반응형
내 맘대로 Introduction
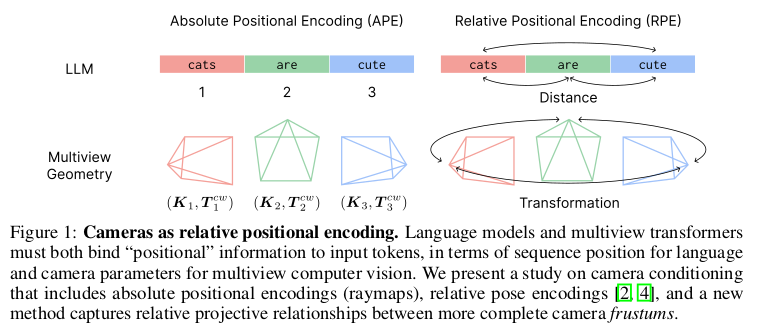
transformer가 텍스트에서 이미지로 넘어오고, 이미지에서 3D로 넘어가고 있는 시점에서 positional embedding에 대한 관심도 자연스레 늘고 있다. absolute-relative-rotary 등등 절대적 정보와 상대적 정보를 동시에 담는 방식이 효과가 좋다는 것이 밝혀져 있는데 이 논문은 3D 공간에서 어떻게 담을 것인지 절대+상대 정보를 고민한 논문이다.
대표적으로 raymap, 즉 이미지의 각 픽셀을 intrinsic,extrinsic으로 back-projection했을 때 생성할 수 있는 ray vector를 encoding값으로 쓰는 것이 있는데 너무 naive하기도 하고 scale, translation, rotation에 취약하기 때문에 그렇게 좋은 방식은 아니다. 어쩔 수 없고 구현하기 간단하니까 쓴 것이지.
이 논문에서는 기존 CAPE나 GTA가 카메라 extrinsic에만 집중했던 점을 짚어서 intrinsic까지 반영한 것이 차이다. 결론부터 말하면 token level에서 attention을 걸 때 Q와 K 앞 뒤로 extrinsic matrix를 곱해주던 식이었는데 여기서 K까지 곱해주는 것이 끝이다. 어떻게 보면 매우 간단.
메모
 |
원래 많이 쓰던 방식은 raymap origin xyz + direction xyz 합쳐서 6개 값을 각 픽셀마다 칠해서 positional embedding으로 쓰는 것 plucker coordinate으로 바꿔쓰는 선택만 있었을 뿐 큰 차이는 없다. 딱봐도 이경우 origin이라는 절대값이 박혀있기 때문에 좌표계가 바뀌거나 스케일이 바뀌면 아예 의미가 없어진다. |
 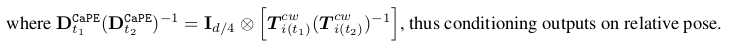 |
그 다음 제안된 것은 입력에다 concat해주는 것이 아니라 token level에서 attention layer 마다 extrinsic matrix를 곱해주는 것이다. 4x4 matrix가 한 블럭을 이루고, 이게 대각선으로 차있는 matrix D를 만든 다음 Q' = D.T*Q , K' = D_inv*K 같이 쓰는 방식 RoPE의 attention 버전이라고 볼 수 있다. 문제는 intrinsic은 간과한다는 것. + QK.T하는 과정에서 중간에 extrinsic 이 곱해지면서 relative transform matrix로 바뀐다 즉 relative camera pose만 반영되는 모양으로 들어감 ------------ relative form이라고는 하지만 T[:3, -1] 값은 여전히 그대로 들어가므로 좌표계가 바뀌는 것이나 scale이 바뀌는 것에 대한 대응 능력이 여전히 없는 것이 아닌가 싶다. |
 |
이를 좀 더 개선해서 V까지도 건드리는 것이 GTA Q' = D* (D.T * Q) K' = D_inv * K V' = D_inv * V QK.T 과정에서 relative form으로 바뀌어 버리는 것을 반영해서 V에는 원래 자기 matrix를 곱해주는 식 ------ 이것 역시 intrinsic은 간과함. |
 |
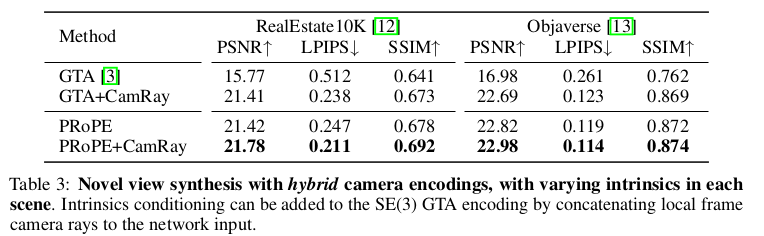
그래서 등장한 것이 PRoPE 쉽게 말하면 extirinsic으로만 matrix D를 구성하던 걸 intrinsic까지 고려해서 만든다는 것. T 대신 P를 써서 D하나를 만들고 각 ray x,y를 RoPE로 인코딩한 것을 추가한 D를 하나더 만들어서 대각 블록으로 쌓아서 최종 D를 만든다.  |
 |
P로 바뀌면 가운데가 상대 pose인 것은 맞지만 앞 뒤로 intrinsic, intrinsic_inv가 붙는다. ---------- CAPE GTA를 따라했으니 global frame invariance하다는건 relative만 다루니까 당연한 것. K가 1이면 CAPE GTA랑 동일한 것 RoPE랑도 같아질 수 있음 -------- 내 개인적인 생각은 intrinsic을 반영하려고 K를 곱해주는게 당연한 것 같아보이지만, numerical하게는 불안정성이 크게 증가하기 때문에 조건부로 좋은 방법 같다. focal length가 400~7000까지도 변하는데 카메라 기종에 따라 이걸 별도의 normalization조차 없이 썼는데 잘 됐다는게 잘 납득이 가진 않는다. |
 |
 |
 |
 |
 |
 |
 |
 |
반응형
'Paper > Others' 카테고리의 다른 글
| DualPM: Dual Posed-Canonical Point Maps for 3D Shape and Pose Reconstruction (0) | 2025.11.10 |
|---|---|
| Geometry Distributions (0) | 2025.10.27 |
| Rectified Point Flow: Generic Point Cloud Pose Estimation (0) | 2025.07.14 |
| Parallel Sequence Modeling via Generalized Spatial Propagation Network (a.k.a GSPN) (0) | 2025.07.08 |
| 4Deform: Neural Surface Deformation for Robust Shape Interpolation (0) | 2025.06.13 |