반응형
내 맘대로 Introduction

4D gaussian에 이어 dynamic 3D GS 논문이다. 뭐가 먼저 나왔는지는 모르겠지만 NeRF에서 그랬듯 time dimension을 추가하는 방향으로 생각하는게 모든 사람이 똑같은 것 같다.
이 논문은 내가 생각하기에 계란 후라이도 아니고 반숙 후라이 논문이라고 부를 수 있을 정도로 3DGS 논문 나오자마자 바로 가스불 켜서 가장 간단한 아이디어 붙여서 구현한 논문인 것 같다. 아이디어적 contribution은 크게 없어보이고 그냥 누구보다 빠르게 구현해서 논문화했다는 점이 존경스러울 뿐이다.
NeRF에서 그랬듯이 time, t 를 encoding해서 사용하는 방식을 택했는데 이 time encoding MLP가 implicit 한 방식인데 explicit 3D GS에 섞었다는 것이 약간... 다시 굳이 implicit으로 돌아가는 것 같아서 모순되는 느낌을 받았다. 기능은 한다고 해도 좋은 방식은 아닌 것 같다.
학술적 가치는 그렇게 크지 않은 듯!
메모하며 읽기
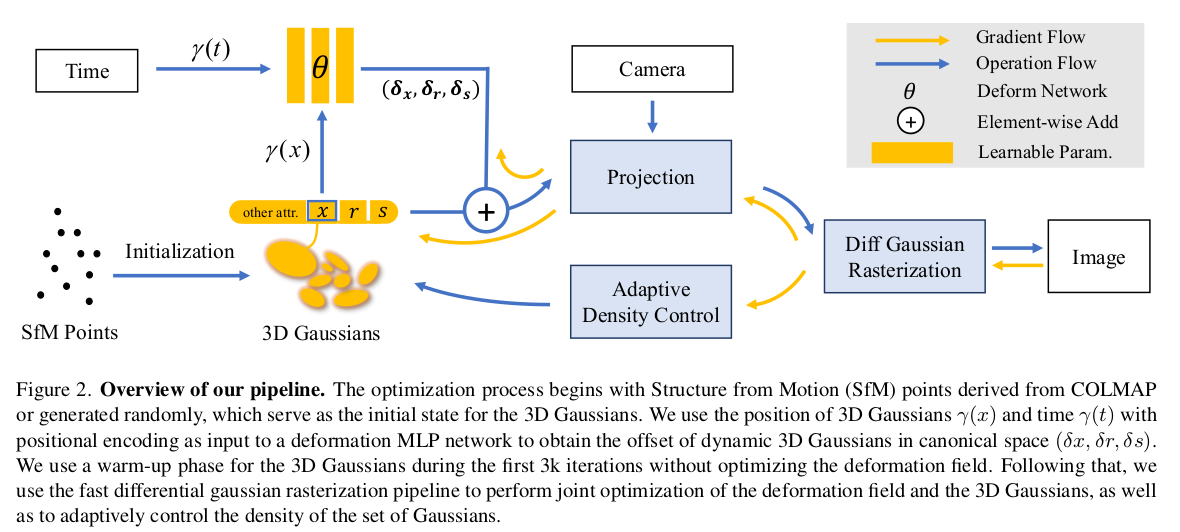 |
|
  |
그림으로 내용이 끝이라서 설명하기가 애매할 수준... 3DGS 똑같은데 생성된 3d gaussian의 position x와 time, t를 입력으로 받아 3d gaussian의 position, rotation, scale residual을 뱉는 MLP를 추가한 점이다. ---- 여기서 주목할 점은 3d gaussian 단위로 한 것이 아니라 3d gaussian의 position 정보 xyz만 사용했다는 점이다. 그러면 MLP 입장에서는 이게 3d gaussian 단위가 아닌 연속 3차원 공간 상의 한 점 + 시간을 받는 것이니 그냥 implicit function이다. MLP는 3d gaussian이라는 개념 자체를 아예 모르고 학습 될 뿐인 것이다. 따라서 MLP가 커버할 수 있는 공간 한계도 NeRF처럼 그대로 있을 것이고 이미지도 많아야 하고 공간도 타이트해야 하고.. 여러 제약 조건이 생기는 것 같다. 컨셉도 모순적이고 3D GS의 장점이 죽는 방식이라 아쉽다. |
  |
 |
| 그냥 3D GS 논문 복붙. 심지어 파라미터도 같다. | |
  |
position, scale, rotation residual 계산해주는 MLP는 입력으로 positional encoding된 xyz, t를 받는다. 특별한 것 없음 ㅠㅠ (진짜 날먹) |
  |
hypernerf에서 언급된 바와 같이, 시간을 너무 정직하게 끊어서 학습시키면 중간 시점 이미지가 뭉개진다는 이야기가 있다. 이를 완화하기 위해서 학습 시 time, t에 pertubation을 추가해서 학습했다는 이야기 pertubation은 학습이 진행될수록 크기가 줄어들게 설계했다. |
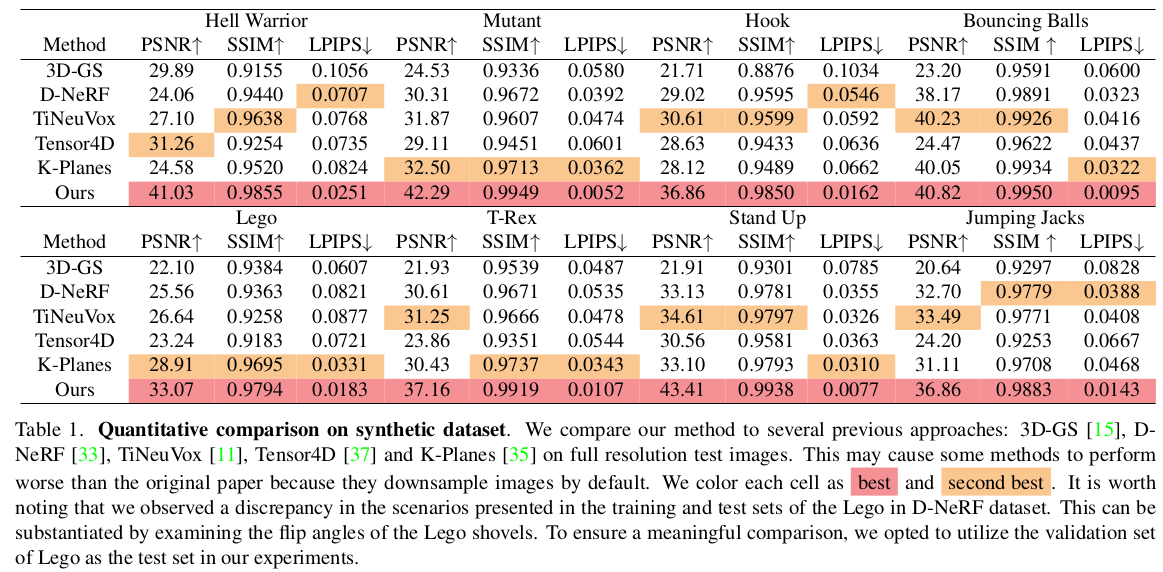 |
 synthetic으로만 실험한 것도 아쉽다... 진짜 빠르게 쓰는데만 초점을 둔 것 같은 느낌을 지울 수가 없음. |
 |
|
 |
 |
반응형
'Paper > 3D vision' 카테고리의 다른 글
| HexPlane: A Fast Representation for Dynamic Scenes (0) | 2023.11.14 |
|---|---|
| Dynamic 3D Gaussians : Tracking by Persistent Dynamic View Synthesis (0) | 2023.11.14 |
| Hierarchical Prior Mining for Non-local Multi-View Stereo (0) | 2023.11.09 |
| ACMP - Planar Prior Assisted PatchMatch Multi-View Stereo (0) | 2023.11.08 |
| ACMM - Multi-Scale Geometric Consistency Guided Multi-View Stereo (0) | 2023.11.08 |