반응형
내 맘대로 Introduction

IPadapter + ControlNet을 붙여서 face-identity 유지 잘 되는 SD model 만드는 방법론을 제시한 논문. 알고리즘적 발전보다는 조립을 어떻게 하니까 잘 되더라 발견한데 의의가 있는 논문으로 약간 조립형 논문 같아 보인다.
핵심 아이디어는 Face embedding을 기존 face detection + ReID를 잘하는 모델을 가져와서 쓴 것이다. 이외 facial condition을 keypoint 5개만 쓴다거나 text embedding 대신 ID embedding을 ControlNet에 넣어주거나 하는 트릭은 경험치 정도의 의미가 있는 것 같다.
메모
 |
|
 |
1) Face detector + ReID 모델 + MLP 조합으로 Face embedding 생성 2) IPadapter 형식으로 fine tuning 3) Face embedding을 contidion으로 받는 ControlNet 추가 |
  |
보통 CLIP embedding을 많이 쓰곤 하는데 Face embedding을 새로 고려한 이유는 CLIP 자체가 워낙 카테고리 없이 광범위한 데이터를 먹은 녀석이라 face에 집중한 feature 라고 보기엔 무리가 있기 때문. 따라서 이를 대체할 대체재 중 가장 효과적일 것이라고 생각한 것이 Face detection + ReID 네트워크의 backbone이다. |
 |
IPadapter를 붙일 때 CLIP image feature 대신 앞서 만든 Face embedding으로 대체함. CLIP text feature는 보조 역할로 그대로 freeze되어 들어감. |
 |
controlnet을 붙이는 것도 추가. IPAdapter만 붙이니 성능이 안 좋았다고 함. 1) IPAdapter 시 cross attention 전에 face + text 하면 디테일을 놓침 2) 그렇다고 cross attention 후 face token + text token 합치면 text 힘이 약해짐 face token 힘이 너무 쎄지면 text로 컨트롤 하는 힘이 부족해짐 따라서 ControlNet까지 붙였다고 함 |
 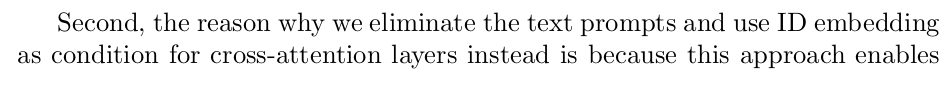  |
ControlNet 특징은 1) facial keypoint를 쓰되 눈코입 5개만 쓴것 - 일반 이미지에서 얼굴 keypoint 다 찾기 어렵기도 하고 - 다 쓰면 너무 keypoint에 의존해서 얼굴 변형 자유도가 낮아진다고 함 2) Face embedding을 여기서 condition으로 또 활용함. - 순전히 face에 더 집중해주길 기대하는 용도 |
 |
학습은 그냥 다 똑같음. |
 |
 |
 |
 |
 |
| 뭐가 더 좋은지 metric이 없어서 애매한 건 generation 논문의 특성인 듯. |
반응형