반응형
내 맘대로 Introduction
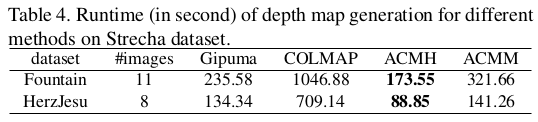
이 논문은 MVS 논문인데 이전에 간단히 기록했던 2015년 patchmatch stereo 기반 MVS 논문 [link] 의 확장판으로 2019년 비교적 최근에 등장한 논문이다. 주목할만한 점은 딥러닝이 판을 치기 시작한지 한참 지난 시간임에도 딥러닝 하나 없이 훌륭한 성능을 달성한 것이다. 기본에 충실하게 logic을 검토하면서 MVS 파이프라인을 구현한게 존경할 만하다. 코드가 방대한 양이 아니라 고작 h, cpp 2쌍으로 끝나도록 간결하게 구현했는데 성능이 좋은 것도 주목할 만 하다.
핵심 아이디어는 기존 patchmatch stereo에서 neighbor 영역을 정의할 때, red-black region으로 나누기 + 마름모꼴로 정의했는데 red-black region으로 나누기 + 마름모꼴 "범위" 정하고 그 안에서 골라서 정의하기 + view selection 선택적으로 하기 로 변경해서 adaptive한 비교가 가능하도록 했다는 점과 patch 사이즈는 고정한 채 multi scale MVS를 수행함으로써 texture less region 문제를 완화했다.
 |
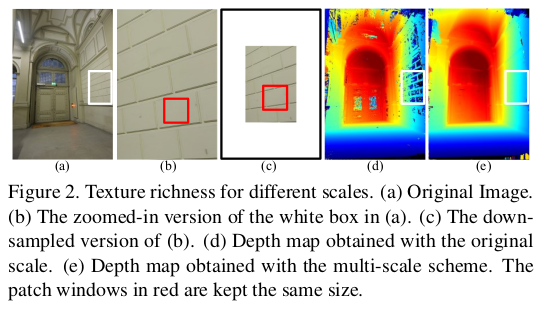 |
| 기존 Wp neighbor를 정의하는 방식을 (b)와 같이 써왔는데 이를 (c)와 같이 구역으로 한정하고 그 구역 내부에서 sampling은 현 cost 상태를 보고 가장 낮은 cost sample을 고르도록 변경함 | textureless region도 조금 멀리서 보면 경계가 보이는 일이 다분하기 때문에 patch size를 고정하고 multi scale로 같은 위치를 관찰하면 texture-less region이라고 정보가 없진 않다는 전제 |
이 논문 안에는 기본 단위가 되는 MVS 모듈, ACMH와 ACMH를 Multi-scale로 확장한 ACMM 두 개가 담겨있고 주 포인트는 ACMM에 있다.
메모하며 읽기
 |
|
  |
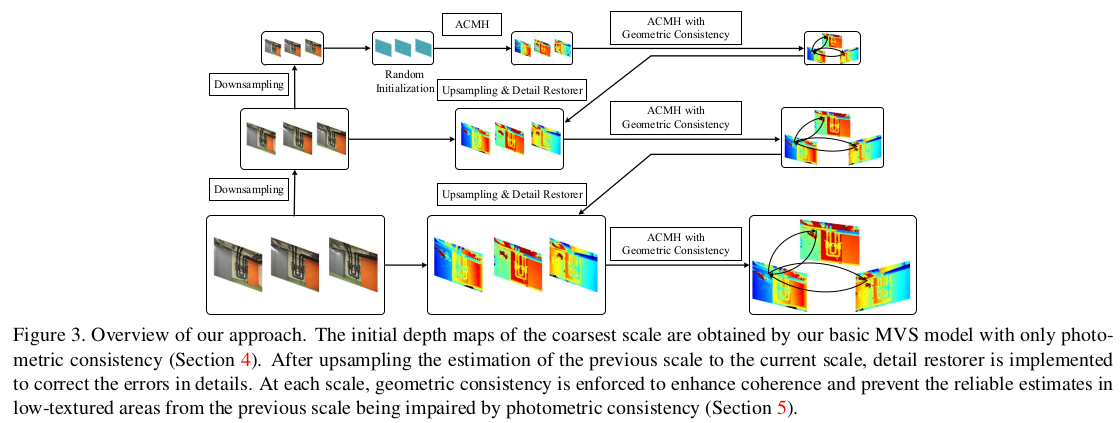
위 그림이 전체 파이프라인인데, 보다시피 ACMH가 기본 단위이고 이를 multi scale로 여러 번 upsampling하면서 적용하는 구조다. 따라서 ACMH와 ACMH의 cost function에 geometric consistency를 추가한 버전 2개를 이해하는 것이 시발점이다. multi scale로 구현한 이유는 앞서 짧게 언급한 바와 같이 texture less region도 patch size를 고정한 채 멀리서 보면 경계가 보일 확률이 높으므로 coarse에서 관찰할 수록 texture less에 유리, fine에서 관찰할수록 detail에 유리하기 때문이다. |
  |
먼저 ACMH를 설명하기 시작한다. ACMH는 기존 patchmach stereo와 크게 다르지 않다. 무작위로 depth, normal 초기화하는 것도 같고 cost aggregation하는 부분도 top K 뽑아서 하는 것도 동일하다. |
 |
 중간 red-black region 설정하는 것까지도 똑같고 neighbor를 정의하는 방법만 다르다. 위 그림에서 옅은 빨강 영역까지만 한정해두고 그 내부 위치한 총 7+11개 위치에 대해 cost를 평가한 뒤, 영역 별로 최소 cost를 갖는 점 총 8개를 선별하는 방식으로 변경했다. cost 기반으로 neighbor를 정의하기 때문에 현 hypothsis에 적합한 sample과의 비교에 집중하게 되어 효율이 늘어날 것으로 보임. |
  |
view selection도 기존에 전후 N개로 단순하게 선별하거나 무작위로 선별했다면 matching cost를 기반으로 view를 scoring해서 선별하는 방식으로 바꾸었다. 수식(1)과 같이 앞서 만든 8개의 hypothese x N-1 개 view 간의 cost를 matrix로 만든 뒤, 가장 낮은 total cost를 갖는 column(view)에 우선순위를 부여하는 방식이다. 전제 조건은 matching cost가 전반적으로 낮게 나오게 만드는 view가 좋다라는 가정이다. total cost의 일정 threhold를 부여해서 total cost가 일정 범위 안으로 들어오는 애들만 view cadidate가 될 수 있도록 했고 각 view마다 total cost로 만든 weight를 부여해서 (수식3) cost aggregation도 단순 sum이 아니라 weighted sum (수식4)로 변경했다. total cost threshold는 heuristic한 값인데다가 학습 초기에는 높고 후반에는 낮아져야 되는 특성이 있기 때문에 threshold는 초기값만 잡아주고 이후에는 자동 deacy한다 (수식2) (초기값 잘못잡아서 전부 다 out되면 어떻게 되는지 궁금해서 코드를 보니 전부 다 out 될 경우 그냥 top n개를 사용하도록 해뒀더라) ------- 수식(4)로도 충분해 보이지만 연산을 매번하는 것도 문제고 사실 이전 step에서 best view로 뽑혔던 것이 이번 step에서 worst view로 뽑힐 확률은 매우 낮기 때문에 이전 step에서 뽑힌 view들에 가중치를 주는 방식으로 약간 변형해서 수식(5)로 만들어 사용했다. |
 |
수식(6)과 같이 정의한 cost function으로 최적화를 돌리면 일단 ACMH가 끝나는데 결과값을 refinement하는 스텝이 남아있다. 여기선 추정된 depth와 normal이 둘다 부정확, 둘다 정확, 둘 중 하나만 정확 이라는 3가지 케이스가 존재하는데 여기에 randomize, pertubation이라는 2가지 경우의 수를 더하여 총 6가지 augmentation을 한 뒤, 우연히 cost가 더 낮아지는 결과가 있다면 업데이트하는 식으로 했다. depth만, normal만, depth+normal 둘 다 random or pertube하는 것이다. 마지막엔 media filtering 적용한다. |
  |
ACMH가 끝났다. 이후엔 ACMH with geometric consistency다. 똑같은데 cost function에 geometric consistency를 추가해서 한 번 더 돌려준다. gc(geometric consistency)라 함은, 현재 찾은 depth를 이용해 back projection 후 다른 시점으로 reprojection했을 때 맞아 떨어지는지 평가하는 것이다. 정확하다면 reprojection error가 작게 나와야 하니 말이다. 이런 reprojection error를 matching cost(photometric consistency)에 더해서 수식(9)와 같이 cost function을 변경해서 다시 한 번 돌려준다. 이런 방식은 photometric consistency가 잘 안통하는 textureless region에 대해 upsampled depth의 힘을 받아 성능을 끌어올릴 수 있는 방식이기 때문에 textureless region 성능이 좋아질 뿐만 아니라 사실 모든 위치에서 적용 가능한 수식이라 전반적으로 성능이 높아진다고 한다. |
 |
|
 |
detail restorer는 multi scale의 장점을 이용해 detail을 더 살리는 방법이다. upsampling을 통해 coarse 정보를 가져오면 일단 error가 큰 상태일 뿐만 아니라 과도하게 넓은 fine 영역에 coarse 정보가 덮힌다. 그래서 error를 줄이고 영역을 fine scale에 맞도록 재단해줄 필요가 있다. 이 방식은 upsampled vs fine scale(ACMH w gc까지 돈 것)을 비교해서 차이가 큰 영역을 masking하고 그 masked region에 한 해서 수식(10)을 최소화 하도록 한 번 더 돌려주는 것을 의미한다. |
  |
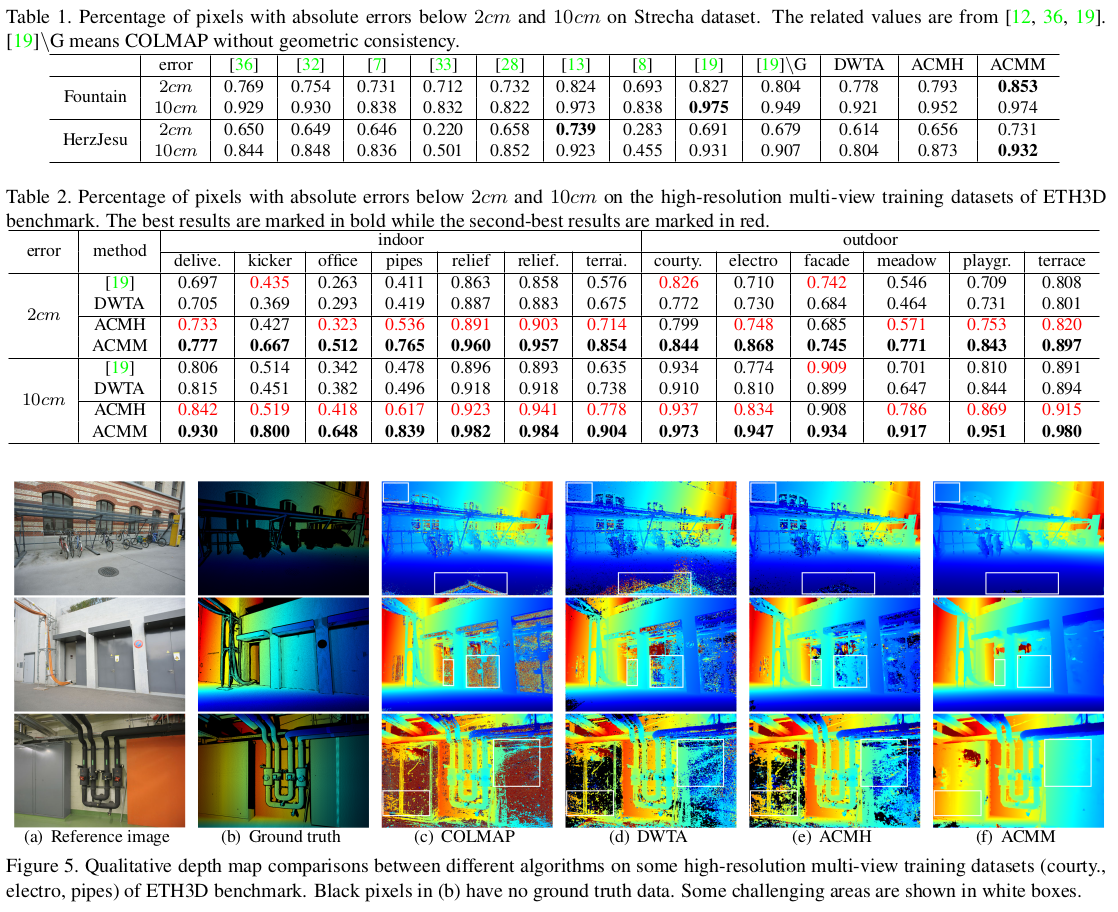
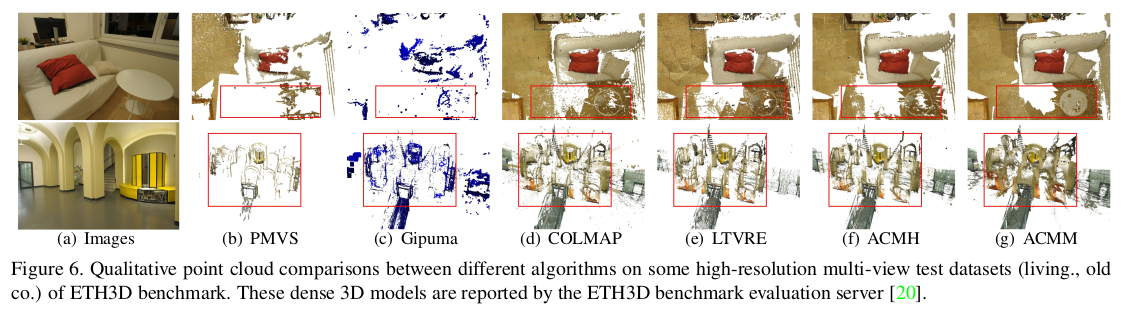
all depthmaps to one point cloud 작업은 이전 work들과 동일하다 reference 잡고 back projected 3d point 만든 뒤, 하나하나 다른 시점으로 내려찍어보면서 geometric consistency를 체크해서 지우고 남기는 작업을 반복하면 된다. |
 |
 |
 |
 |
반응형
'Paper > 3D vision' 카테고리의 다른 글
| Hierarchical Prior Mining for Non-local Multi-View Stereo (0) | 2023.11.09 |
|---|---|
| ACMP - Planar Prior Assisted PatchMatch Multi-View Stereo (0) | 2023.11.08 |
| Massively Parallel Multiview Stereopsis by Surface Normal Diffusion (0) | 2023.11.07 |
| PatchMatch Stereo - Stereo Matching with Slanted Support Windows (0) | 2023.11.07 |
| LightGlue: Local Feature Matching at Light Speed (0) | 2023.11.06 |