반응형
내 맘대로 Introduction

ControlNet은 워낙 유명해서 논문을 보지 않았어도 무슨 역할을 하는 기술인지 알 수 밖에 없다. 이제 개인, 팀 단위의 학습 범위를 넘어선 Stable Diffusion trained model들은 재학습이나 튜닝 조차 손대기 어려운데 SD 모델을 고정해둔 채로 원하는 condition을 만족한 이미지를 생성하도록 튜닝하는 방법론이다.
핵심 아이디어는 모델 전체는 고정해두고 입력을 latent로 변환해주는 encoder 부분만 손을 대는 것이다. encoder는 전체에 비하면 아주 작은 부분일 뿐이지만 source를 만드는 역할이라 비중은 상당한 부분이기 때문이다.
메모
   |
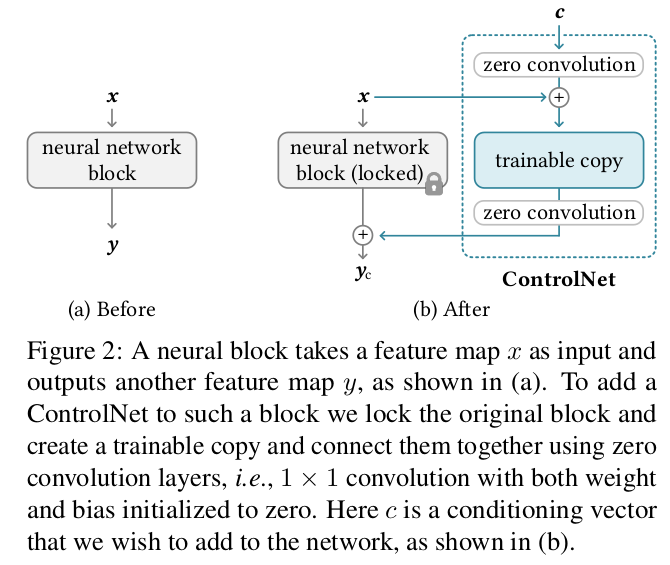 내용은 사실 위 그림 한장이 끝이다. 1) 입력을 받는 부분의 copy를 만들고 원래 것은 고정함 2) trainable copy 앞뒤로 0으로 초기화된 1x1 conv를 추가함. 3) 튜닝 이렇게 하면 trainable copy에서 condition을 보고 latent를 어떻게 업데이트하면 되는지 학습한다. 학습 초기에 noise가 큰 문제는 앞뒤로 zero convolution을 달아두었으므로 영향력을 0으로 만들어 해결했다. 0으로 초기화되어있으니 gradient가 안 흘러들어갈 것 같지만 이거 따져보면 잘 흘러간다. |
  |
| 대부분 0인게 맞는데 마지막 항을 보면 Weight에 대한 gradient는 입력 I로 계산되는데 all-zero 입력을 넣는 경우는 없고 noise라도 넣으니 사실 상 non-zero다. 따라서 weight가 업데이트 무조건 되므로 순차적으로 bias도 업데이트 됨. 전부 다 점점 더 gradient가 흘러들어감. |
   |
 실제 구체적인 구조는 위와 같음. CNN이 섞여 있기 때문에 zero convolution이 끼는 부분이 상당히 많음. conditional input을 해상도에 맞추어 64x64로 만들어두는 것은 필수. |
 |
training은 원래 stable diffusion 하듯이 하면 됨. 대신 원래 모델 부분은 얼려져있으니 사실 상 trainable copy 부분만 업데이트 되는 것. 수식(5)에 conditional input c_f가 추가된 것만 차이. 새로 추가된 condition이 기존에 들어가면 CLIP condition에 너무 밀려서 의미없어지면 안되니까 prompt를 일부러 50퍼센트 비워서 약화시켰다. 신기하게도 이렇게 학습시키면 학습되는 양상이 점차점차 배워나가는 것이 아니라 어느 순간 갑자기 확 배운다고 함.  |
   |
그냥 붙이면 됨 inference는. SD 학습 시에 condition 들어갔다고 품질 떨어지는 것을 막기 위해서 CFG기법을 쓰는데 (condition 들어가서 학습된 분포랑 condition 안들어가고 학습된 분포랑 유사하도록 추가 loss를 걸어줌) 이 노하우를 적용하는 과정에서도 controlnet은 영향을 주지 않는다. 그냥 둘 다에 새 condition으로부터 오는 변화량 다 더해주면 전체 수식에 영향을 안주기 때문.  어디에 더해주고 안더해주냐 차이라서 조절도 가능함. CFG 효과를. |
 |
여러 condition을 동시에 넣고 싶다면 trained copy 여러개 출력을 그냥 더해주면 된다. 직관과 일치해서 너무 훌륭한 듯.  |
 |
|
 |
 |
 |
|
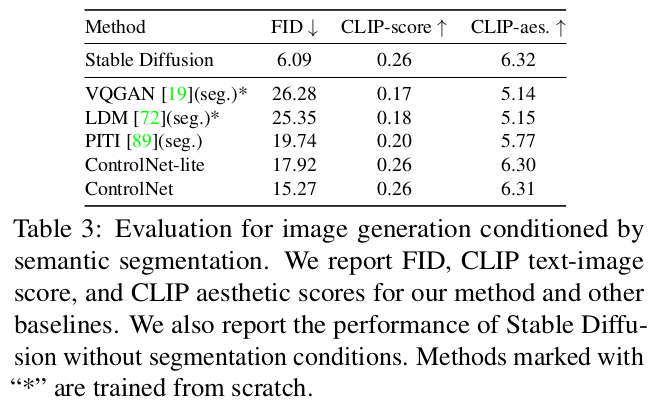  |
 |
반응형