식은, 하나 리스크가 있다. 학습 완료된 diffusion model이기 때문에, 원본 영역에서 뗘온 noise를 이용해서 masekd region noise를 생성하는 방법을 배울 순 없다. 따라서 지맘대로 생성할 확률이 매우 높다.  실제로 잘 안된다. 자연스럽긴 한데 semantic하게 봤을 때는 틀리게 생성한다. ------------ 이를 해결하기 위해서 T -> T-1 로 Denoising 한 번 할 때, masekd region 갖다 붙이기를 여러번 반복한다. T->T-1 후 mask로 조합 그리고 T-1 -> T로 다시 forward denoising 했다가 , fusion된 결과를 다시 noising하고, 그걸 또 denoising하고, 다시 fusion하고 또 다시 noising 하고 이런 식으로 왔다리 갔다리 하는 것이다. 이렇게 하면 masked region과 unmasked region 간의 정보 점차 섞이게 된다고 함. 1 step denoising할 때 이렇게 왔다리 갔다리를 많이 반복하면 실제로 좋아짐.  |
  |
알고리즘으로 보면 왼쪽과 같음 단점은 inference 속도가 많이 느려짐 보통 inference할 때 step 30번 denoising한다고 하면 왔다리갔다리를 20번 씩 한다쳤을 때 사실 상 600번 denoising하는 셈이 된다. inference 속도가 엄청 느려지는 단점이 있음. |
 |
총 denoising step * 왔다리 갔다리 중 step 수가 늘어나는게 중요할까, 왔다리 갔다리 횟수가 늘어나는게 중요할까. 왔다리 갔다리가 더 중요하다고 한다. denoising step을 적게 가져가더라도, 왔다갔다를 많이 하면 성능이 좋아짐. |
 |
 |
 |
|
  |
 |
  |
|
 |
개인적으로 diffusion model이 잘하긴 하지만, controlability가 높지 않기 때문에 inpainting 시 원본을 유지해야 할 곳도 미묘하게 뭉개는 문제가 있는데, 이 방법은 아예 원본을 뗘다붙이고 이에 자연스럽게 생성하는 것을 목표로 하기 때문에 문제를 잘 푼 것 같다. 게다가 학습을 하지 않으니 얼마나 좋은가. diffusion model이 inpainting 대상 도메인을 잘 먹고 학습된 모델이기만 하면 될 듯 |
반응형