반응형
내 맘대로 Introduction

크게 보면 ControlNet이랑 마찬가지로 학습된 Diffusion model에 condition을 가하는 방법론인데 차이점이 존재한다.
1) 특별한 2D conditioned map이 아니라 이미지 자체를 condition으로 넣을 수 있다. CLIP(image)를 conditioned map으로 씀.
2) cross attention layer만 추가한 수준이라 원 모델을 훨씬 덜 건드린다.
3) 기존 text feature와 상호 조절이 가능하다. (controlnet은 입력에 넣는 것이라 text랑 상호 조절은 안됨)
다른 표현으로는 prompt를 건드는 수준이다.
위와 같이 장점이 명확하기 때문에 최근에는 controlnet보다 더 자주 쓰는 방법인 것 같다.
메모
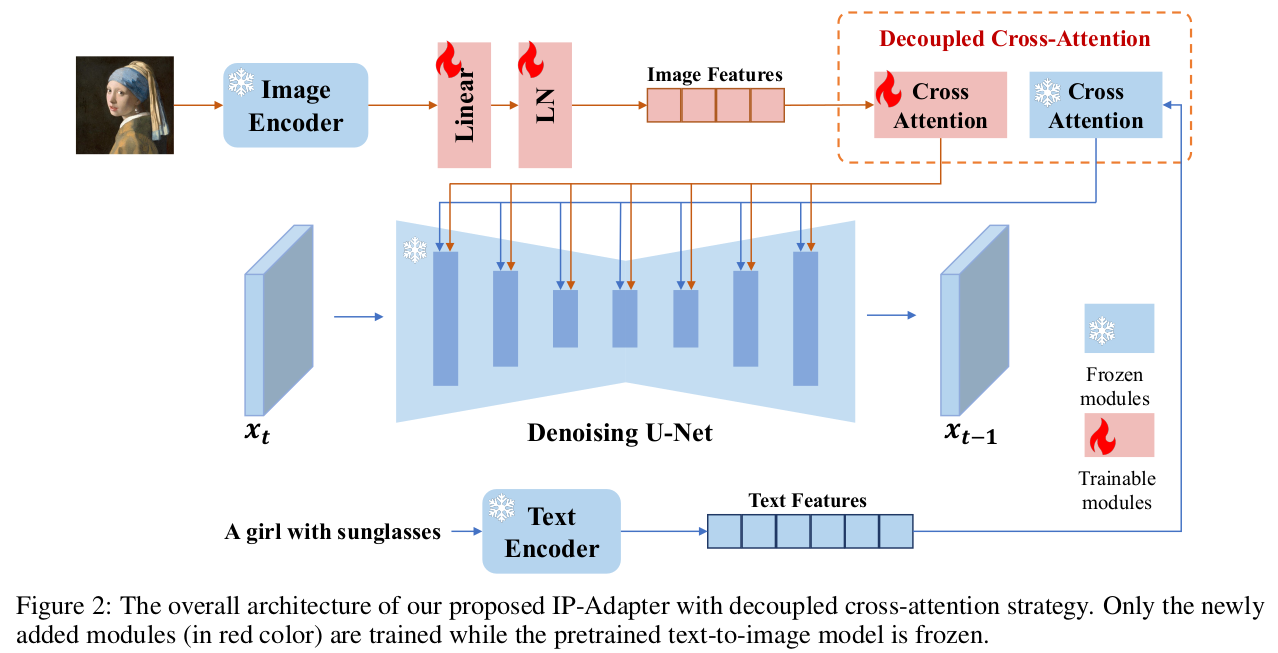   |
| 이미지 feature를 따로 넣어주면 제대로 반영되기가 어렵다. Text feature는 이미 강하게 반영되도록 학습되어 있기 때문에 image feature가 text feature space로 옮겨가는 방향으로 학습되고 고유의 image feature를 살리는 방향으로 가지 못한다. 따라서 image feature만 따로 불어넣어주는 cross attention layer를 추가한다. (text feature가 들어가는 채널과 동일하게 image만을 위한 채널을 뚫어주는 것) |
 |
| text feature와 힘싸움을 해야하므로 image encoder도 CLIP을 쓴다. CLIP image encoder를 고정한 뒤 뒤에 dimension을 맞춰주는 용의 MLP만 조금 달아서 사용했다. |
  |
| texture feature가 cross attention으로 들어가듯이, image feature도 cross attention으로 똑같이 넣어준다. 수식이 동일하고. cross attention feature를 단순하게 더해준다. text + image 반 반. |
 |
| 여기서 더할 때 반반이 아니라 특정 비중으로 조절하면 text와 image가 힘싸움하게 할 수 있다. 따라서 text보다 image를 강하게 반영하는 것도 가능함. (기존 controlnet에서는 불가능) |
 |
 |
 |
 |
 |
 |
 |
| canny edge, openpose, sem.seg map 같은 형태만 이미지고 CLIP에서 자주 쓰지 않는 이미지도 괜찮다. CLIP image encoder가 강력한 pretrained model 역할을 하기 때문에 알아서 튜닝된다. |
 |
| 다른 애들은 보면 image, text 프롬프트가 둘 다 제대로 반영되지 않는 경우가 많다. 둘이 힘싸움을 비등비등하게 하지 않고 하나가 dominant하기 때문. 반면 IPAdapter는 비교적 잘 하는 편. |
 |
 |
반응형