반응형
내 맘대로 Introduction

알리바바에서 낸 Virtual try on 논문. 알리바바가 VTON 기술에 힘을 싣고 있는 것 같다. 사람 + 옷 이미지 생성 관련 논문을 주로 쓰는 듯. 데이터도 적극적으로 모으고, 찍고 관리하는 것 같다. 데이터 규모에서 비빌 수가 없어서 성능 차이가 더 커지는 듯.
이 역시 조립형 논문이다. SD1.5 + AnimateDiff temporal module + CLIP 을 섞어서 VTON 이미지를 만들어 내는 논문. 다만 temporal module을 끼면서 영역을 비디오로 확장했다는 점이 차이.
메모
  |
VVT 하나만 존재했던 cloth-video 데이터셋의 한계를 느끼고 1) 9700 쌍 2) 832 624 의 고해상도 데이터셋을 쇼핑몰로부터 제공받아 새로 만들었다. non-commercial use로 공개될 듯. openpose와 densepose, part segmentation이 제공된다. |
 |
|
  |
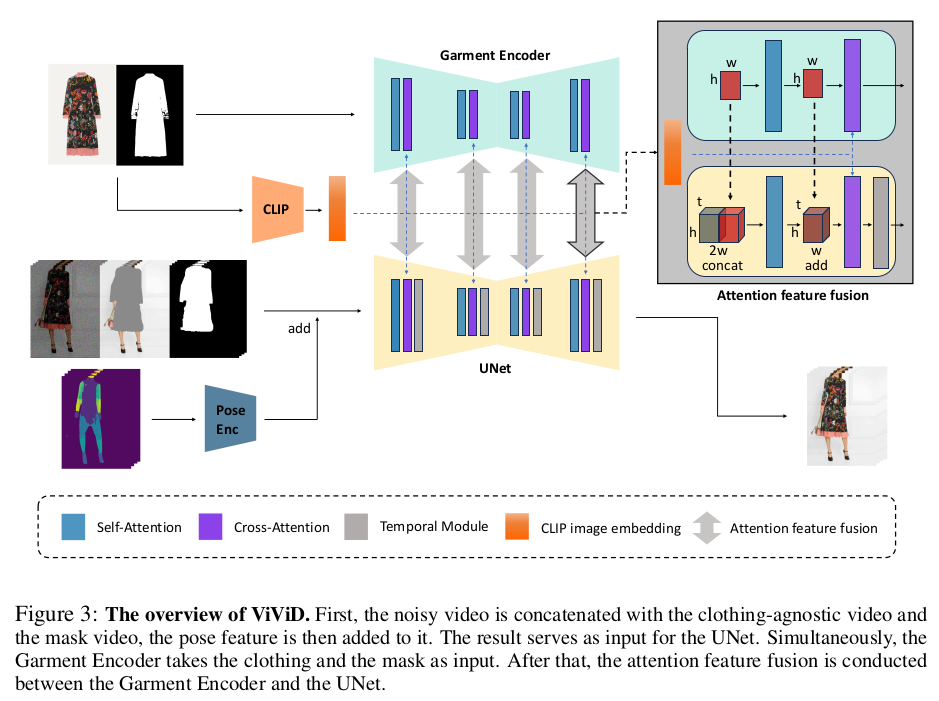
조립형 논문 답게 입력, 구조만 보면 된다. 중간 알고리즘은 다 갖다 붙인 것. 1) 입력 video, masked video, mask, denspose 총 4개 24frame 단위로 끊어서 들어감. 2) 구조 CLIP + trainable Unet으로 옷 정보 추출 SD Unet으로 모델 정보 추출 self attention + temporal attention으로 합침 |
  |
Garment Encoder - SD 1.5 Unet으로 시작 - CLIP으로 부족한 옷 fine detail 잡으려고 추가 - 밑 freezed SD1.5 Unet 의 self attention module에 정보 제공 Pose encoder - 그냥 얇은 CNN Temporal Module - AnimateDiff에 나오는 방식이랑 동일 - width, height 채널을 batch로 몰아 넣고 time 채널에 맞춰 self attention. |
 |
학습은 전체를 한 번에 학습함. 데이터셋을 활용할 때 기존 image-cloth 데이터셋도 같이 씀 image 24개 모아서 video 입력처럼 넣되 temporal module을 얼림. (업데이트를 안함) -------- 이건 temporal consistency 측면에서 방해가 될만한 행동인 것 같은데 좀 생각해볼 여지가 있을 듯. |
 |
A100 GPU로 5일 걸림. |
 |
  |
 |
 |
반응형