반응형
내 맘대로 Introduction

Diffusion model로 multiview image를 생성해낸 뒤, NeRF를 붙여 복원해내는 기존 방식들의 상위 호환 버전 논문이라고 할 수 있다. diffusion model의 성능이 껑충 뛰어오른 것도 성능 향상의 한 이유라고 볼 수 있겠지만, novel view synthesis 과정에서 diffusion model을 활용하는 아이디어가 깔끔하고 좋았다.
주어진 모든 view를 noise없이 넣고, novel view는 noise로 넣어서 diffusion 하는 방식. novel view에만 집중할 수 있도록 구성했다. 구조적으로 3D self attention이 효과가 좋았다는 것을 밝혔다.
메모
|
|
 |
사실 그림으로 설명이 끝난다. multiview image로 바꿔주는 diffusion model을 학습하는 것 1) 알고 있는 뷰는 noise 없이 raymap과 함께 token화 2) 생성할 뷰는 noise + raymap과 함께 token화 3) NeRF reconstruction을 통해 loss |
|
|
|
pretrained diffusion model을 갖다 쓰긴 했지만 생각보다 아키텍쳐 연구에 힘 쓴 느낌. 1) 기존 diffusion model의 time 대신 camera pose 넣는 방식으로 변경 2) 중간 중간 layer 추가하는 식. 3) 3D self attention으로 변경. 2차원은 공간, 1차원은 이미지 레벨 3)으로 변경하면서 PixelNeRF나 CLIP 떼어도 잘 됐다고 함. (이거 나름 핵심) |
|
raymap은 ray origin 3, direction 3 총 6차원 값을 latent화 한 것. |
 |
|
 |
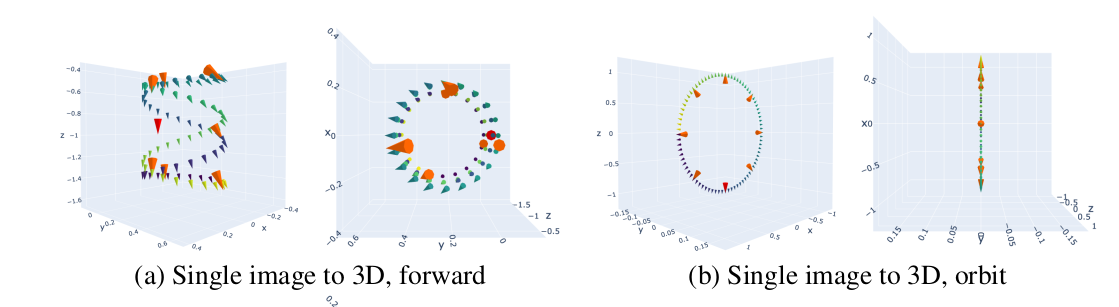
diffusion model이 힘이 좋긴 해도, 새로 생성할 novel view가 기존 view와 겹치긴 해야 잘 생성한다. 따라서 novel view의 camera pose를 생성하는 방식이 조금 제한되는데 위 그림과 같이 물체를 중심으로 뱅글뱅글 돌거나, 물체를 원으로 훑으면서 정면에서 찍는 방식을 사용했다. 2개 더있는데 다 뱅글뱅글임. |
 |
생성할 때도 전혀 가까운 view 생성을 잘하긴 함. 따라서 anchor view를 먼저 만들고, 타고타고 퍼져나가는 식으로 consistency 유지하도록 함. |
 |
diffusion model 이다 보니 정사각 이미지만 받을텐데 이건 crop하고 반복하는 식으로 해결 fancy하진 않은 듯. 시간 소모 증가. |
 |
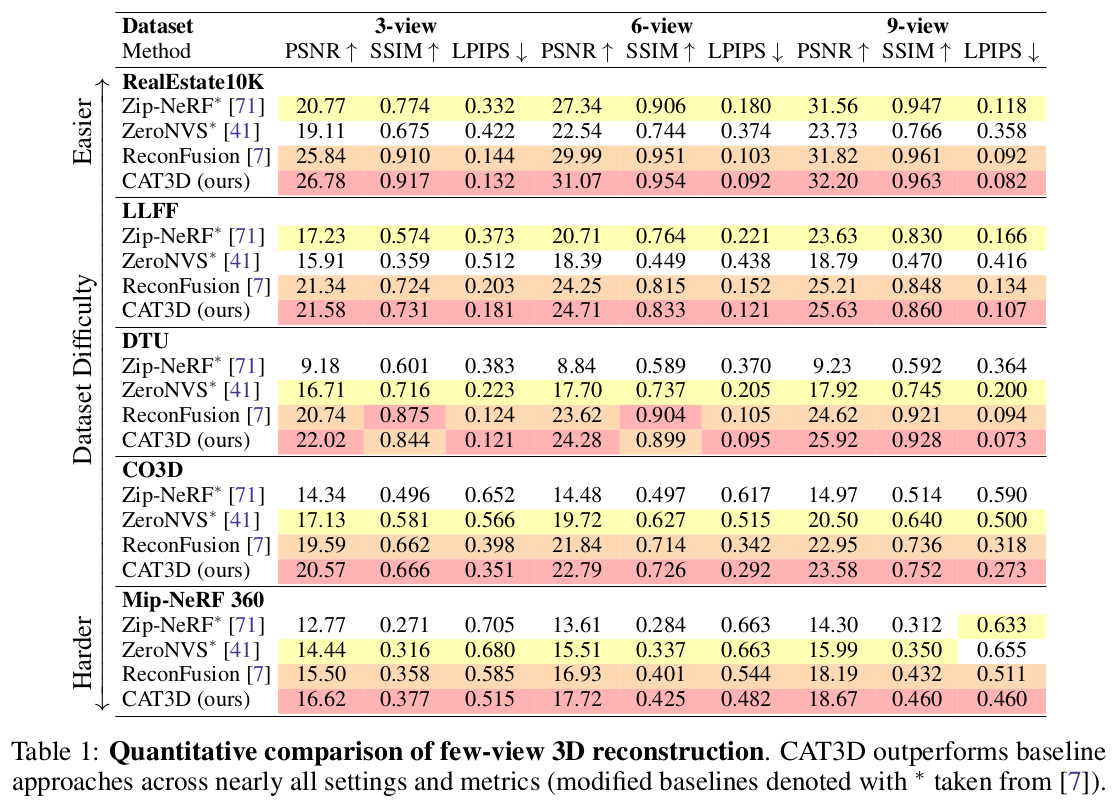
뒤에 따라 붙는 NeRF는 zip nerf 1) perceptual loss 추가 2) 시점이 주어진 시점과 가까울 경우, 가중치 증가 |
  |
 |
 |
 |
반응형
'Paper > Generation' 카테고리의 다른 글
| ViViD: Video Virtual Try-on using Diffusion Models (0) | 2024.05.23 |
|---|---|
| ReconFusion: 3D Reconstruction with Diffusion Priors (0) | 2024.05.22 |
| Improving Diffusion Models for Authentic Virtual Try-on in the Wild (0) | 2024.05.07 |
| InstantID: Zero-shot Identity-Preserving Generation in Seconds (0) | 2024.04.30 |
| Zero-1-to-3: Zero-shot One Image to 3D Object (0) | 2024.04.29 |