반응형
내 맘대로 Introduction

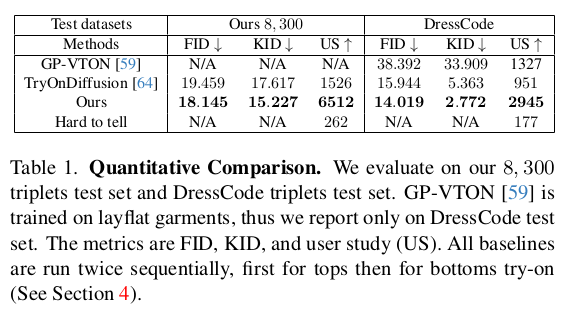
Google에서 낸 VTON 논문. 상하의 신발을 동시에 넣을 수 있도록 한 것과 text guided layout 변경이 가능하도록 condition을 추가한 논문. 학습이 전체적으로 끝난 이후에 한 사람에 대해서 person feature 최적화를 따로 post processing처럼 돌려주는데 이 모듈의 힘으로 identity, detail preserving이 더 잘 된다.
사람마다 최적화한 person feature는 따로 저장해두고 사용 (명 당 6MB 정도라고 함) 하는 방식이다.
어떻게든 잘되게 만든 방법 같기도.
메모
 |
|
 |
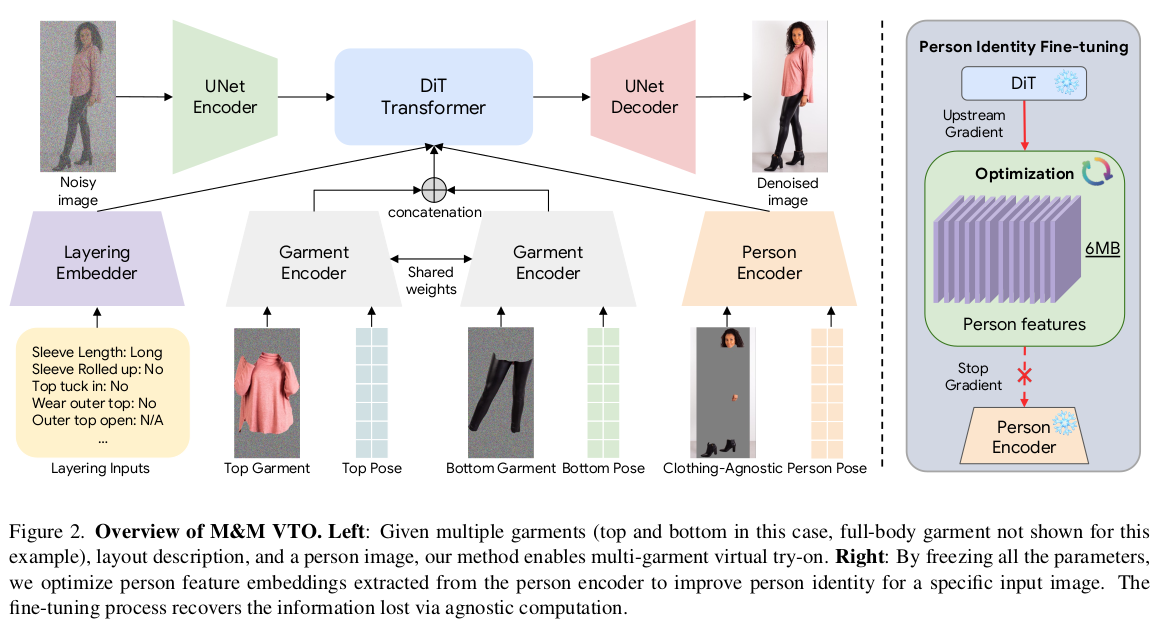
위 흐름 그대로 사람 이미지 에 각종 상하의 이미지가 들어가는 구조. 그림을 조금 다르게 그렸을 뿐 SD 쓰는게 맞다. |
 학습용 데이터는 vitonhd, dresscode는 커녕 1700만개를 모아서 사용했다고 한다... 잘되는게 데이터 빨일 수준. labeling은 이 논문의 전작인 VTO 논문과 같은 데이터를 썼고 text input은 PaLI-3를 finetune....진짜 구글이니까 한 논문이다. |
  |
 |
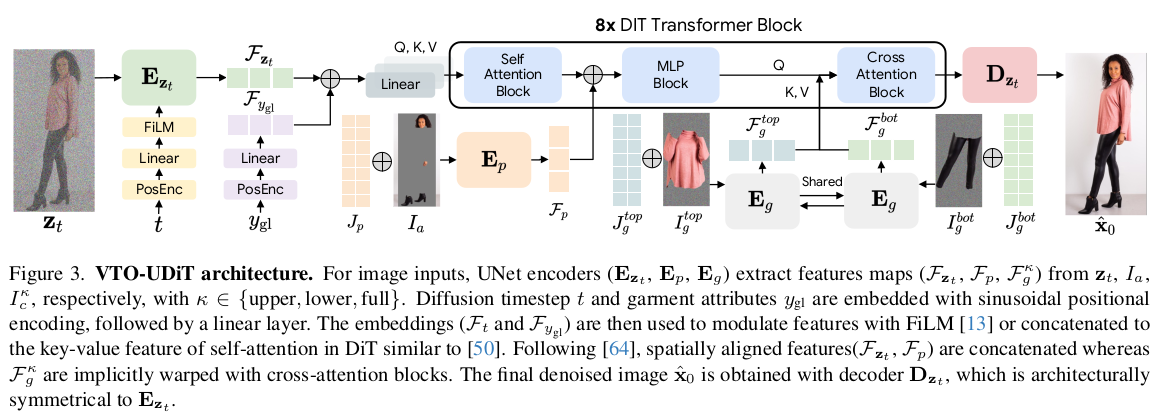
 diffusion model도 직접학습 시켰는데, 저해상도 이미지로 먼저 학습시키고, 고해상도 이미지로 한 번 더 학습시키는 방식으로 해야 cross attention layer가 수렴을 잘 한다고 함. 이렇게 하는 이유는 detail을 복원하려면 cross attention이 제 위치를 잘 잡아줘야 하기 때문. implicit하게 detail에 집중하도록 유지하는 학습 방법론. (설명은 거창하지만 그게 진실일까 1700만개 데이터가 진실일까) |
 |
|
  |
기본 weight는 ImaGen을 사용함. Unet encoder와 Unet decoder 상이에 DiT (heavy transformer)를 달아서 변형함. 애초에 데이터가 많아서 학습을 다시 해도 될 규모이기 때문에, 이런 구조적 손질이 가능한 것 같다. 모든 condition 값들은 Unet encoder/decoder에 cross attention으로 가해지는 것이 아니라 DiT 중간 transformer에 cross attention으로 들어가는 구조가 된다. |
  |
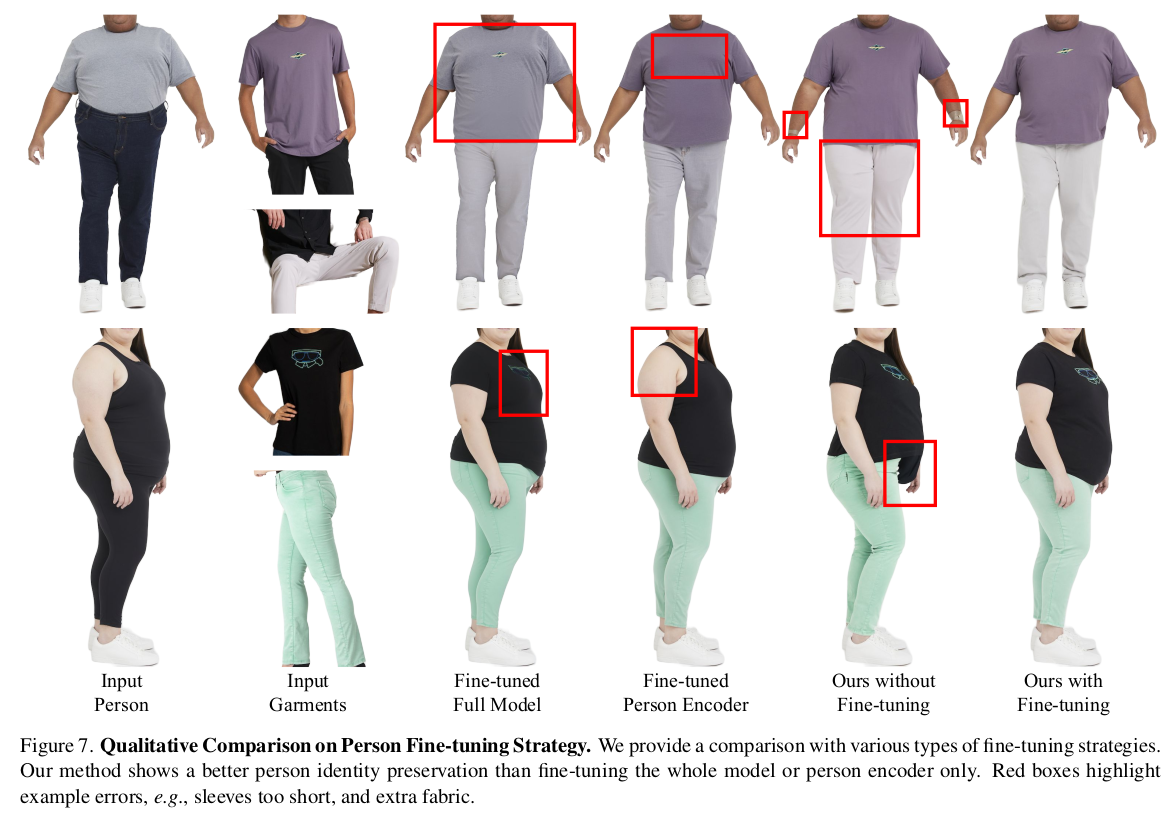
생성에 핵심이 되는 Diffusion model 쪽은 원본 그대로 존재하고 새로 추가한 DiT에 cross attention으로 condition이 추가되는 구조이다 보니 tuning이 쉽다고 볼 수 있다. 가운데 DiT 만 건드려도 되는 수준이기 때문이다. -------------- 여기선 근데 다른 튜닝보다도 사람의 체형이나 자세에 대한 변형에 맞추어 overfitting하는 과정에 집중해서, 주어진 사람 체형이 맞는 생성을 강조했다. Diffusion model+ DiT전부다 freeze. person feature 자체를 튜닝. 이러려면 같은 사람이 다양한 자세+ 다양한 체형으로 옷을 입고 있는 데이터가 필요한데 이게 가능할리가 없다. 그래서 기존 학습 완료된 모델에 계속 옷 이미지 + 다른 사람들 잔뜩 넣어서 결과 뽑고 synthetic 데이터를 만들어서 썼다고 한다. ( 어이가 조금 없는게 잘되게 만들려고 잘됐다 치고 만든 데이터로 튜닝은 했다...?) 그냥 다시 말하면 person encoder의 성능은 한계가 있어서 학습이 완료된 이후에 Diffusion model의 힘으로 잘된 예시들 잔뜩 만들어낸 다음 person feature를 한 번 더 업데이트하고 쓰는게 낫다. |
 |
 |
 |
 |
 |
|
반응형