반응형
내 맘대로 Introduction
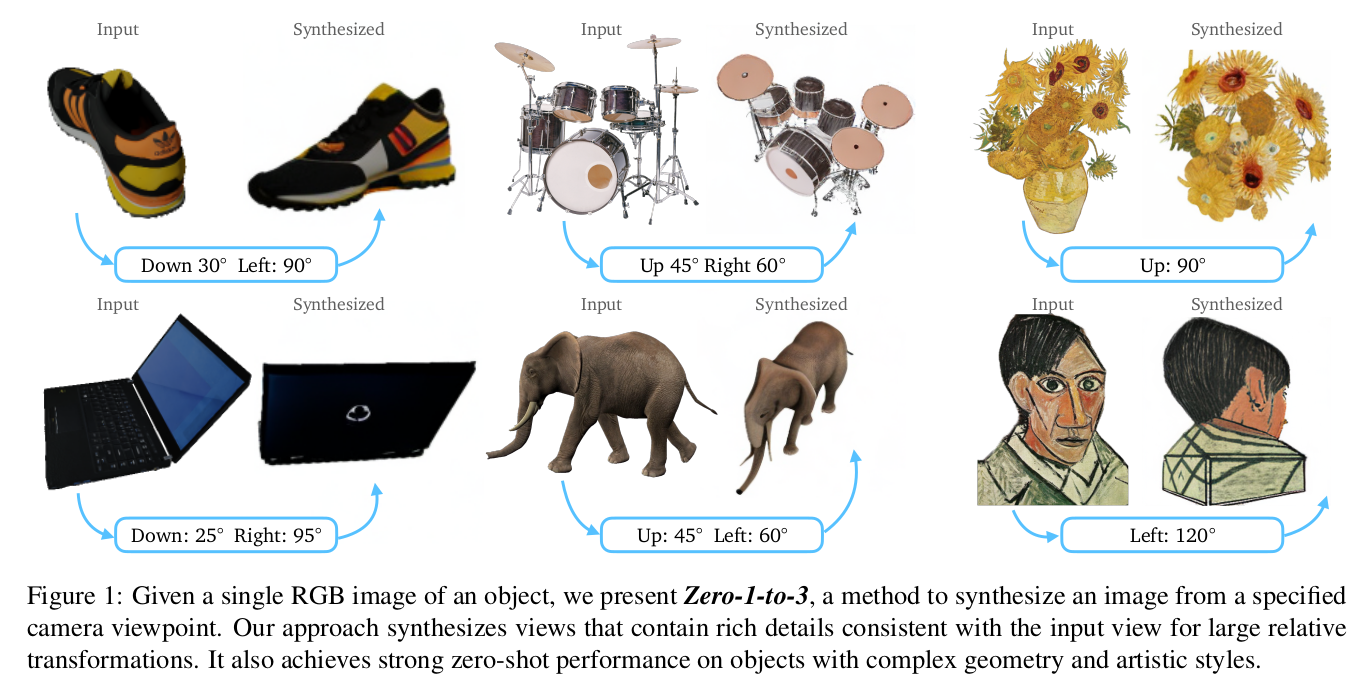
지금 보면 LoRA, ControlNet, IPAdapter 등 SD 모델에 컨디션을 부여하는 방법론이 소개가 되었기 때문에 간단해 보이지만, 연구 당시에 2022년이라는 사실을 감안해서 보면 색다른 시도였다고 생각한다.
핵심 내용은 SD 모델이 갖고 있는 latent space 안에서 geometric consistent generation을 할 수 있도록 view point condition을 갖고 fine tuning하는 것이다.
입력이 이미지 + camera view point가 되고 출력이 해당 view point에서 보면 새로운 이미지다.
메모
 |
컨셉이 간단하기 때문에 내용도 간단함. SD 모델에 컨디션으로 들어가던 것을 camera pose로 한정하고 튜닝하면 된다. |
  |
SD latent space가 워낙 크니까 이 안에 geometric consistent 생성을 유도할 정보는 충분하다. 이를 잘 꺼내 쓸 수 있도록 하는 것만 하면 됨  그대로 쓰면, 먹은 데이터가 정면이 많아서 정면으로만 생성하려고 함. |
  |
학습 loss는 SDS loss 혹은 Score based loss다. 늘 쓰는 방식. |
  |
condition embedding은 두 종류 1) CLIP (image) + R + T concat한 형태로 SD에 넣어줌 2) SD 중간 중간 denoised image 뒤에 channel-wise 원본 이미지 concat. |
  |
 view consistent 생성한 뒤 어떻게 사용할 수 있느냐? 당연히 3D RECON이다. 각 multi view image를 생성한 뒤에 NeRF 방식으로 RECON하면 된다. 이 때 LOSS를 NeRF 처럼 color로 해도 됐겠지만 생성된 이미지도 neural image 이므로 SJC 방식으로 loss를 연결해주면 학습이 가능함. end to end recon이 가능함. |
 |
 |
 |
 |
 |
|
 |
 |
 |
| 이 논문은 중요한게 앞의 SD 성능이 높아질수록 이에 비례해서 좋아지는 구조니까 어디다 가져다 붙이느냐다. 요즘 좋은 SD에 붙인 버전이 계속 업데이트되는 듯. |
반응형