반응형
내 맘대로 Introduction
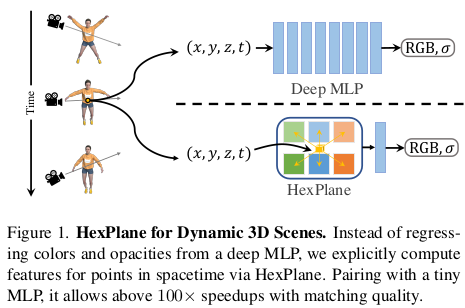
이 논문은 time dimension까지 추가해서 dynamic scene 복원을 하는 NeRF인데 TensoRF와 같이 데이터 표현법을 plane을 활용한 방식으로 변형해서 속도까지 향상시킨 논문이다. 기존 방식들에서 multi-plane, multi-grid 등 많은 형태가 있는데 이것들을 time dimension으로 확장시켰다고 보는 것이 맞을 것 같다.
3차원 x,y,z는 xy-yz-zx와 같이 나눴고 time은 완전 independent dimension이긴 하지만 앞선 spatial plane에서 하나 빠진 dimension과 엮어 xt, yt, zt로 나눴다. 따라서 이 6개의 평면을 조합하면 x,y,z,t 4차원 표현이 연속적으로 가능하게 되는 것이다.
신기한 것은 이 논문은 CVPR2023에 발표된 것인데 이름만 다를 뿐 내용이 완벽히 동일한 논문 K-Planes 이 또 CVPR2023에 공개되었다. 사람들 하는 생각이 진짜 똑같고, 아직도 NeRF 열기가 뜨겁다는 생각이 들었다.
메모하며 읽기
 |
|
 |
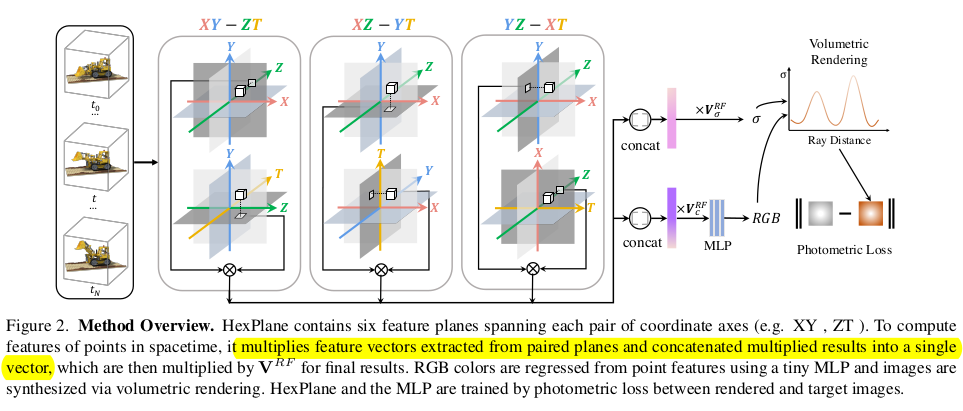
전체 파이프라인 그림은 위와 같은데 사실 그림만 봐도 무엇을 이야기하려고 하는지 단번에 알 수 있다. 3차원 공간과 시간 까지 합쳐 4차원 공간을 모델링할 때 4C2 개수로 나뉘어진 plane으로 모델링하겠다는 뜻이다. 공간을 기준으로 xy, yz, zx를 먼저 나누고 나머지 차원을 time과 묶어 zt, xt, yt로 나눠서 사용한다. query (x,y,z,t)가 들어왔을 때 각 해당하는 plane으로 6번 projection해서 얻은 feature로 하여금 최종 color와 opacity를 예측하는 구조다. |
  |
메모리/연산량 효율이 좋고 interpolation이 편하여 continuous 표현이 유리한 matrix -verctor representatino이 시발점이다. TensoRF에서 등장한 표기법인데 수식(1)과 같이 평면과 vector의 조합으로 표현하는 방식이다. TensoRF는 3차원 static scene이기 때문에 xy, yz, zx plane에 z,x,y vector로 구성되어 있다. (마지막 v_r^1과 같은 vector는 position indicator 정도로 생각함녀 된다. query로 들어온 위치!) |
  |
여기에 시간을 더하는 아이디어는 간단히는 N개의 plane을 time stamp마다 새로 만드는 것일테지만 이는 딱봐도 너무 비효율적이기 때문에 plane을 새로 만들기 보다 plane은 하나만 만들어 두고 time 에 대해 condition을 가해주는게 합리적일 것이다. 따라서 수식(3)과 같이 기존 3 plane + vector 과정 끝에 time condition을 곱해줘서 최종 feature를 뽑도록 말이다. |
  |
하지만 수식(3)은 하나의 아쉬운 점이 있는데, 실제로 공간과 시간은 엮인 공간인데 수식(3)에서는 xyz space * time condition이므로 공간과 시간이 완전 분리된 채로 학습되는 모양으로 디자인되어 있다. 따라서 이를 커버하기 위해 plane+vector 중 vector와 time을 묶어 plane+ plane으로 변경했다고 한다. (설명은 거창한데 사실 처음부터 이렇게 했을 듯) ---- 그럼 결과적으로 x,y,z,t 4차원에서 4C2로 만든 6개의 plane 갖고 서로 조합함으로써 모든 query가 표현이 가능하게 된다. |
  |
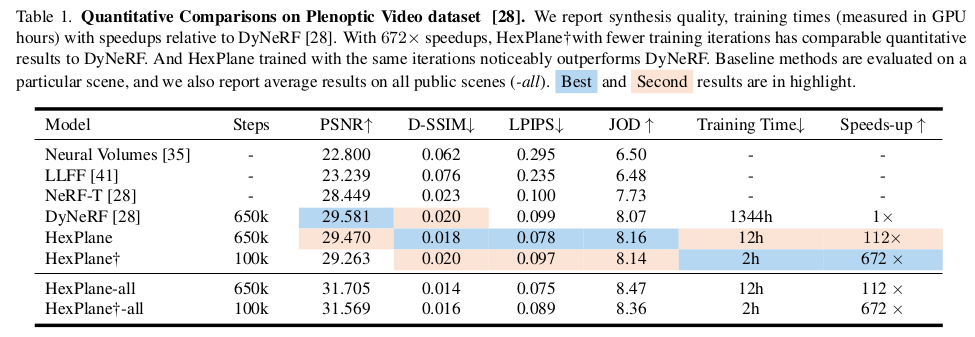
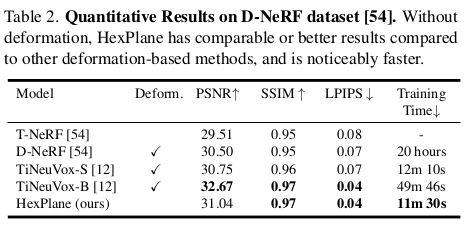
최적화 디테일은 수식(7)과 같이 NeRF와 동일하다. 다만 regularization이 추가되었다는 점만 다르다. ----- TV Loss 시,공간을 같이 다루기 때문에 이미지의 블러 현상이나 뭉개짐이 더 심하다. 따라서 이를 억제하기 위해 TV loss를 추가했다. 그냥 위치 i <-> i+1 비슷하게 유지하는 loss인데 6개의 평면 상에 적용해주었다. 즉 feature 상에 적용하는 loss다. ----- plane의 해상도가 학습이 진행됨에 따라 높아지도록 했다고 한다. 추측하길 1/8 -> 1/4 -> 1/2 -> 1/1 과 같이 bilinear upsampling이 용이한 해상도를 기준으로 2~3회 정도 올릴 것 같다. ----- 마지막으로 텅빈 voxel이 있을 것이다. 허공에 떠있는데 time마다 계속 허공에 있는 voxel. 이러한 점은 무시했다고 하는데... 어떻게 제거했는지 구체적으로 나와있지가 않다. single voxel로 만드는게 뭔지... 구현을 어떻게 했는지는 코드를 봐야할 듯. |
  |
|
 |
 |
 |
 |
 |
 |
반응형