반응형
내 맘대로 Introduction
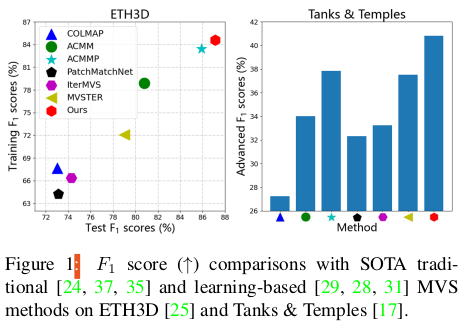
이 논문은 ACMM, ACMP, ACMMP의 저자의 후속 연구로 봐도 무방할 것 같다. 2저자로 Qinshan Xu가 있는 것과 논문 구조, 그림만 봐도 거의 ACMP++이다.
핵심 아이디어는 patchmatch stereo pipeline을 그대로 가져가되 neighbor를 정의하는 방식을 좀 더 dynamic하게 변경해서 좁게 보아야 할 때는 좁게, 멀리 보아야 할 때는 멀리 볼 수 있도록 했다. 이렇게 변경함으로써 얻는 장점은, 정적으로 neighbor를 정의할 경우, 멀리까지 탐색해야 할 때도 근처에서 탐색하면 local minima에 빠질 위험이 늘어나는데 동적으로 탐색하기 때문에 이런 문제가 완화된다. 또한 ACMP에서 최종 1번만 수행했던 planar prior assistance를 multi scale에 적용함으로써 더 강하게 포함시켰다.
여전히 딥러닝 방식이 아니라는 점이 강력한 논문.
메모하며 읽기
  |
patchmatch stereo recap 부분. ACMM, ACMP, ACMMP, HPM-MVS에서 반복돼서 같은 내용이 나온다. 그냥 읽어보면 될 부분. |
 |
|
| 전체 파이프라인은 위 그림과 같다. coarse-to-fine이 일반적인 것 같지만 여기선 fine-to-coarse-to-fine, fine-to-medium-to-fine 과 같이 반대방향으로 내려갔다 다시 올라오는 방식을 취한다. coarse scale로 내려갔다오면서 planar prior 정보를 가져오는 식이다. (plane은 coarse scale에서 찾을 때 효율이 좋으니) 핵심은 그림에 NESP라고 표시되어 있는 non-local extensible sampling pattern과 ACMP 방식에서 조금 더 나아간 planar prior 사용 방식이다. |
|
  |
먼저 NESP는 cost function을 정의할 때 사용하는 neighbor의 탐색 범위를 재정의한 것이다. 초창기에는 sequential, 이후에는 diffusion-like 방식으로 변해 다양한 디자인의 윈도우를 사용했었는데 공통점은 정적이라는 것이다. 디자인에 따라 특성이 고정되는 방식이었는데, NESP는 탐색 반경을 정하는 것까지는 정적으로 하되 그 반경 안에서 sampling을 하는 단계는 동적으로 설정해서 조금 더 adaptive하게 neighbor를 정의할 수 있도록 했다. 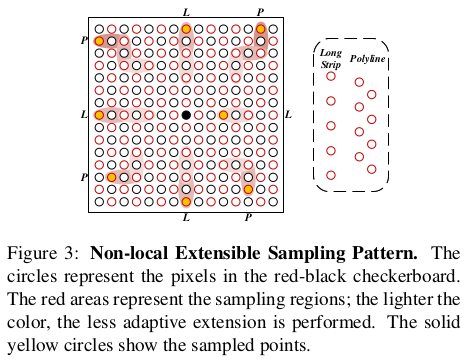 위 그림의 패턴처럼 십자가 모양으로 4 영역, 대각선 지그재그 모양으로 퍼지는 4영역까지만 정적으로 정해두고 그 안에서 sampling은 동적으로 했다. |
  |
각 영역 내 sampling하는 방식은 ACMP와 유사하게 시작한다. 일단 수식(1)과 같이 현 상태에서 가장 좋은 sampling을 영역 별로 뽑아 총 hypothesis 8개를 갖고 multiview cost를 계산해서 matrix를 만든다. 그 다음 각 hypothesis 별로 cost threshold 를 안으로 들어오는 good matching cost 개수를 센다. 만약 수가 적정 개수 밑이라면 미달 hypothesis가 속한 영역에서 2배수 hypothesis를 다시 생성해서 위 행위를 반복한다. (여기서 헷갈릴 수 있는 점이 초기에 matching cost 최소가 되는 hypothesis를 골랐는데 다시 뽑는다 한들 이보다 좋을 수 있는지 의문스러울 수 있다. 하지만 matching cost sum으로 본 것이랑 matching cost threshold 안에 들어오는 view가 많은 것이랑은 완전 1대1 대응이 아니므로 다시 뽑는게 의미가 있다. 특히 local minima일 경우!) 행위를 반복할 때마다 정확한 hypothesis가 등장해야 한다는 전제하여 수식(2)와 같이 matching cost threshold는 갈수록 타이트해진다. 결과적으로 8개의 hypothesis로 시작했지만 나중에는 영역 별로 Ni 개 씩 생성될 수 있어 훨씬 많은 hypothesis가 참여하게 된다. |
  |
그 의미를 되새겨보면, 현 pixel 위치의 비교 대상이 멀리까지 뻗어나갈 수 있도록 하는 것이다. matching cost만 보고 비교한다면 local minima에 빠져있을 경우 근접 영역에서 무조건 sampling 될 것이다. 하지만 matching cost voting으로 다시 뽑고 다시 비교하는 과정을 넣어줌으로써 근접 영역에서 벗어나 비교할 수 있는 기회를 몇 번 더 주는 컨셉이다. 따라서 local minima 극복 확률이 높아진다. |
 |
view selection과 refinement 스텝은 ACMM을 철저히 따른다. 수식(1)에서 만든 matrix를 이용해 top k view를 고르는 방식과 random/pertubed hypothesis들을 고의로 생성해 보정하는 방식 그대로다. |
  |
planar prior를 반영하는 방식을 일단 ACMP 방식으로 시작한다. 일단 앞서 만든 NESP를 이용해 patchmatch mvs를 돌리고 (ACMH 썼을 듯.) 그 결과 중 photo consistency가 우수한 pixel들을 anchor 삼아 2d delaunay triangulation을 돌린다. 여기서 얻어진 삼각형 영역들을 한 집합 단위로 묶어 plane parameter를 공유하도록 설정하는 것까지 동일하다. 하지만 이 결과를 보면 모든 anchor가 삼각형을 구성하지 않는 것을 볼 수 있다. 이 영역들은 사실 planar prior의 효과를 못받게 되는 영역이 되는데 이를 추가적으로 따로 집합 단위로 묶어주는 알고리즘이 추가되어 있다. 선택되지 못한 anchor들은 선택된 anchor 중 가장 photo.consistency가 우수한 우수 anchor에 top-K nearest로 할당된다. (삼각형으로 묶어야 하니 우수 anchor 1 + 비선택 anchor 2 로 3개씩 묶을 것 같다.)   우연히 3개를 묶었을 때 같은 line에 위치할 경우 삼각형을 이룰 수 없으므로 heron's formula로 넓이가 0 이상인지 확인하는 식으로 constraint를 걸어 집합을 묶어줬다. 새롭게 묶여서 만들어진 삼각형에 대해선 depth, normal을 수식(6)을 이용해 계산하여 해당하는 pixel들에 할당하는 과정을 거친다. |
  |
위 작업까지로 묶은 pixel 집합에 대해 planar prior를 가해서 한 번 더 최적화 해주는 과정을 거쳐하는데 이 때 multi-scale로 확장한다. 직관적으로 coarse scale에서 넓은 면적의 평면을 잡기가 더 쉬우므로 coarse scale 정보를 활용할 경우 textureless large plane을 좀 더 잡을 수 있다. 반대로 fine scale은 역시나 디테일을 잡는데 유리하다. 전체 과정은 coarse to fine이 아닌 fine to coarse to fine 형식으로 downsample하는 역방향 과정으로 이루어져있다. ----- 현재 fine scale에서의 hypothesis를 downsample해서 coarse scale의 hypothesis를 만들고 planar prior constructino 과정을 coarse scale에서 다시 수행한다. (fine scale 값을 initial로 사용하는 꼴) 그리고 나서 coarse hypothesis를 다시 upsample해서 fine scale의 초기값으로 사용해서 fine scale 최적화를 한 번 더 해준다. (fine 완성값이 coarse 초기값이 되고, coarse 완성값이 다시 fine 초기값이 되는 구성으로 두 scale 정보가 상호보완된다.) ----- 이 과정은 fine to coarse to fine, fine to medium to fine 이런식으로 2번거쳐 진행된다. --- planar prior 구체적인 적용 방법은 ACMP를 참고하면 되고 뒤에 geometric consistency guided도 ACMM, ACMP를 참고하면 된다. |
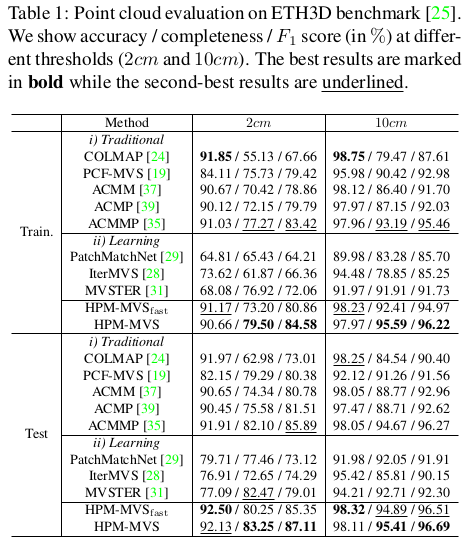 |
 |
 |
|
 |
 |
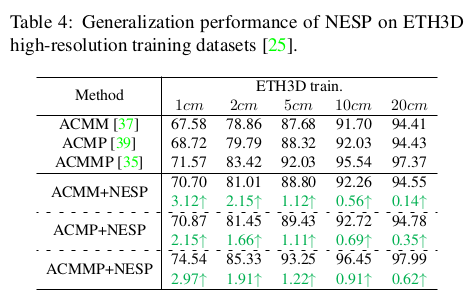 |
반응형