반응형
내 맘대로 Introduction

long audio + single image 로부터 long video를 만들어 내는 내용. 목적 자체는 가상 대화를 활성화할 수 있게 하는 것이다. 소리만 갖고 전화하는 것을 넘어서 적절하게 생성된 이미지로 영상통화를 하는 것처럼 만들어 낸다는 것이 궁극적 목표다. 그 초기 연구라고 보면 될듯.

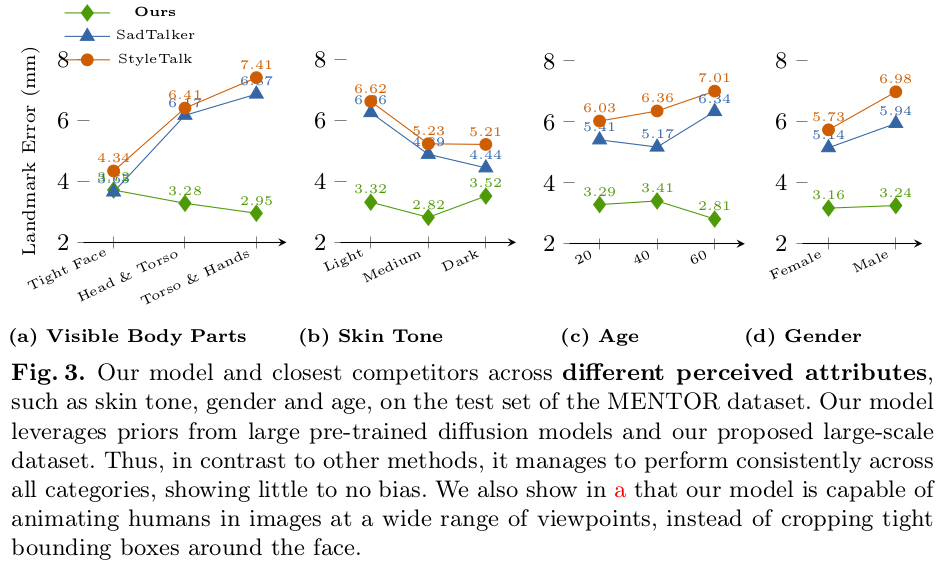
기존 연구는 소리랑 매치가 안되거나, 얼굴이 부자연스럽거나, 몸동작은 빠져있고, 자세 표현의 다양성이 부족하다는 것 등 하나씩 빠지는 점이 있지만 이 논문은 소리, 표정, 몸동작, 다양성까지 다 커버하는 것을 목표로 한다.
핵심은 역시나 diffusion이다.
메모
   |
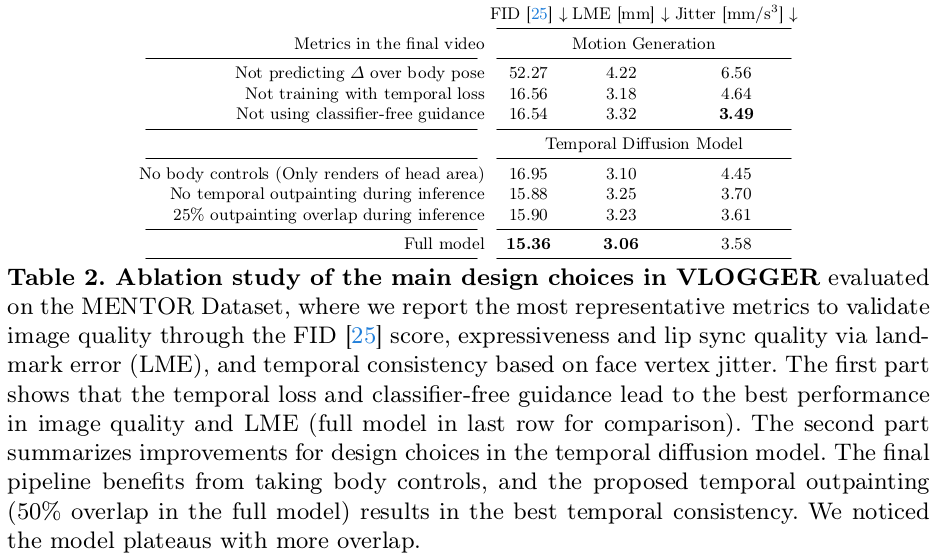
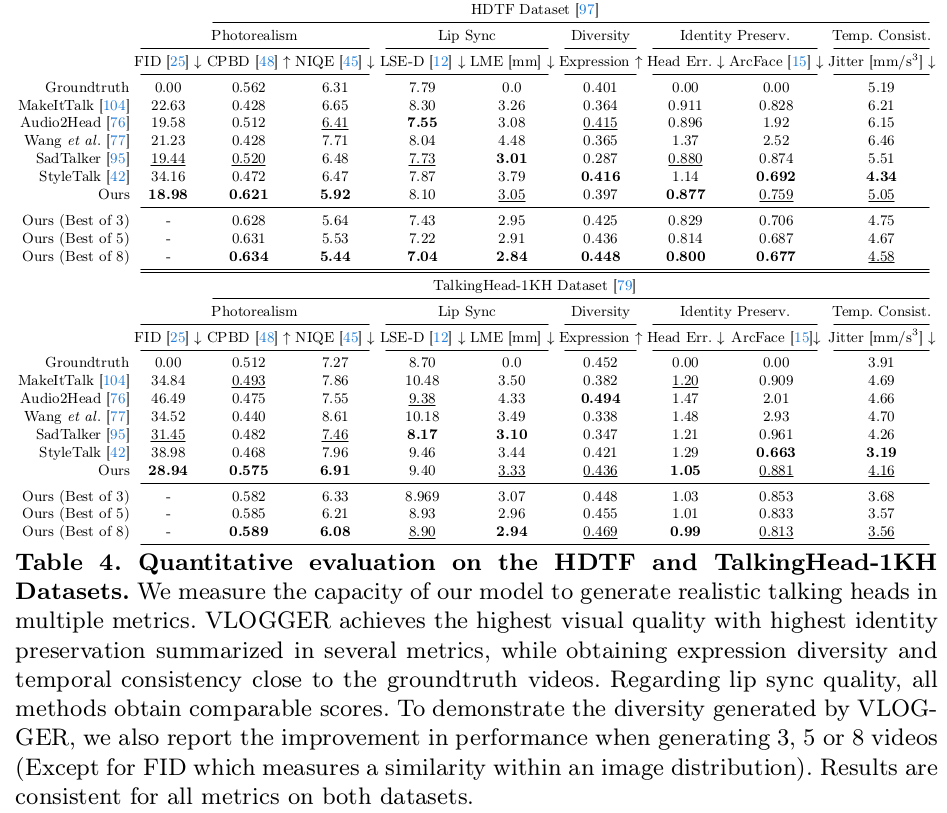
| 1) 소리에서 SMPL 파라미터 만들기 2) 입력 이미지에서 SMPL reference(특히 texture) 잡기 3) 소리에서 만든 SMPL 파라미터 + reference를 이용해 이미지, segmantic map 렌더링 4) diffusion 통과 |
  |
| 1) 소리에서 SMPL 파라미터 뽑는 네트워크는 트랜스포머임. |
 |
| SMPL 파라미터를 구할 때 residual 형태로 구하도록 했고 파라미터는 rendering을 거쳐 semantic mask로 변환됨. |
 |
| 입력 이미지에서 SMPL vertex color를 얻어올 수 있으므로 이를 가져와서 semantic rendered image 만들 듯이 rgb rendered image 만들어 둔다. |
  |
| 학습은 end-to-end기 때문에 뒤에 붙은 diffusion 모델에서 loss를 가져와 준다. 독특한 것은 frame 간에 diffusion step 마다 업데이트 되는 noise 비슷하도록 억제해서 consistency가 유지되도록 도왔다. |
 |
| 뒤에 붙는 diffusion model은 국룰대로 freeze 되어 있고 encoder만 따로 학습된다. |
 |
| 사전에 소리와 모션이 가미된 영상을 확보해두고 (SMPL도 얻어두고) 시작한 것. 학습 때부터 multi frame 다 넣으면 학습이 잘 안될 것 같았는지 single frame으로 웜업 후 전체 학습했다고 한다. |
 |
| pretrained DDPM은 Imagen 사용했다. |
 |
| 해상도 문제는 뒤에 super resolution용 diffusion model을 붙여서 해결 (pretrained를 가져와서 쓰다보니 어쩔 수 없었던 것 같다.) |
 |
| 학습용 영상의 길이가 한정되어 있는데 소리 길이가 길 경우 더 필요할 수도 있음. 이럴 경우 rendering 결과를 입력으로 다시 넣는 식으로 해서 계속 더 쌓아나갔다고 한다. |
 |
| 사용한 데이터셋 내용. 그냥 인터뷰 영상 같은 것 + SMPL 피팅 결과 |
 |
 |
 |
 |
 |
 |
 |
 |
반응형