반응형
내 맘대로 Introduction

최근 scene coordinate regression이라는 흥미로운 분야를 보고 좀 찾아보기 시작했는데, 이 논문이 많이 인용되어 있길래 읽었다. 입력 이미지의 camera intrinsic과 depth ambiguity는 신경쓰지 않고 2D image to 3D point로 바로 regression하는 task다.
말이 되나 싶지만 요즘 data 빨로 2D-to abs.3D 컨셉의 논문이 워낙 잘되는게 많다 보니 이것도 되나보다. 더욱이 요즘 foundation model같이 데이터를 무한정 먹고 학습된 모델에서는 어이없을 정도로 잘 되는 결과도 있다. 따라서 직관적으로는 이해가 안되지만 데이터가 지배하는 시대에 데이터로 해결된다는 것을 보였기에 조금 다시 볼 필요가 있는 것 같다. camera intrinsic에서만 해방되어도 비전 알고리즘의 편의성이 비약적으로 올라가기 때문에 되면 정말 좋은 컨셉.
2020년 논문이긴 하지만 많이 옛날 논문 느낌이라 기록만 하고 넘어간다. 핵심 아이디어는 CNN 기반으로 scene coordinate regression하면 이미지 전체보다 패치 단위로 할 때 잘된다는 결과가 있는데, 이를 coarse-to-fine으로 이어 붙여 이미지 전체에서도 잘되기 만든 것이다. 이론적 내용, loss 설계보다 파이프라인이 더 중요한 논문이라 내용 자체는 아주 간단함.
메모하며 읽기
 |
|
| 이 논문은 입력 RGB - 출력 3D point인 간단한 구조로 image-3d point gt pair가 무수히 많을 때 그냥 학습시키고 끝이다. 다만 여기서 어떤 네트워크 구조가 효율적인지 탐색하고 중간에 간단한 트릭을 넣는 것 차이다. 핵심은 그냥 네트워크 구조다. |
|
  |
  |
| 1) image pixel - 3d point gt를 해상도를 낮춰가면서 pair로 준비한다. 2) 각 coarse level은 3d point를 뽑는 구간(3x3 conv) + label map을 뽑는 구간(1x1) conv으로 구성 되어있고 마지막 fine level에서만 3d point를 뽑는 구간(3x3 conv + 1x1 conv)로 구성되어있다. 3) label map 구간은 coarse level에서 feature를 가져와서 사용하는 구조. label map은 사전에 3d point cloud를 clustering해서 그룹핑해둔 것은 gt로 사용하여, 네트워크가 주어진 이미지를 알아서 구역화하고 각개 격파하도록 유도하는 것. coarse label과 fine level은 서로 연관은 없다. 그냥 feature에서 서로 얽힐 뿐. |
label map은 이미지를 네트워크가 알아서 구역화한 결과라고 볼 수 있는데 이걸 finer level로 넘겨줄 때 한 번 encoding을 거친다. feature level에 곱해진 (H, W, C) 크기의 scale과 shift로 encoding된다. finer level의 3d point뽑는 구간(3x3 conv) 뒤에 바로 들어가기 때문에 의미적으로, coarse level에서 scale shift를 가져와 초기값을 쉽게 잡는 것과 비슷하다. ------------------- 사전에 결정한 cluster 범위 안에서 classification하는 것이므로 label map은 (H, W, C)여야 일 것 같은데 (H, W, 1)인 이유는 argmax를 취했기 때문이다. supplementary 보면 argmax 적혀있음. |
  |
network backbone을 어떤 것을 썼는지는 사실 이 시점에서 중요한 것 같진 않다. loss function도 별도의 normalization 없는 real 3d point xyz를 직접 l1 loss로 제공 label map loss의 경우 CE loss인데, (H, W 1) label map 레벨에서 적용하는 것이 아니라 argmax 전 (H, W, C)인 레벨에서 적용한다. (이게 안적혀있어서 조금 헷갈렸음) |
 |
|
 |
 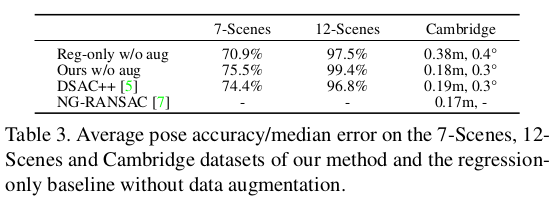  |
 |
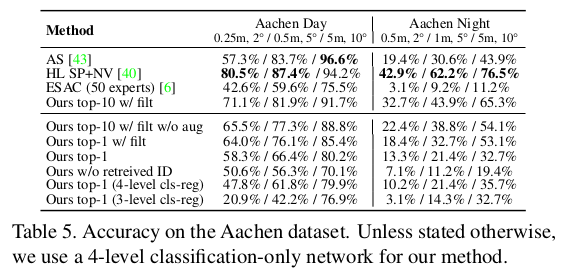 |
| 이게 되나 싶은데 데이터의 힘이 뭔지.. 되긴 된다. 이게 현재 foundation model로 넘어와 데이터를 무한히 먹은 경우에 더 잘된다. 이런 컨셉도 데이터가 늘어나니 의미를 갖는게 신기하다. | |
반응형
'Paper > 3D vision' 카테고리의 다른 글
| Compact 3D Gaussian Representation for Radiance Field (0) | 2024.01.16 |
|---|---|
| PhysGaussian: Physics-Integrated 3D Gaussians for Generative Dynamics (0) | 2023.12.20 |
| COLMAP-Free 3D Gaussian Splatting (0) | 2023.12.18 |
| Gaussian Splatting SLAM (0) | 2023.12.18 |
| Gaussian Grouping: Segment and Edit Anything in 3D Scenes (0) | 2023.12.13 |