반응형
내 맘대로 Introduction

Animate Anyone 이랑 타겟하는 문제가 같다. 입력 이미지 1장 주어지고 pose guidance 여러개 주어졌을 때 해당 이미지 내 사람이 주어진 동작을 하는 영상을 만들어내는 것인데 이 논문의 차이점은 pose guidance를 openpose keypoint가 아닌 SMPL로 확장했다는 점이다. 이전에 dense pose uv map을 쓰는 논문도 있었던 것 같은데 아주 단순한 아이디어를 빠르게 구현한 논문 같다.
vertex 위치를 쓰는 것이 아니라 depth, normal, semantic, keypoint 쓸 수 있는 걸 다 썼다.
메모
  |
| animate anyone이랑 구조가 거의 동일하다. openpose keypoint map 들어가던 곳을 SMPL rendering으로 얻은 온갖 2D map으로 바꾼 것 뿐이다. PSA라고 적혀있는 것은 별다른 것이 아니라 모든 frame에 대해 shape parameter를 공유하도록 피팅했다는 얘기. |
 |
| https://shubham-goel.github.io/4dhumans/ 위 ICCV23 논문 써서 이미지에 대응 되는 SMPL 파라미터 뽑음. 렌더링해서 depth, normal, semantic label, keypoint 얻어두기 |
  |
| 모든 프레임 간 shape parameter는 공유되도록 SMPL 파라미터를 구했다는데, 이건 4D human이 tracker가 붙어있는 알고리즘이라 거기서 알아서 해주는 것 같다... (그리고 이건 당연히 해야하는 것.) |
 |
| 4종류의 guidance는 하나로 합쳐지는 과정을 거쳐야 함. |
  |
depth, normal, semantic, keypoint 각각 마다 self-attention F가 붙음. attention 활성화되는 부분을 시각화해보면 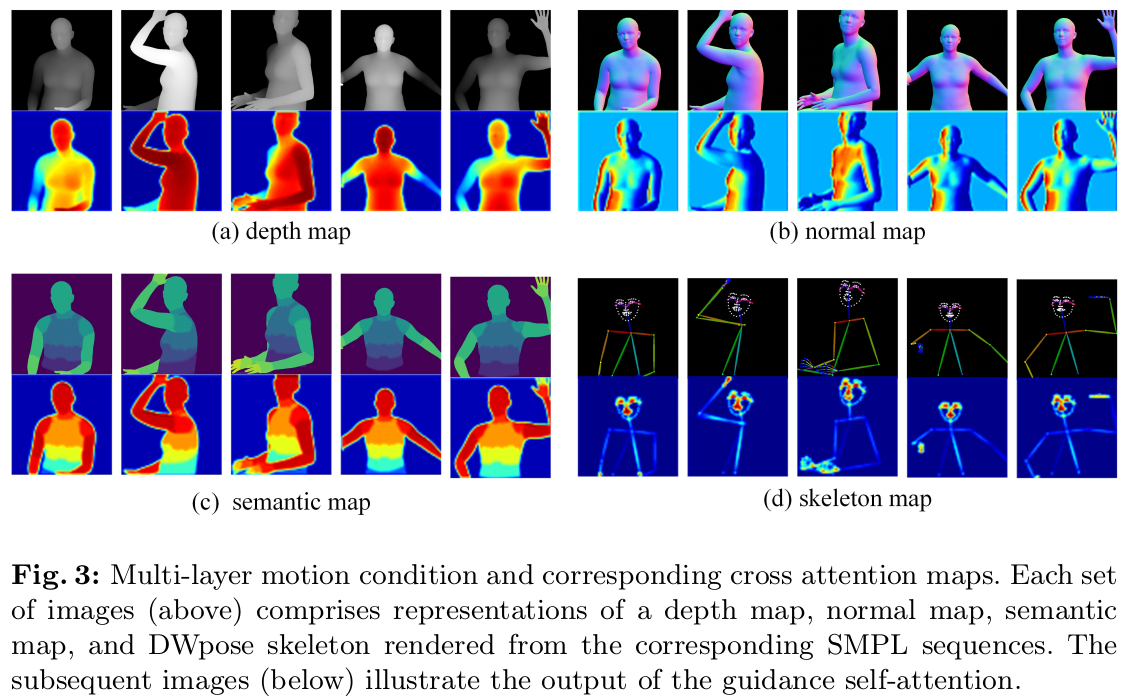 위와 같이 생겼는데 depth는 형상, normal은 사람의 방향, semantic은 inter-occlusion, keypoint는 얼굴,손에 집중하게 만든다고 한다. |
 |
| 각 self-attention F를 통해 나온 4개의 값은 그냥 더함 |
  |
| 네트워크는 animate anyone(animateDiff) 가져다 썼다. self attention으로 각 guidance encoding하고 합친 부분만 구조가 달라짐. VAE CLIP은 원래 있던 것. |
 |
| 큼직한 것들은 전부다 고정. self attention 추가한 부분이랑 reference image 뽑아주는 ReferenceNet만 업데이트 됨. |
 |
| 중요하지 않은 내용. |
 |
 |
 |
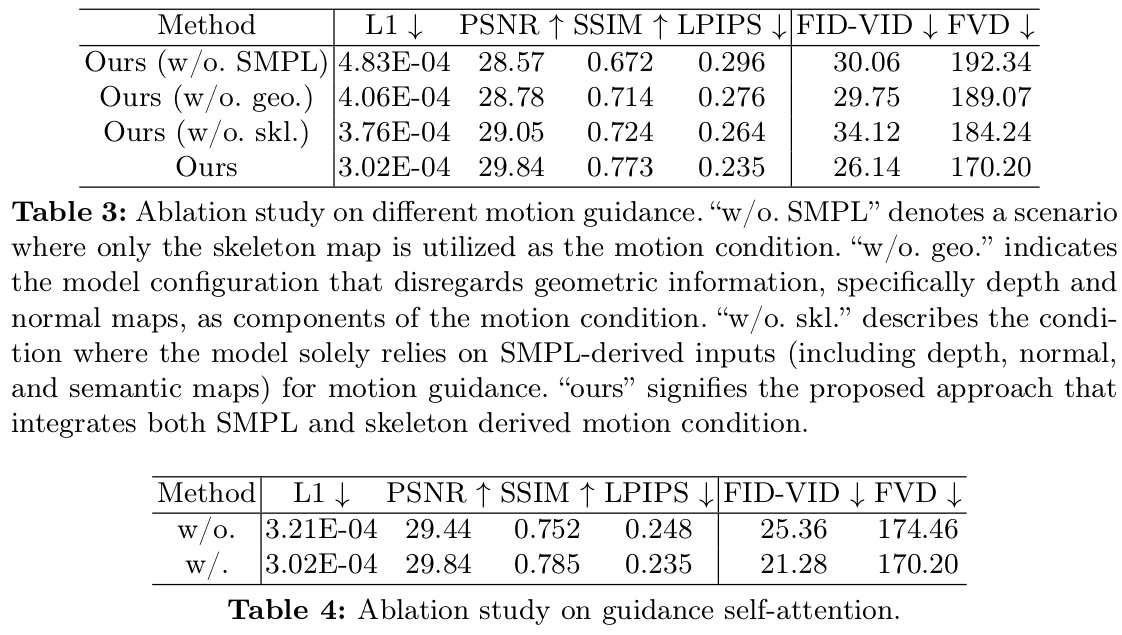 |
 |
 |
  |
반응형