반응형
내 맘대로 Introduction

virtual-try-on을 diffusion 모델 써서 하는 논문. 요즘 나오는 conditioned image generation의 추세를 따라, IP-Adapter + SDXL + CLIP + ControlNet를 섞은 논문.
SD1.5 혹은 SDXL이 워낙 강력하다보니 frozen SD를 갖다 붙이는 식의 방식이 레시피의 핵심이 되었고, 자연스레 생성형 논문은 알고리즘적 진일보가 contribution이라기 보다 어떤 식의 조합이 효과적인지 밝히는 실험적 진일보가 contribution인 것 같다.
이 논문은 어떤 pretrained network들을 어떻게 조합해야 원하는대로 virtual try on 이미지를 생성할 수 있는지 조합 레시피를 설명하는 논문.
메모
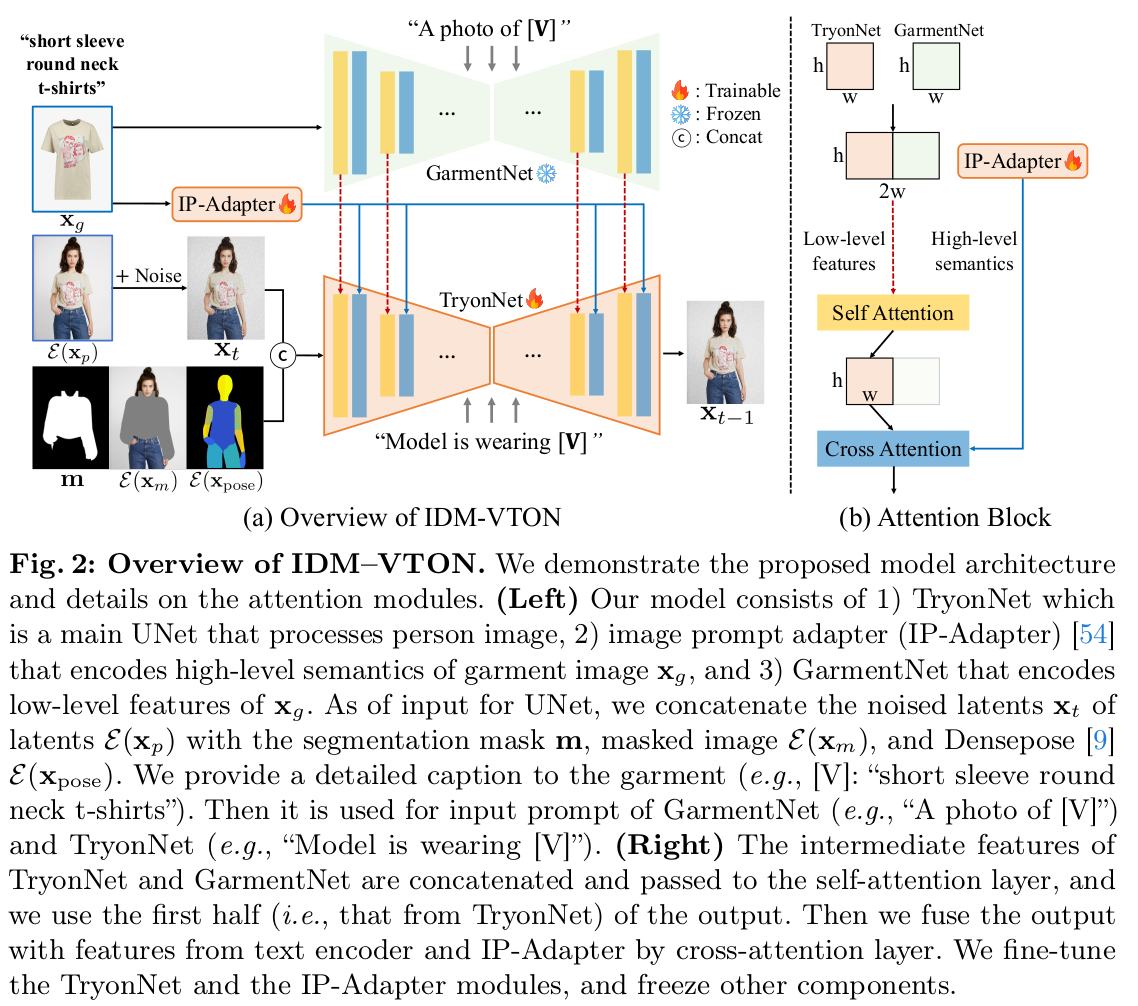 |
|
 |
그림을 보면 강하게 느껴지겠지만 ControlNet 구조를 차용한 듯하다. 1) GarmentNet(SDXL)은 text로부터 옷의 texture feature를 뽑음 (high level detail 담당) 2) IPadapter는 옷 이미지로부터 low level detail feature를 뽑음 -> cross attention으로 활용됨 3) TryonNet(SDXL)은 GarmentNet token 받아 self attention, IPadapter token 받아 cross attention 하는식으로 fine tuing 됨. |
 |
TryonNet SDXL의 Unet 갖다 붙임 입력은 image, mask, masked image, denspose 넣어 줌. -- IPadapter랑 cross attention할 때 이미지 feature, text feature 둘다 받음 |
  |
IPAdatper 도 일단 pretrained임. 갖다 붙인 것. frozen CLIP image encoder + MLP 추가. --------- GarmentNet도 SDXL 갖다 붙인 것. 얘는 text-to-image 모델이다보니 text prompt가 입력. |
 |
디테일을 살리기 위해 CLIP encoded text feature는 garmentnet, tryonnet 둘다 들어간다. |
  |
실제 사용 시, 사람- 옷 pair가 있으면 fine tuning 직접 해주면 좋음. 없을 경우 사람이 시착한 옷을 segmentation으로 옷부분만 남기고 masking해서 옷 이미지 생성해서 튜닝하는 식으로 하면 됨. |
 |
 |
 |
 |
 |
 |
 |
| 성능 지표는 향상 됨. 근데 하나 궁금한 것이 조립형 레시피이다 보니, 조립 품목의 성능에 굉장히 dependent한 성능일 것이다. 기존 논문들 대비 조합 레시피가 좋아서 성능이 나아진 것인지 아니면 그동안 SD1.5에서 SDXL로 늘어난 영향이 더 큰지 궁금하다. 사용한 SD backbone 또한 먹은 데이터나 버전, 심지어는 civitai 등에 튜닝된 버전도 많기 때문에 SDXL 간에도 차이가 있을텐데 그런 ablation이 궁금하긴 하다. |
반응형
'Paper > Generation' 카테고리의 다른 글
| ReconFusion: 3D Reconstruction with Diffusion Priors (0) | 2024.05.22 |
|---|---|
| CAT3D: Create Anything in 3D with Multi-View Diffusion Models (0) | 2024.05.22 |
| InstantID: Zero-shot Identity-Preserving Generation in Seconds (0) | 2024.04.30 |
| Zero-1-to-3: Zero-shot One Image to 3D Object (0) | 2024.04.29 |
| IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models (0) | 2024.04.19 |