반응형
내 맘대로 Introduction

요즘 segment anything 이후로 anything을 붙이는 것이 유행이 돼버린 것 같다. 이 논문은 대규모 데이터를 먹여 monodepth 성능을 끌어올린 논문이다. MiDAS와 사실 거의 비슷한 논문이라고 할 수 있는데 6200만장에 달하는 unlabeled data를 먹여서 성능을 어떻게 끌어올릴 수 있을지 고민한 차이점이 있다.
핵심 아이디어는, DinoV2 + depth를 teacher로 두어서 unlabeled data를 pseudo labeled data로 만들어 사용하는 것과,feature가 DinoV2 feature를 닮도록 regularization을 가해서 semantic prior를 잃지 않도록 하는 내용이다.
새로운 loss나 이론적인 내용이 추가되었다기보다 대규모 데이터를 먹이는 방법 + 이미 데이터를 먹은 foundation model 활용하는 방법이 핵심이다. 확실히 요즘 연구 트렌드가 데이터 싸움으로 더 치닫는 것 같다.

아예 목적을 설명할 때 "foundation model"을 설정하는 방법이라고 표현하니, depth estimation에 진심이라기 보다 데이터를 먹이는 방법에 진심인 것 같다.
메모하며 읽기
 |
|
 |
1) labeled data를 먹이는 방법 : MiDAS와 똑같이 normalized depth에 대해 l1 loss 2) unlabeld data를 먹이는 방법 : teacher model의 prediction 값을 pseudo label로 써서 l1 loss 3) 이 과정에서 encoder는 dinov2 feature와 가깝도록 계속 제한해줌 |
  |
내용은 길지만, labeled data에 대해선 MiDAS와 동일하다 median depth로 shift, variance(abs.ver)로 scale한 normalized depth 상태에서 직접 supervision을 가하는 방식이다. 데이터가 150만장 (6개 데이터셋 혼합) 이라는 점이 강조됨. 모델 구조는 DinoV2를 encoder로 사용했고, decoder는 뒤에 나오지만 DPT를 사용했다. 크게 독특한 점 없음.  사용된 데이터셋 종류. |
 |
unlabeld data도 일단 규모가 강조된다. 6200만장 데이터가 사용되었다. 목록은 위 테이블 1 참고. |
  |
pseudo GT를 만들어 낼 teacher model이 존재해야 한다. teacher model은 직접 ViT-L encoder를 달아 학습한 모델 중 가장 성능이 좋은 것을 썼다고 한다. (labeled data로만 학습함) --- student 모델을 학습시킬 땐 teacher model weight에서부터 시작해서 fine tuning 컨셉으로 가면 성능 하락된다는 결과가 있어 scratch부터 학습함. |
 |
pseudo GT로 학습시키는 과정에서 teacher와 student가 같은 데이터를 먹으면, 구조도 비슷하기 때문에 결국 teacher와 완전히 동일한 결과에만 수렴했다고 한다. unlabeld data를 더 먹으니 더 좋아지길 기대하고 있는데 말이다. 따라서 이를 좀 파훼하기 위해서 unlabeld data를 사용할 때 teacher 한테는 원래 그대로, student한테는 두가지 방식으로 augmentation 데이터를 먹였다고 한다. 1) color distortion, jittering이나 blurring한 것 2) cutmix :간단히 말해 다른 이미지랑 타일 단위로 바꿔치기하는 식. |
  |
cutmix를 조금 더 보면 이미지 A와 이미지 B를 타일 단위로 서로 바꿔치기해서 부분적으로 생뚱맞은 이미지 타일이 붙어있도록 바꾼 것이다. 무슨 효과가 있는지 여기서 설명하진 않지만, 이미지가 context를 분리해서 배우는데 도움이 될 것 같긴 하다. loss는 바꿔치기 안된 곳 끼리, 바꿔치기 된 곳 끼리 비율에 맞추어서 pseudo GT와 비교하는 방식. |
  |
기존 논문들(foundation model research)에서 semantic segmentation에 관여하는 feature를 활용하면 depth가 성능이 올라간다는 보고가 있었다. 따라서 semantic segmentation에 필요한 feature도 같이 뽑을 수 있도록 했다. 맨 처음에는 segmentation head를 학습 시에만 달아서 같이 학습시킨 다음 떼어내는 식으로 해서, semantic feature도 암묵적으로 배우도록 했는데 성능이 안좋았다고 한다. 그래서 그냥 DinoV2가 semantic feature를 잘 뽑는 모델이니 DinoV2 feature를 닮도록 계속 강제하는 식으로 구현했다고 한다. -------------------------- encoder output이 dinov2 feature와 cosine similarity가 높도록 강제했다. |
 |
약간의 분석이 들어갔는데 dinov2 feature를 보니 semantic prior가 워낙 잘 학습되어 있어서 대상이 같다면 무조건 비슷한 feature가 나오는 경향이 있었다고 한다. 예를 들면, 차 앞과 차 뒤는 차라서 feature가 같은 것이다. 이런 경향은 앞, 뒤가 철저히 다른 depth에서는 오히려 방해가 될 것이라고 분석했다. 그래서 cosine similiarty가 특정 값 alpha 이상만 되면 무조건 1이 되도록 하지 않았다. 최대 alpha까지만 비슷해지도록 강제한 셈이다. (약하게) |
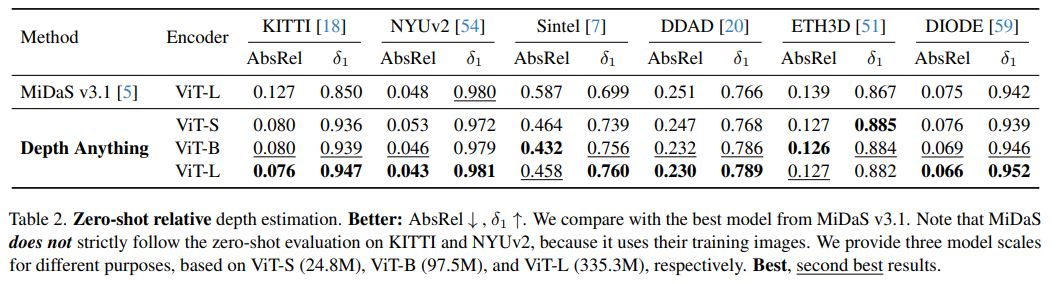 |
|
 |
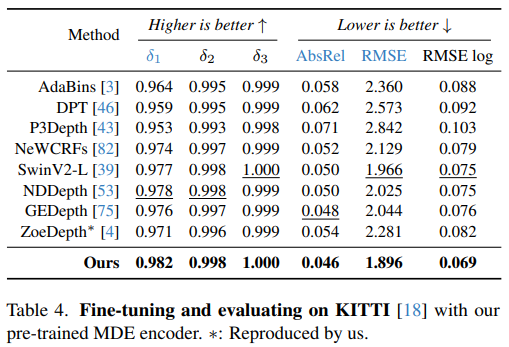 |
 |
 |
 |
 |
 |
 |
반응형