반응형
내 맘대로 Introduction

이 논문은 제목만 봐서는 3d gaussian splatting에 time dimension을 추가하는 논문 같지만 그런 내용이 아니다. 멀티 카메라 세팅에서 첫 프레임을 일단 static scene 복원하듯이 복원해서 3d gaussian들을 확보해두고, 고정한 뒤에 이를 t+1, t+2, t+3 ...에 대해 progressively optimize하는 논문이다.
달성하고자 하는 task는 다음과 같다. progressively optimize를 하는 과정에서 각 3d gaussian의 움직임을 파악할 수 있게 되는데 이 움직임을 전부 연결하면 trajectory가 되므로 특정 object의 dense trajectory를 얻을 수 있다. particle level tracking이 가능하다는 이야기다.
대상이 사람에 한정되어 있고 panoptic dataset처럼 사람 외에는 배경이 단조로운 특별한 세팅에서 구현한 것이라 범용성은 잘 모르겠으나 3d gaussian splatting을 이렇게도 활용할 수 있다! 를 보여주는 논문이라고 생각한다. 이론적 내용보다, 개발적인 내용이 더 강한 논문이다.
약간 계란 후라이 논문 느낌이 있다.
메모하며 읽기
    |
  |
  |
대부분의 내용이 3d gaussian splatting (이하 3DGS)로 가득 차있다. 수식은 그냥 3DGS 내용 그대로 적은 것이며 특별한 점은 단 하나도 없다. 기억해야 할 점은 비디오의 첫 프레임을 멀티 카메라를 이용해 static reconstruction하고 모든 3d gaussian들의 파라미터를 고정해둔 다는 점이다. 즉, 절대적으로 첫 프레임 복원 성능이 좋아야 하고 3d gaussian 개수도 넉넉히 나와줘야 한다. |
  |
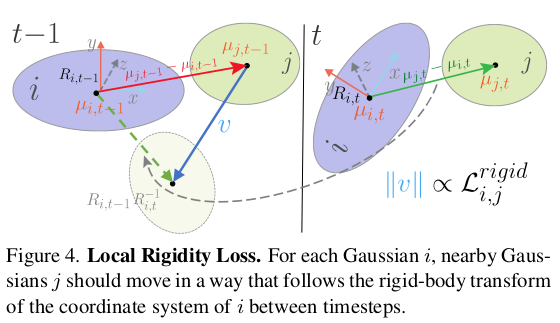 첫 프레임 (혹은 이전 프레임)을 기준으로 두번째 프레임(혹은 다음 프레임)을 최적화하는 과정이다. 이부분은 learning으로 해결한다기 보다 pytorch를 이용하지만 optimization에 해당한다. 먼저 각 fixed 3d gaussian 마다 rotation과 translation (R, mu)를 할당한다. (rotation은 center를 어디로 두든 똑같으니 당연하고, mu는 당연히 global coordinate다.) 그리고 neighbor 끼리는 rigid 하다는 가정, 즉 움직임이 비슷할 것이라는 가정 하에 rigid loss로 최적화한다. 그 의미를 보면 일단 이전 시점에서의 neigbor 간 거리와 다음 시점 (rotation, translation 반영된 후) neighbor 간 거리가 같도록 MSE loss를 걸어준다. 수식 상 뒷 부분의 R_i_t-1 @ R_i_t.inv 가 identity에 가깝게 나와야만 같은 거리가 유지되기 쉽고 실제로 mu_j_t - mu_i_t도 이전과 같아야 거리가 유지되므로 이전 시점과 유사하도록 강제한다고 볼 수 있다. -------------- neighbor를 정의하는 방법은 설명되어 있지 않지만 수식에 notation을 보면 knn으로 찾은게 보인다. k=20쓴 것 같다. |
  |
추가적으로 rigidity를 보조하기 위해서 rotation만, translation만 비슷하도록 강제하는 loss가 각각 추가된다. 먼저 rotation은 간단하다. (neighbor의 다음, neighbor의 현재 ) - (대상의 현재, 대상의 다음) 간 차이가 없도록 했다. 대상 3d gaussian의 rotation 변화량과, neighbor 3d gaussian의 rotation 변화량이 같도록 강제한다. 그 다음 translation은 더 간단하다. 첫 프레임에서 neighbor 간 거리가 매 시점마다 계속 비슷하게 유지되도록 강제했다. 즉 첫 프레임 복원 결과를 끝까지 유지할 수 있도록 강제하는 것이다. 각각은 neighbor 간 거리가 가깝고 멂에 따라 가중치가 곱해진다. |
 |
  |
| 개발 디테일인데 크게 3DGS 논문과 다르지 않다. 첫 프레임 이후 gaussian은 고정했다는 점, SfM point 대신 depth camera로 쉽게 갔다는 점. 중간중간 rotation SO3를 유지하기 위해 re-normalization을 추가했다는 점 정도다. 배경은 정적이기 때문에 배경에 해당하는 3D gaussian은 semantic mask로 분리해둔 뒤 rotation, translation 또한 고정되도록 했다고 한다. |
|
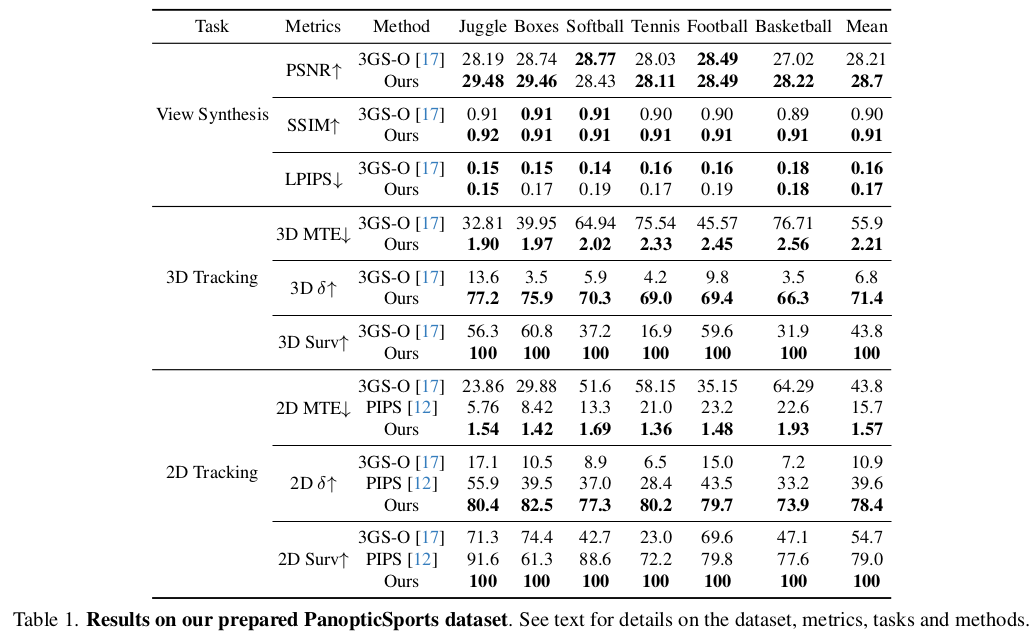 |
 |
 |
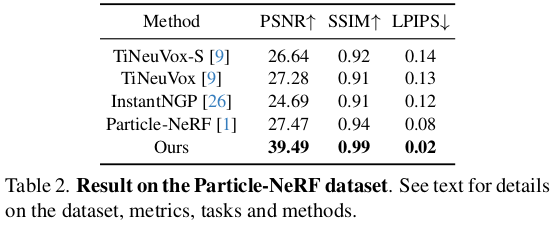
 동적 물체에 해당하는 3d gaussian만 분리할 수 있으면 제거가 쉽다. |
반응형
'Paper > 3D vision' 카테고리의 다른 글
| K-Planes: Explicit Radiance Fields in Space, Time, and Appearance (0) | 2023.11.14 |
|---|---|
| HexPlane: A Fast Representation for Dynamic Scenes (0) | 2023.11.14 |
| Deformable 3D Gaussians for High-Fidelity Monocular Dynamic Scene Reconstruction (0) | 2023.11.14 |
| Hierarchical Prior Mining for Non-local Multi-View Stereo (0) | 2023.11.09 |
| ACMP - Planar Prior Assisted PatchMatch Multi-View Stereo (0) | 2023.11.08 |