반응형
내 맘대로 Introduction
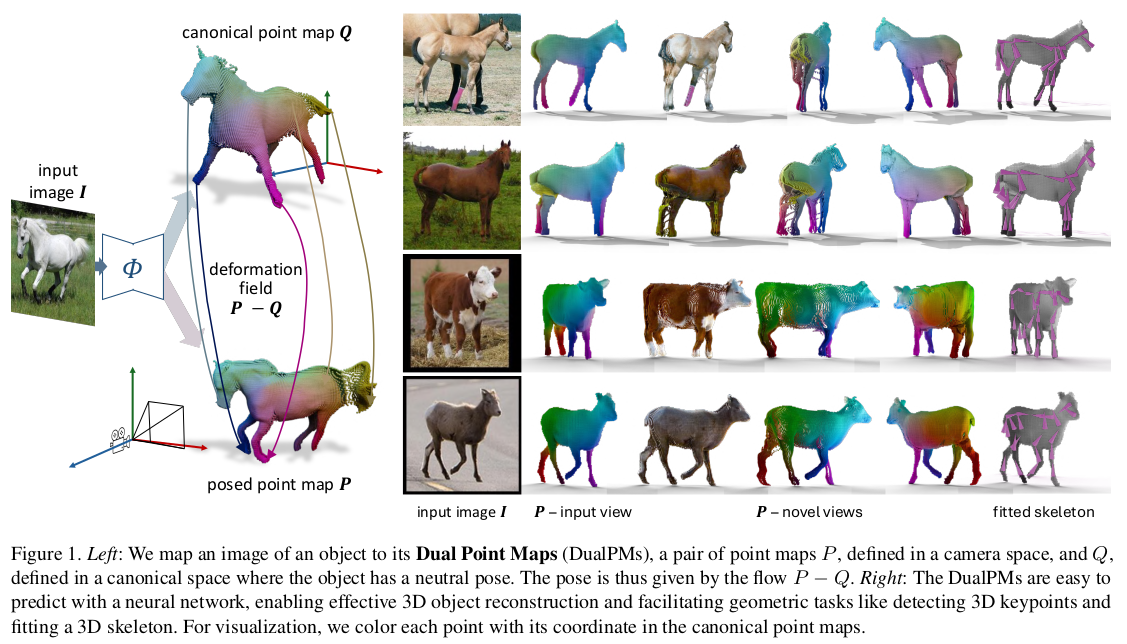
point map representation이 인기를 얻으면서 누군가는 canonical point map을 다룰 것이라고 바로 생각했었는데, 역시나 있다. 정말 naive하게 camera space point를 예측함과 동시에 canonical space point를 픽셀 별로 예측하는 걸 추가한 것. 새로운 formulation 없이 output에 추가되었다는 것은 좀 아쉬운 점. GT가 존재해야만 풀 수 있는 문제이므로, 일반화할 수 없는게 아쉽다. 뭔가 self-supervised 요소를 넣어서 풀었다면 확장이 가능하니까 더 좋았을 것 같은데... 누군가 곧 하겠지
deformed-canonical 구도에서 주 대상은 역사적으로 사람이었는데, 사람은 변화 자유도가 너무 높을 뿐더러 학습시킬 만큼 충분한 4D 데이터셋이 없다. 따라서 사족 동물 synthetic 데이터로 간소화해서 컨셉만 보여준 논문이라고 보면 된다.
메모
 |
|
  |
DINOv2 feature로 시작해서, 픽셀 별로 canonical point 먼저 예측하고, 이게 다시 입력으로 들어가서 deformed point를 예측하게되는 순서. 이 때 visible point만 하는게 아니라 occluded point도 다루고 싶어했기 대문에 point를 2N개 예측하도록 했다. (2N인 이유는 들어갔다 나왔다. surface에 2번 부딪힌다는 가정이기 때문) |
 |
 내용은 진짜 이게 끝이다. multiview image에서 correspondence끼리는 canonical point가 같아야 된다는 건 당연한 사실. 뒤에 이걸 loss로 쓰진 않는다. |
 |
 canonical Q 먼저 찾고 그걸 입력으로 써서 deformed P 찾고. GT가 있으니 그냥 l2 loss다. |
 |
 가려진 점도 추정해야 canonical space가 더 밀도있게 찾아진다. visible region만 추정하면 deformed space야 잘 찾아지겠지만 반쪽짜리 canonical point가 얻어질 것. adaptive하게 추정하는 것은 아니고 2N개 를 추가 추정하는 것으로 열어두고 (거리순으로 정렬된 형태로) opacity를 0-1로 같이 추정해서 알아서 도태되도록 설정함. 정말 naive |
  |
2N이니까 xyz xyz in out 총 6채널이고 opacity 1개 총 7개값을 예측하도록 설정했다.  데이터는 위에 보다시피 말이다. |
 |
|
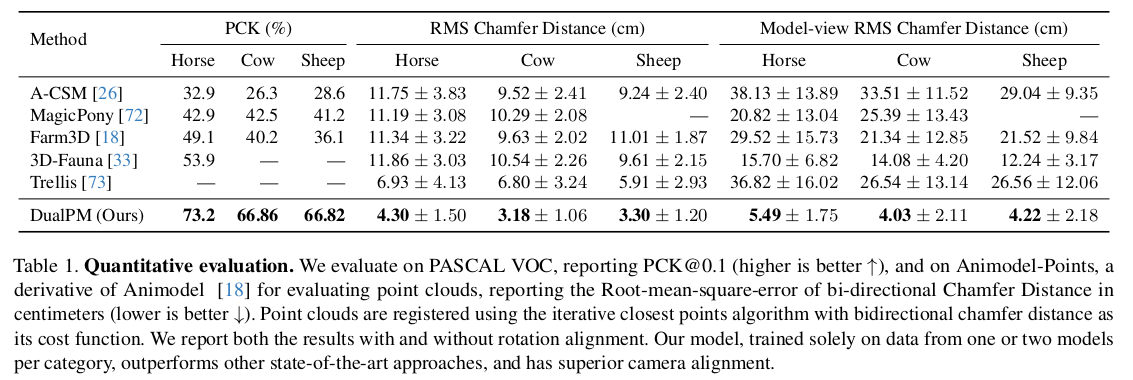 |
 사실 좋은 표현법인지는 모르겠다. |
 |
반응형
'Paper > Others' 카테고리의 다른 글
| AnyUp : Universal Feature Upsampling (0) | 2025.11.12 |
|---|---|
| Animal Avatars: Reconstructing Animatable 3D Animals from Casual Videos (0) | 2025.11.10 |
| Geometry Distributions (0) | 2025.10.27 |
| Cameras as Relative Positional Encoding (0) | 2025.07.18 |
| Rectified Point Flow: Generic Point Cloud Pose Estimation (0) | 2025.07.14 |