내 맘대로 Introduction

이 논문은 이전 논문 [ACMM]의 확장판이다. 정확히는 ACMM + planar prior를 이용한 추가 optimization이 끼는 구조로 뒤에 이어 붙이는 식의 확장이다.
핵심 아이디어는 다음과 같다. ACMM을 돌리면 textureless region을 제외한 웬만한 영역에서 3d point가 잘 나와주는데 이걸 reprojection에서 이미지에 내려찍은 뒤, anchor처럼 이용하여 2d triangulation을 한다. 그리고 가정하길, 2d triangulation으로 얻어진 삼각형 하나하나는 평면으로 간주되다는 것이다. 이러한 가정을 cost function에 추가해서 다시 한 번 최적화를 돌려주는 것이다.
이걸 이용해서 비어있던 공간이 완벽하게 채워지고 그런 것은 아니지만 적어도 ACMM으로 값이 채워진 영역 부근에서는 이러한 planar prior를 이용해 조금 더 채워지는 현상이 있을 것이다. 혹시 모든 형상을 평면으로 가정해버리면 오히려 ACMM 결과가 망가질 수 있지 않느냐고 지적할 수 있는데 2d triangulation 특성 상 dense pose 주변에는 작은 삼각형이 여러개 형성되기 때문에 충분히 작은 평면이므로 어느 정도 커버된다고 한다. texture-less region이 큰 삼각형으로 처리되는 것이 더 큰 메리트.
하나 아쉬운 점은 최적화가 여러 번 돌아야하는 구조이기 때문에 속도는 살짝 신경쓰지 않은 느낌이 난다는 것이다. 어차피 오프라인으로 돌릴 것이긴 한데 너무 sequential 하게 도는 느낌이 있다.
메모하며 읽기
 |
|
  |
전체 입출력은 모든 MVS가 그렇듯 동일하다. 이 ACMP만의 독특한 구조는 다음과 같다. ACMM을 먼저 돌리기 (a->c) -> 2d triangulation (c->d) -> planar prior 넣어서 최적화 한 번 더 돌리기 (f, g) |
  |
planar model은 2d triangulation 결과로 나오는 vertex를 3개를 한 묶음으로 (삼각형 단위로) 모아서 해당하는 pixel들을 묶어두는 것이다. 그리고 같은 planar model에 속하는 pixel들은 3d 상에서 같은 평면 위에 위치하며 특히 같은 normal을 같는다고 정의하는 것을 말한다. |
 |
ACMP는 cost function에 planar prior가 반영된 것이기 때문에 전체 흐름도는 ACMM 즉 이전 흐름과 비슷하다. 차이점만 짚으면 다음과 같다. ACMM 끝나고 2d triangulation까지 끝났다고 가정했을 때다. 아예 처음부터 다시 시작한다. random initialization에서 픽셀마다 3d plane, depth, normal을 할당하고 초기 matching cost 역시 top k 를 선별해서 aggregation하는 방식 동일하다. 다만 자세히 기록되어 있진 않지만 모든 픽셀에 개별적으로 할당하긴 하지만 2d triangulation에서 같은 planar model로 묶이는 pixel들은 같은 값을 공유하도록 constraint를 가해주는 것 같다. 그리도 depth, noraml 초기값도 굳이 무작위 값으로 할 필요없이 가능하다면 ACMM 값으로 채워두었을 것으로 예상된다. --- propagation의 경우, ACMM과 완전 동일하다. adaptive checkerboard sampling 이나 hypothesis 8개 사용하는 것 동일하다. |
  |
cost function 정의하는 부분인데 큰 틀은 역시 수식(1)과 같이 ACMM 것과 동일하다. 하지만 여기서 m이 더 이상 photometric consistency로만 이루어진 것이 아니라 photometric consistency + planar prior가 추가된 형태라는 것이다.  m을 단순히 photo + lambda * planar로 할 수도 있지만 알고리즘이 선택적으로 골라야 texture가 있고 없고에 따라 비중을 조절할 수 있으므로 확률적으로 모델링한 것이 특징이다. 수식(2~5)가 복잡하긴 하지만 핵심은 수식(4)로 그 의미는, matching cost = photo.consistency * hypothesis 선별 로 정의할 것이고 8개의 hypothesis 중 planar prior에 가장 잘 맞아떨어지는 hypothesis를 골라주는 식으로 planar prior를 matching cost에 넣어준다(하나만 골라준다고 생각할 게아니라 확률로 모델링했기 때문에 가장 높은 애가 비중이 높고, 낮은 애가 비중이 낮게 된다.) (원래는 hypothesis 고를 때 역시나 photo. consistency가 가장 좋은 애를 골랐으나, 이제는 planar prior 로 선별하는 느낌) |
  |
hypothesis 중 planar prior가 가장 잘 맞는 것을 고르는 로직(확률)은 수식(6)과 같이 정의했다. hypothesis의 depth, normal이 현 pixel의 depth, normal과 가까운지 계산한 값이다. 이걸 수식(4)에 넣어주면 되는데 log를 취해 수식(7)과 같이 변형된 것이다. ----- planar prior가 안 맞다면, photo consistency로만 업데이트될 것이고, photo consistency가 큰 변화가 없다면 planar prior로만 업데이트 될 것이다. |
  |
남은 view selection은 ACMM에서 hypothesis마다 모든 view에 대해 matching cost를 계산하는 트릭을 구사했지만 ACMP는 hypothesis 중 planar prior가 높은 hypothesis를 선발하는 개념이기 때문에 다시 ACMH로 롤백한 느낌이다. 수식(9)는 ACMH와 같이 그냥 matching cost를 표현한 것이고 단순히 뒤에 visibility만 구해서 view를 골랐다. (역시 확률적이기 때문에 특정 view가 버려지진 않는다 비중이 낮을 뿐) 즉, matching cost 낮고 visibility 확보된 view를 그냥 쓰는 것인데 top k개 아니고 이젠 확률적으로 다룬 것이다. ---- Note 확률적으로 view selection을 하기 때문에 버려지진 않겠으나 구현적으로는 그래도 N개 지정해서 최적화를 돌려야 하긴 한다. 이 때는 N개 view 중 계산했던 확률에 따라 sampling해서 사용했다. 무수히 많이 돌리다 보면 통계적으로 확률 분포에 맞게 view를 사용한 것이다. |
   |
refinement, geometric consistency, fusion은 ACMM과 동일하다. depth, normal에 random혹은 pertube augmentation을 가하고 우연히 cost가 줄어들면 업데이트하는 방식. reprojection error를 matching cost에 추가해서 사용하는 방식이다. reprojection error평가하면서 단일 pcd화하는 것. |
 |
 |
 |
 |
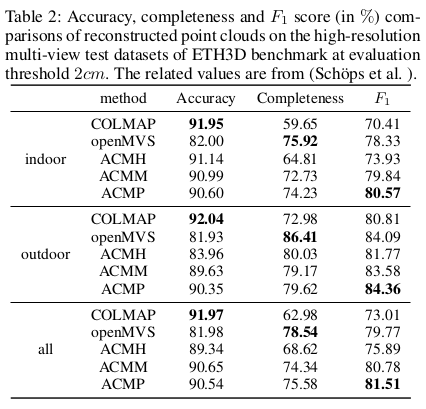 |
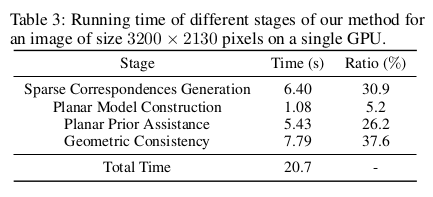 |