반응형
내 맘대로 Introduction

이 논문은 위 사진처럼 얼굴에 사용할 texture만 생성하는 모델이다. BFM model topolgy를 이용하는 방식이고, BFM texture generation 모델이라고 보면 된다. 궁극적으로 하고자 하는 바는 single image가 들어왔을 때 그 안에 있는 사람의 얼굴 texture를 복원해내는 것이다.
occlusion 때문에 가려진 부분의 texture는 알 수 없기 때문에 보이는 부분의 texture 외에는 generation으로 커버하겠다는 컨셉. 이를 풀기 위해선 주어진 이미지 내 얼굴의 자세, texture 외 여러 특징들을 알고 있어야 하는데 각각은 pretrained network들을 가져와서 쓰는 식으로 풀었다.
따라서 이 논문은 전처리, 후처리 과정에 엄청나게 많은 네트워크들이 동원되고 결과적으로 성능이 개별 네트워크 성능에 dependent하다. 결과가 LDM의 힘으로 그럴듯 해보이나, 자세히 보면 여전히 아쉬운 부분이 많은 것 같다. 데이터가 없으니 이런 방식이 최선인 것 같기도.
메모
 |
|
  |
face uv texture map generation 모델이다 보니 대량의 face uv texture map이 필요한데 없다. 따라서 데이터 만드는 것부터 시작함. 1) FFHQ-UV라는 face uv dataset으로 사전학습된 SytleGAN2 + hed pose나 표정 같은 요소 컨트롤이 가능한 INterFaceGAN을 가져와서 Multiview (N=3) images를 만든다. 2) Hair mapper라는 네트워크를 가져와서 머리 영역 segmentation + 해당 부분 대머리로 합성. |
   |
3) Deep3D (microsoft에서 만든 BFM aligner)으로 mesh fitting 후 vertex color 찾아내기 4) uv unwrap 5) averaging uv maps (only visible region)  결과들 256 x 256 해상도인건 pretrained generator 해상도의 한계다. |
    |
 위에서 만든 데이터로 VAE를 학습. 기존 VAE는 도메인이 in-the-wild 이미지기 때문에 face uv map 용 VAE는 새로 학습하는게 맞다. 데이터 찍어낸 것으로 사전 학습 해두는 식. LOSS는 기존 방식과 동일. LDM 학습시에는 임의의 face texture를 생성할 수도 있지만 목적이 "주어진 이미지 사람의 완성도있게 채워진 texturemap"이기 때문에 주어진 이미지 사람의 미완성 texture map을 condition으로 넣어준다. 이 때는 데이터셋 생성시 사용했던 동일한 방식으로 Deep3D + vertex color 찾고 + uv unwrap 방식 그대로 따라 만들고 마지막에 embedding으로 위한 encoder만 추가해주는 방식. |
 |
 |
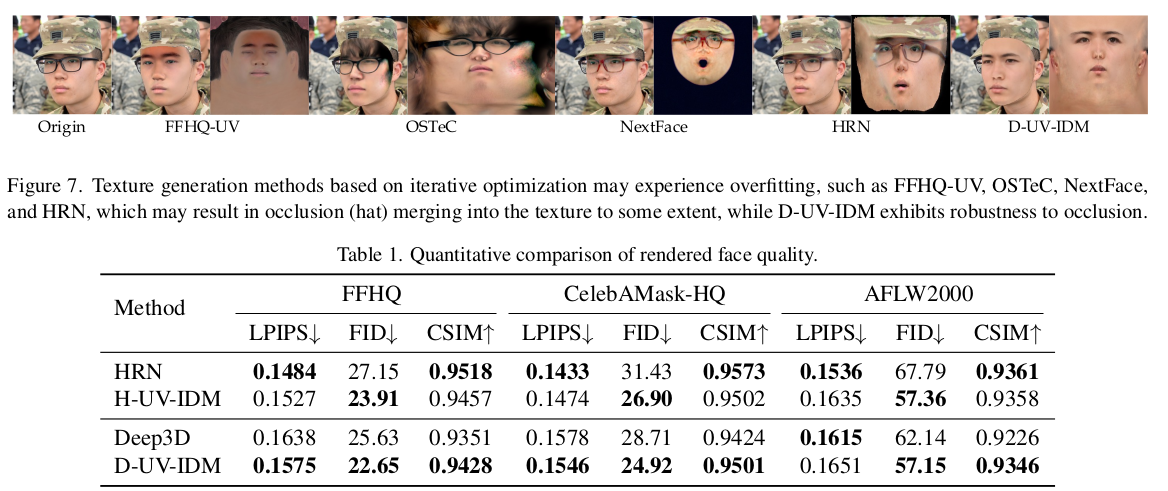 |
|
 |
|
 |
 |
반응형
'Paper > Generation' 카테고리의 다른 글
| RePaint: Inpainting using Denoising Diffusion Probabilistic Models (0) | 2024.07.03 |
|---|---|
| Style-Based Global Appearance Flow for Virtual Try-On (a.k.a Flow-Style-VTON) (0) | 2024.06.25 |
| M&M VTO: Multi-Garment Virtual Try-On and Editing (0) | 2024.06.11 |
| AnyDoor: Zero-shot Object-level Image Customization (0) | 2024.06.07 |
| ToonCrafter: Generative Cartoon Interpolation (0) | 2024.06.05 |