반응형
내 맘대로 Introduction

ENVIDR, Neuralangelo 와 같이 반사 빛이 있는 물체의 복원을 어떻게 할 수 있을지 고민한 논문이다. 이름에서도 예측할 수 있다시피 VolSDF와 같은 NeRF 기반 아이디어이다.
핵심 아이디어는 기존 논문들이 specular,diffuse parameterization을 사용한 것과 달리, 그냥 아예 반사광만 따로 표현하는 MLP를 추가해버린 것이다. 어떻게 보면 수학 모델링이 들어가지 않았기 때문에 무식하다고 볼 수도 있지만, simple yet effective! 간단한 아이디어 하나로 훌륭한 결과를 냈기에 좋은 논문이라고 생각한다.
오히려 성능이 좋은 이유가, 모든 물체가 반사광 모델링이 필요한 것이 아닌데 일괄적으로 parameterization 해버리면 당연히 성능이 떨어질 것이다. 네트워크가 자체적으로 판단해서 필요한 부분만 반사광을 따로 배울 수 있도록 선택지를 열어주는 것이 더 효과적일 것 같다.
메모하며 읽기
 |
요즘 논문도 NeRF recap을 포함하는구나... 익히 알고 있는 내용이니 패스. |
  |
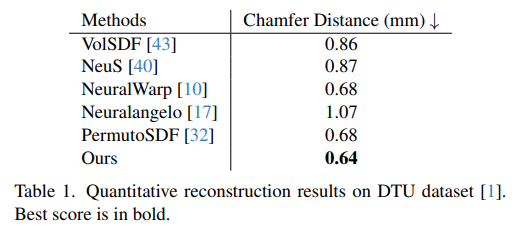
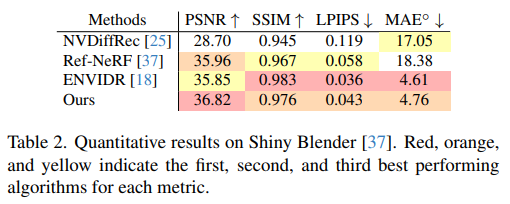
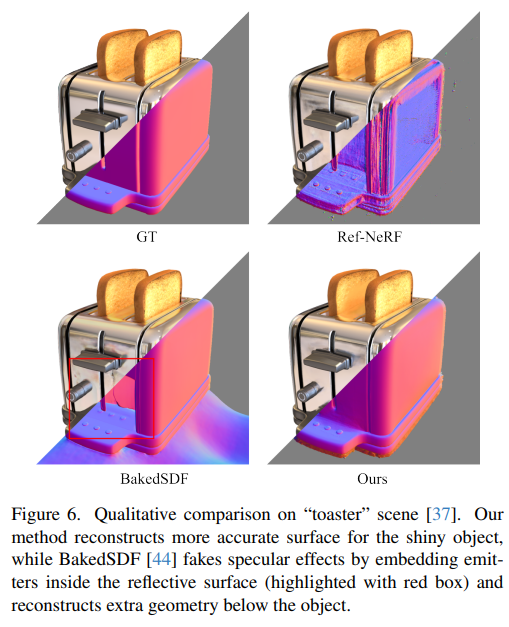
사실 이 그림 하나면 끝난다. Reflection이라고 적힌 부분과 weight MLP라고 적힌 부분을 제외하면 VolSDF와 정확히 동일하다. 데이터 표현법을 속도 문제로 인해 coarse-to-fine hash grid 구조를 쓴 것은 이제 더 이상 독특한 점이 아니다. 단 하나의 ray와 그 위의 점 x 한 쌍에 대해서 1개의 color만 찾는 것이 아니라 2개의 색상을 찾는 방식이다. 그 중 하나는 반사광, 나머지 하나는 본연의 색이다. 이 때 반사광은 물리적으로 입사각과 반사각이 같으므로 ray d 가 ray omega로 바뀌어져 들어간다. 네트워크는 x 위치 자체의 색상을 표현할 때 그냥 발산하는 빛과 튕겨져나가는 빛을 구분하도록 학습한다. 그러면 최종적으로 색을 1개로 어떻게 merge하는지? weight MLP가 두 색상의 조합비를 내뱉어준다. 반사광이 없다면 반사광 weight 0, 있다면 0~1 값. ---------------- 결과적으로 이렇게 설계하면 아무런 specular light에 대한 모델링 없이 네트워크가 자체적으로 데이터만 보고 빛을 분리해서 학습할 수 있게 된다! |
 |
 |
| 그외 기본적인 내용은 VolSDF를 차용함과 동시에 mip-nerf360과 같이 압축 공간을 사용했다는 점. | instant NGP 구조를 차용했다는 점은 특별한 것 없다. |
   |
반사광 모델링 파트도 사실 아이디어가 좋지, 구현은 간단하다. ray d와 point x가 주어졌을 때, 반사광 MLP는 그대로 입력으로 받진 않고 현 상태의 normal을 이용해서 ray d를 반사 ray w로 변환해주는 것이다.  specular만 고려한 이유는 diffuse까지 네트워크에게 맡겨버리니 망가졌기 때문이다. 추측컨대, specular는 입사각/반사각 처럼 물리적으로 확실하게 잡아주는 constraint가 없는데 diffuse는 그런게 없다보니 ill-posed problem이라 망가지는 것 같다. diffuse는 그냥 radiance color가 커버하도록 두는 것이 좋다고 한다. -----------  weight가 specular 영역을 나름 잘 분리하도록 학습이 되므로 간단하지만 효과는 좋은 방식! |
 |
raidance와 specular를 분리하는 weight 조차 아주 간단하다. 그냥 sigmoid이고 linear weighted summation이다. |
   |
 끄트머리에 왜 specular를 분리하고자 했는지, 왜 기존 parameterization과 다른 방식으로 했는지 설명하는데 그냥 1) specular 분리 안하면 망함 2) 근데 수학 모델로 분리하는 이전 것들이 다 잘 안됨. --> 네트워크한테 아예 맡기자. |
  |
 coarse to fine 학습이 필수라고 함. 내 생각에도 데이터는 똑같은데 2개의 color MLP가 균형을 맞춰서 학습돼야 하기 때문에 난이도가 훨씬 높아 학습 안정성이 떨어질 것 같다. |
 |
regularization도 2가지 정도 추가됐는데, 알고리즘 자체가 reflection 계산할 때 현 상태의 SDF로 만든 normal을 사용하기 때문에 normal이 절대적으로 안정적으로 학습되어야 한다. 따라서 normal을 안정화하기 위해서 현 SDF로 만든 normal이 다른 방식으로 계산한 normal과 일치하도록 보조한다거나 내부로 뒤집힌 normal이 없도록 막는 식의 regularization이 들어갔다. |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
반응형