반응형
내 맘대로 Introduction

이 디즈니 논문 이해하려고, StyleFlow, SAM 도 읽었다...
SAM 논문에서 image to styleGAN latent w + condition 주는 방법을 제안하고 준수한 성능을 보였지만, 조금 네트워크가 복잡하고 (pretrained network가 덕지덕지) 약간의 artifact(배경이 달라지거나, 헤어스타일이 바뀌는 것 등)가 생기는 문제가 있다.
이는 latent만 찾아주고 이미지를 생성하는 것은 전적으로 pretrained styleGAN2 generator에게 맡겨버리기 때문이다.
이 논문에서는 다 떼고 앞선 SAM으로 데이터를 만들고, generator를 따로 학습하는 한다. 이 때 generator가 얼굴에만 집중할 수 있도록 얼굴 마스크를 같이 넣어주고, 입력 이미지 대비 residual RGB만 예측하도록 단순화했다.
풀고자 하는 문제는 SAM과 같고 심지어 데이터마저 SAM이 만들어주는 데이터를 쓰기 때문에 SAM 변형 버전이 아니냐 라고 할 수 있는데 맞다.
SAM을 하나의 Unet generator로 압축하는 논문이라고 봐도 무방하다. 다만 Unet generator가 얼굴에만 집중하는 효과가 두드러지기 때문에 SAM 보다 성능이 더 좋아진 것.
메모
 |
그래픽 작업할 때 사람 나이를 젊어지게 하려면 원래는 디자이너가 직접 수작업을 해야 함. 이 때 얼굴만 젊어지게 자동으로 해준다면 일이 정말 많이 줄어듦 -> SAM이 이걸 할 수 있음 근데 이 때 얼굴만 정확하게 바꿔야지, 디자이너가 작업한 헤어스타일이나 옷 같은 걸 건들면 또 작업해야 하므로 "얼굴에만 집중하는 SAM"이 필요했던 것 -> Generator만 따로 만들자. -> 이 논문. |
  |
 aging network의 문제는 결국 데이터다. 나이가 들어가는 같은 사람 데이터를 대규모로 확보할 방법은 존재하지 않기 때문. 이 문제는 그냥 기존 SAM 처럼 나름 잘 생성하는 aging network를 가져와서 찍어내는 방식으로 해결했다. SAM을 그냥 믿는 것 SAM이 age control이 되는 styleGAN이니까 믿고 대량으로만 찍어냈다. |
 |
|
  |
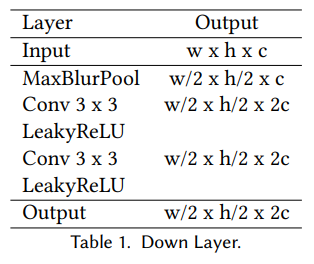
  핵심은 뒤 generator의 구조 변경이다. spatial info 다루는데 좋기로 소문난 Unet으로 바꿨고, 이미지 자체를 생성하는 generator가 아니라 원본 이미지 대비 residual 이미지를 생성하는 generator로 학습시켰다. 이렇게 하면 Unet의 힘과 더불어 원본 이미지를 그대로 가져가므로 생성형 모델의 한계인 불필요한 왜곡을 최소화할 수 있다. face mask까지 입력으로 넣어주므로 더욱 강조됨 -> 이러면 generator의 자유도가 낮아지므로 같은 데이터를 먹어도 성능이 더 좋아짐. -> pseudo GT긴 하지만 supervised learning이니까 학습도 잘됨. |
 |
여기서 discriminator를 끼얹어주면 성능 더 올라감. |
 |
pseudo GT가 있으므로 cyclic 이런거 없이 그냥 supervised learning 박치기. |
 |
|
 |
 대용량 synthetic data의 승리다. Unet 구조 차용도 적절해보인다. |
 |
 |
  |
|
  SAM으로 학습했지만 SAM보다 좋기. |
 |
 비디오 매 프레임을 다른 나이로 변환해서 늙어가는 비디오 만들기 |
 부분적으로 늙게 만들기. |
 사람이 직접하는 거랑 큰 차이없음. |
 |
 |
   |
반응형