반응형
내 맘대로 Introduction

이 논문은 3DGS의 문제점인 저장용량 문제를 풀고자 한 논문이다. 저장 용량을 줄이는다는 것은 성능은 유지하면서 Gaussian의 개수를 줄인다는 말이고, 개수가 줄어들면 필연적으로 렌더링 속도도 늘어나기 때문에 결국 속도와 저장 용량 문제를 같이 푸는 것이 된다.
LightGaussian과 유사한 부분이 있다고 볼 수 있는데, gaussian pruning을 visibility check로 보강한 것이 아니라 learnable mask를 통해 보강한 것은 완전히 다른 부분이고 codebook을 이용해 저장 용량을 줄이는 방식도 VQ가 아닌 R-VQ로 한 부분이 다르기 때문에 차이는 분명한 것 같다. 개인적으로 설명이 더 친절하게 되어 있어서 이 논문이 참고하기 좋음.
코드 역시 잘 정리된 편이다.
메모하며 읽기
 |
3dgs recap 부분 (생략) |
 |
|
  |
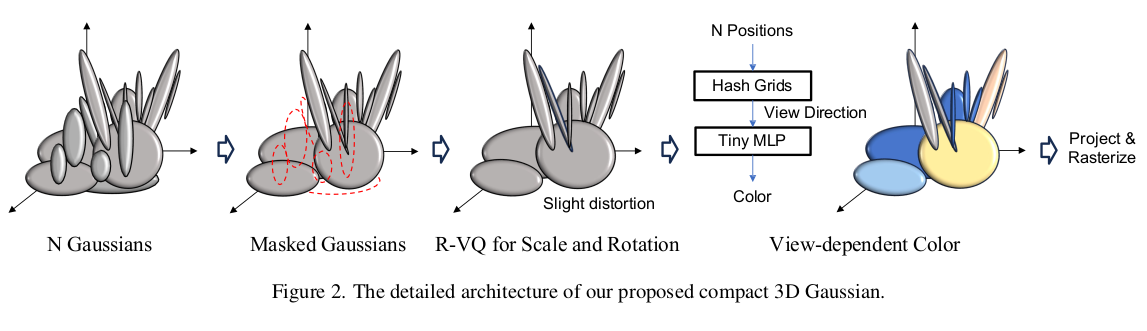
1) gaussian의 수를 줄이고 (masking으로) 2) 저장할 때 vector quantization해서 용량 줄인다. 이 두가지가 핵심 아이디어다. 저장 용량 중 가장 많은 부분을 차지하는 SH coefficient를 줄이기 위해 NeRF와 같이 view-depedent color MLP를 추가한 부분이 독특하긴 하다. |
  |
gaussian을 살릴지 죽일지 결정하는 마스크는 gaussian의 scale와 opacity로 결정한다. 직관적으로도 크기가 너무 크거나 작은 경우, 너무 투명할 경우가 걸러내야 할 대상이라고 생각할 수 있으니 말이다. thresholding을 가하면 성능 하락이 너무 걱정되니, gaussian 마다 learnabel mask paremeter, m 을 부여해서 사용했다. 수식(1)과 같이 sigmoid(m) 이 특정 기준 이하일 경우 opacity가 강제로 0이 되도록 하는 방식이다. 여기서 "특정 기준"이 역시나 사람이 정하는 threshold니까 뭐가 다르냐고 할 수 있는데 threshold에 맞춰서 네트워크가 m space을 조절할 수 있는 자유도가 있으니 다르다. -------------- 추가로 scale용 m, opacity용 m 따로 두어보기도 했는데 공유하는게 더 나았다고 한다. ------------ 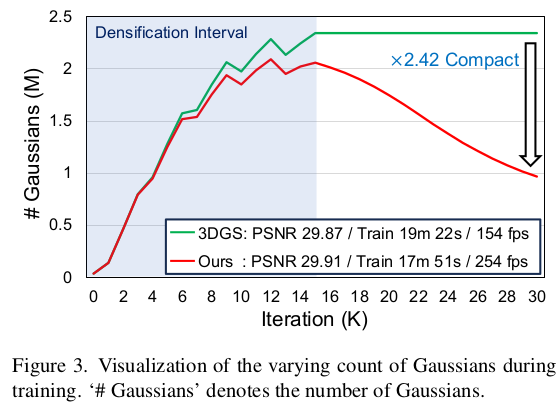 결과적으로 2배 이상 gaussian 수를 줄일 수 있었다고 한다. |
 |
구체적인 학습 loss도 간단하다. mask가 웬만하면 0이 되도록 강제하는 것이면 충분하다. 기본이 0이 되도록 하는 와중에 살아남아 성능은 유지해야 되므로 정말 유효한 gaussian만 살아남는 식으로 최적화된다. ++ 저장할 때 mask parameter, m은 저장 안해도 된다. 학습 시 pruning에만 사용된다. |
 |
|
  |
파라미터 저장은 R-VQ를 사용했다. codebook 만들어두고 index만 저장하는 식으로 해서 저장해야 되는 숫자를 폭발적으로 줄이는 방식이다. 다만 codebook 1개로 끝내는 VQ와 달리, residual codebook을 따로 만들어서 N번 반복하는 R-VQ를 사용해서 정보 손실을 최소화했다. 마치 PCA한 뒤, eigenvalue를 1개 쓰는 것보다 2개 쓰는 것이 정보 손실율이 더 적듯이 R-VQ도 codebook + residual codebook + residual codebook +... 여러개를 쓰면서 손실율을 줄일 수 있다. stage가 많아지면 이에 비례해서 저장해야되는 index가 늘어나니 저장용량 손해라고 볼 수도 있지만 index는 int8~16으로 저장할 수도 있고 stage를 적게 가져가면 전혀 문제 될 수준은 아닐 것이다. |
 |
학습 방식은 수식(6)와 같다. 이전 stage까지 사용해 복원한 code와 원본 code간의 차이 (=현 stage까지 남아있는 residual)이 현 stage의 codebook과 차이가 적도록 유도한다. 현 stage codebook 전체랑 비교하는 것은 아니고 argmin으로 가장 차이가 적은 code랑만 비교한다. ------------ 수식(6)이 rotation만 적었는데 scale은 같은 방식으로 따로 해준다. |
  |
color는 SH를 활용하는 방식을 포기하면서 용량을 확보하지만 여전히 view-dependent color는 만들고 싶기에, NeRF color network를 가져온다. gaussian의 원점을 던져주고 view direction을 넣어주면 해당 gaussian의 color를 뱉어주는 방식이다. MLP를 N개 gaussian에 계속 태워야 하니까 속도가 느려지는 것이 아니냐, NeRF만큼 느려지는 것이 아니냐 할 수 있는데 pixel 개수에 비하면 gaussian 개수는 터무니 없이 작기 때문에 그렇게 느려지지 않는다. 한 batch로 처리가 가능할 수준일 수도 있으니까. color network는 속도를 그래도 신경쓰긴 하려고 instantNGP와 같은 hash grid representation을 사용하는 방식으로 구현했고, 커버하는 공간 문제는 mip-NeRF360과 같이 공간을 압축하는 방식으로 구현했다. ------------- 색깔은 정의할 때 RGB 보다는 0-degree SH coefficient썼다고 한다. 개수 똑같으니 용량 차이는 없지만 성능이 조금 더 나았다고 한다. |
 |
codebook부터 gaussian paremeter, 특히 mask parameter까지 전부 동시에 학습된다. codebook을 형성해나감과 동시에 mask 추론 능력도 학습하고 결국 compact gaussian set을 획득하게 된다. |
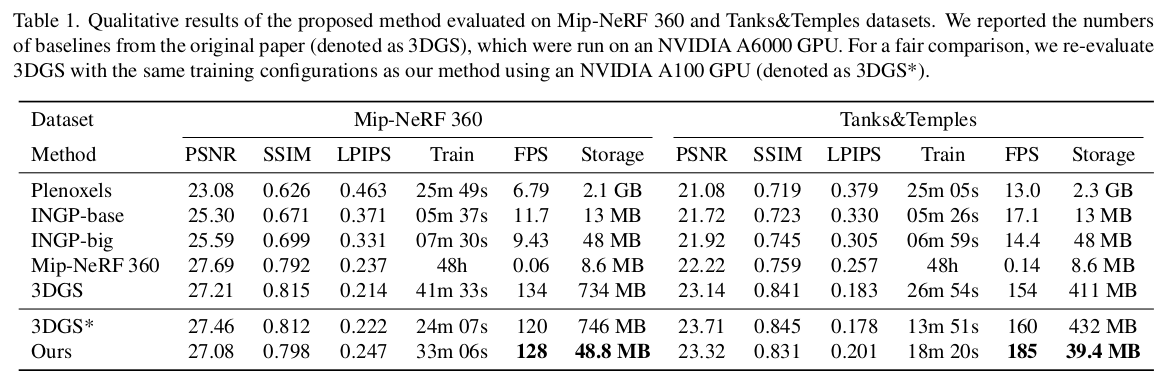 |
|
 |
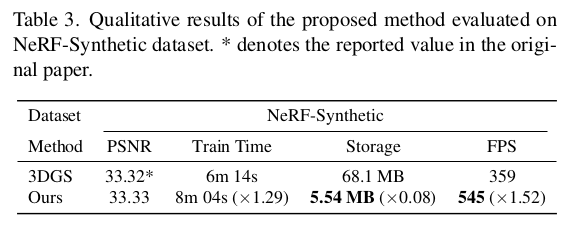 속도 느려지는 걸 그래도 걱정하긴 했는데 오히려 빠르다고 하니 신기. large scale scene에서는 문제가 다를 것 같아서 그 때도 이 방식이 제대로 동작할 지는 의문이다. |
 |
 |
반응형