반응형
내 맘대로 Introduction

CAT3D 의 이전 작. 하위호환이라고 할 수 있다. diffusion model을 이용한 multi view image 생성 + NeRF로 3D recon이 포함된 내용.
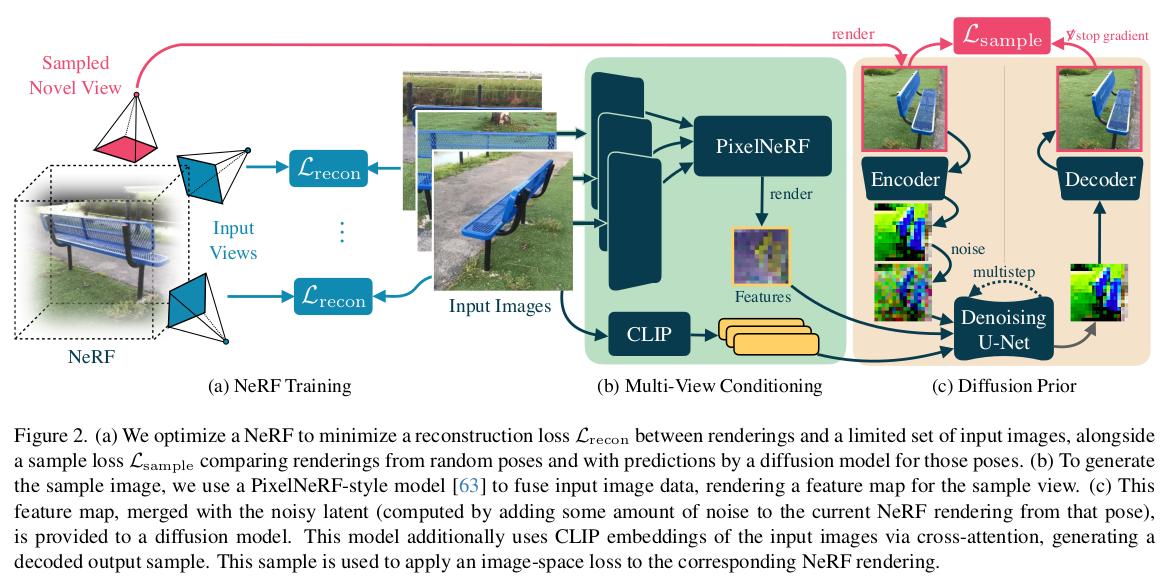
핵심 아이디어는 3d recon을 위한 NeRF 외에 pixel-NeRF를 붙여서 rendered feature를 만들고, 이를 diffusion model의 입력으로 활용하는 식으로 3d consistent novel view image 생성을 유도함.
내용은 엄청 간단함.
메모
 |
|
 |
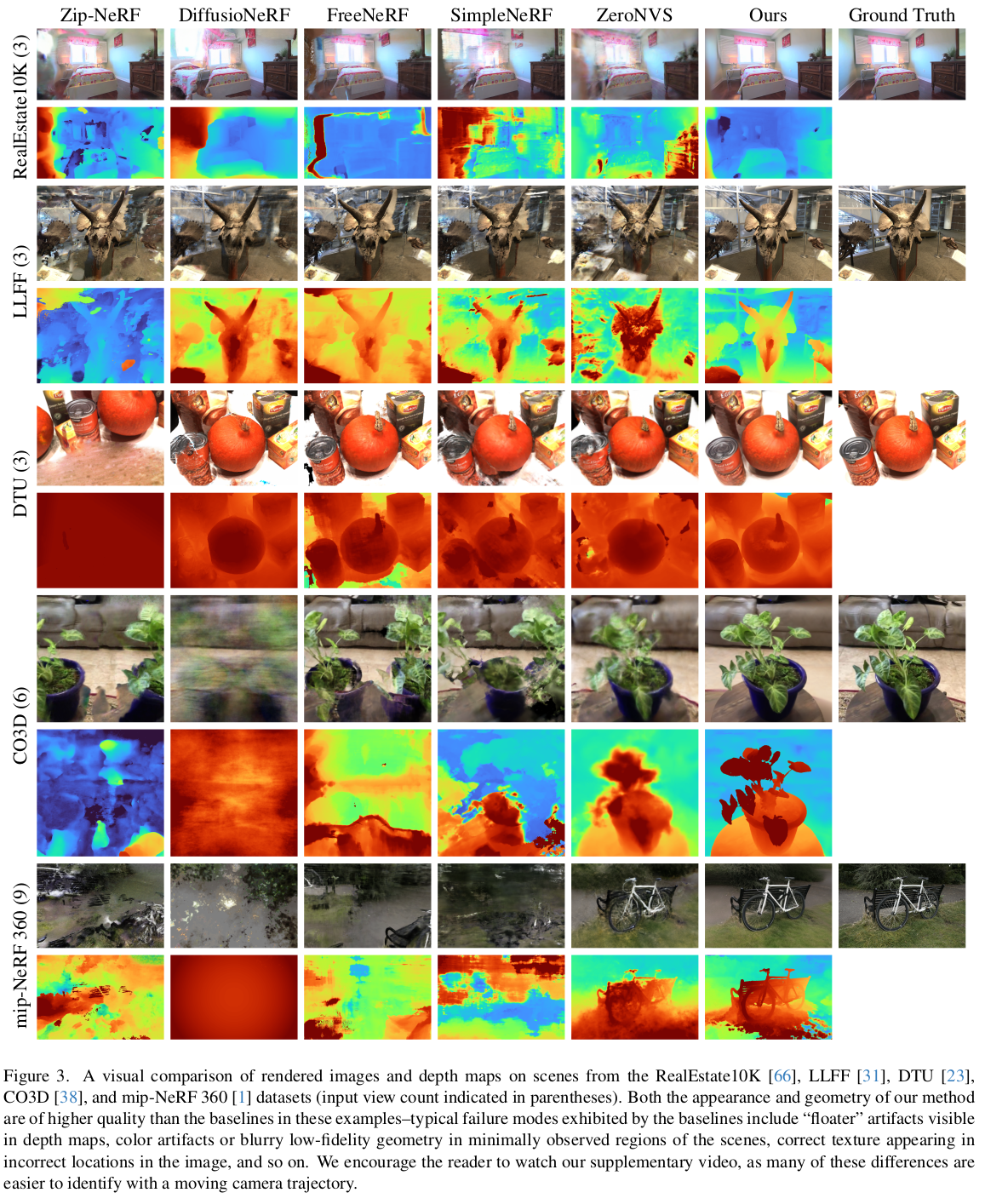
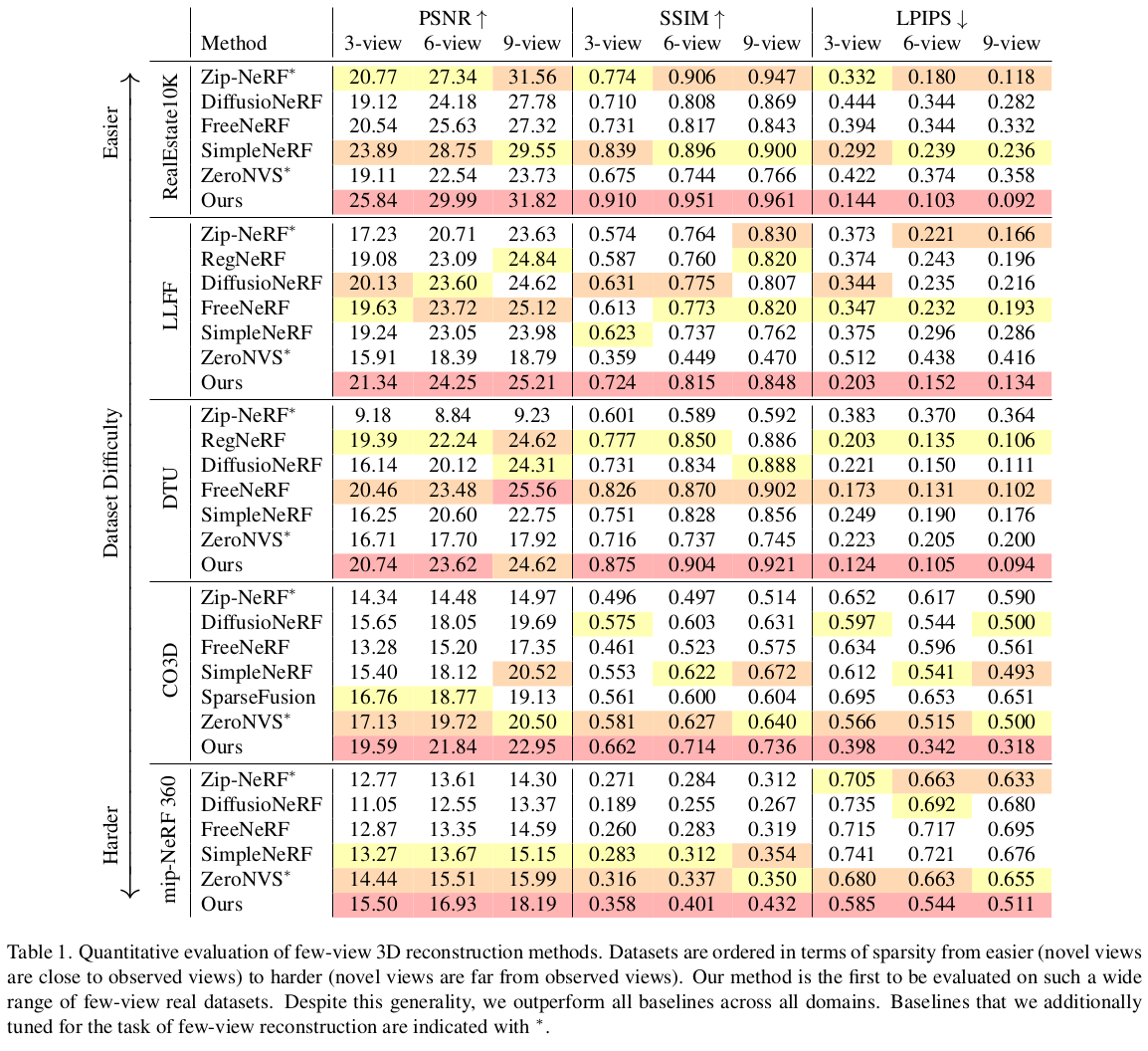
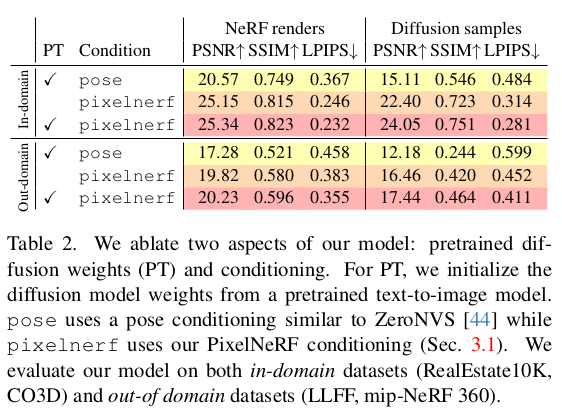
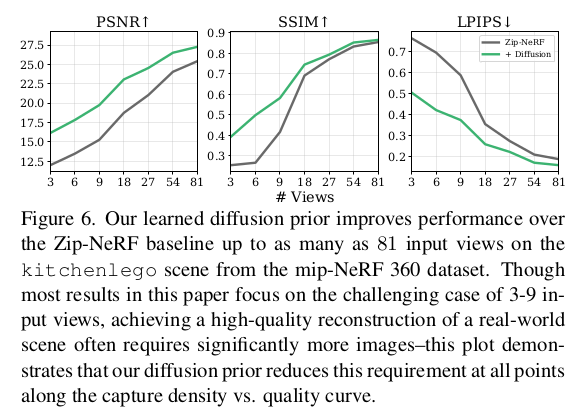
이것도 그림으로 설명이 끝남. 1) 크게 Zip-NeRF를 학습시키는 거임 2) 부족한 novel view 이미지는, pixel-NeRF로 찍어낸 feature map + input 이미지를 받는 diffusion model에서 얻어옴 3) diffusion 을 3D consistent한 생성으로 유도하기 위해 CLIP feature를 추가하고, Pixel-NeRF를 이용했다는 점이 핵심. |
  Diffusion model은 당연히 기존 LDM 가져와서 일단 시작 ZERO1to3처럼 view condition을 넣어줘야 하는데 view point를 넣어주는 것은 물론 1) CLIP feature 2) pixel NeRF를 이용한 view dependent- rendered feature 추가 |
 loss는 diffusion loss pixel NeRF도 학습되긴 해야 하니까 rendering loss 총 NeRF가 2개 학습되는 형태다. 최종 결과 만드는 NeRF , diffusion을 돕는 NeRF |
  |
최종 결과를 만드는 NeRF는 zip nerf임 reconstruction loss와 더불어 anti-aliasing이 들어있는 기본 NeRF 구조라고 보면 됨. 최종 렌더링된 결과가 diffusion 생성 결과랑 같도록 연결 짓는 diffusion loss를 하나 더 추가 (이름 이 diffusion loss라 헷갈릴 수 있는데, 그냥 렌더링 결과가 생성 결과랑 같도록 유도하면서 diffusion model 학습을 더 강화하는 것) |
  |
생성할 novel view는 너무 극단적으로 위치를 옮기면 당연히 안된다. input view들과 overlap이 많도록 해야 하는데 이를 안전하게 구현하기 위해서 input view camera trajectory를 보고 이 사이에서 뽑아낸 뒤 pertubation하는 식이라고 한다. |
 |
 |
 |
 |
 |
 |
반응형