반응형
내 맘대로 Introduction
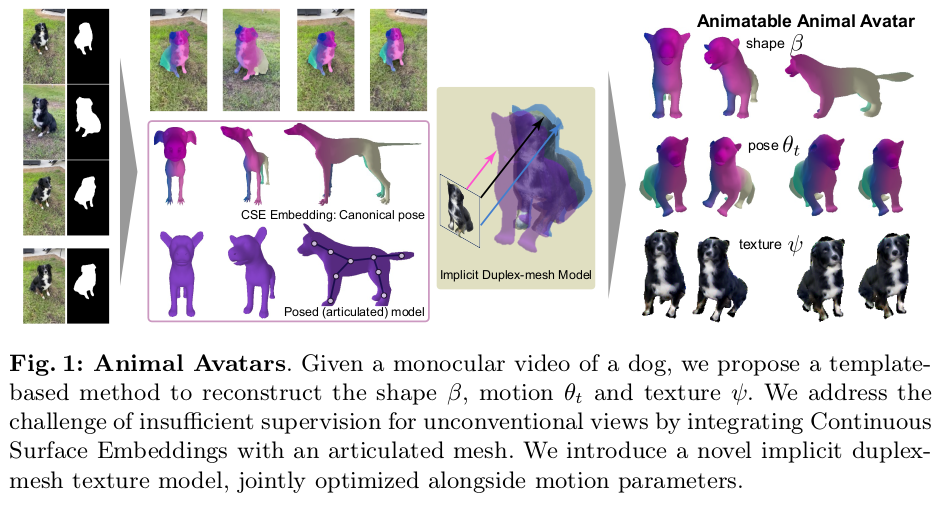
동물 논문은 예전에 SMAL 이후로 본 적이 사실 없는데, 그 이후로 그렇게 발전한 것 같진 않다. 데이터가 없을 뿐더러 관심도 낮아서 연구가 그리 많이 안된 느낌. 이해도 가는게 움직이는 개를 어떻게 찍나...그리고 개를 그렇게 많이 모으는 것도 힘들고 털이 많아서 reconstruction도 애초에 안되니 데이터를 모을 수가 없다. (어찌 보면 블루 오션인 것 같기도)
이 논문은 주어진 개 video에서 해당 개랑 가장 닮은 SMAL 파라미터를 뽑아주고, NeRF 컨셉을 이용해서 texture를 발라주는 논문이다. SMAL에 색상을 입히는 방식이기 때문에 정확도가 엄청 높진 않다. 하지만 여태까지 다뤘던 논문 대비는 완성도가 많이 올라간 버전.
핵심은 CSE가 동물 버전도 있다는 것에서 착안해서 CSE 예측값을 fitting의 pseudo GT로 활용하는 것. + SMAL surface 주변에서 국소 NeRF 렌더링으로 texture를 찾아내는 것이다.
메모
 |
|
   |
기본적으로 딥러닝이 아니라 최적화 프레임워크다. 이미지 + 카메라 포즈 + 마스크 + CSE 예측 결과가 주어졌다고 했을 때 differential rendering 을 통해 SMAL 파라미터를 역추정하는 것이 1단계 1단계가 완료되었을 때 SMAL surface 살짝 안쪽 살짝 바깥 쪽에 surface를 하나 더 만들어 내고 inner<->outer 사이 공간에서의 짧은 ray 에 대해 raidan field technique을 써서 texture를 찾는다. texture는 고로 NeRF 네트워크가 있어야 됨. texture map이나 vertex color로 찾아지는건 아니다. |
 |
shape 파라미터는 공유, 매 프레임마다 pose 파라미터는 각각이다. |
 CSE랑 SMAL에서 사용하는 topology 차이가 있긴 해서 이 둘을 매칭해주고 나서 사용했음. |
|
 |
좋은 논문의 활용은 시간이 지나도 빛이 바래지 않는다. CSE 재등장.. 아무도 관심 갖지 않았던 CSE표현법의 장점. topology matching만 된다면 꼭 사람이 아닌 형상에 대해서도 surface embedding을 만들 수 있다는 장점. 고로 CSE 동물 버전이 존재하는데, 이걸 가져와서 입력 정보로 같이 썼다. (테스트 해보니, 모든 프레임에 대해서 성공할 정도로 안정성이 높진 않다. 개를 위에서 찍거나, 개의 뒤를 찍으면 잘 안된다. 예측 실패한 프레임은 버리는 식으로 처리했음) |
 |
|
  |
이제 대망의 텍스처, 사실 geometry가 완벽히 이미지랑 픽셀 레벨로 맞는다면 그냥 texture map 최적화를 하면 끝이지만, 최대한 닮은 SMAL을 얻어낼 뿐이라서 입력과 이격이 꽤 크다. (실제로 큼) 그래서 그냥 최적화 하면 눈이 이상한데 붙어있을 수도 있음 아마 이 문제를 저자들도 겪었는지, 단순 최적화를 포기하고 NeRF로 처리해서 약간의 noise handling을 기대한 것 같다. 개가 요리 조리 온몸비틀기를 하는 와중에 일관된 ray를 생성하는 것은 거의 불가능하니 surface 근처에서 ray는 일정할 거라고 가정한 후 SMAL surface 주변 공간에서만 radience field를 계산했다. (이론 상 허공에 있는 애는 애초에 개 색깔에 영향을 안주니까 당연하기도 함.) |
 |
렌더링한다고 하면 view direction을 따라 내려오다가 outer-inner surface에 부딪히는 위치를 찾아내서 그 사이 값만 갖고 렌더링. |
  |
모든 최적화가 그렇듯 초기 글로벌 포즈가 없으면 깨진다. 여기서도 SMAL의 글로벌 포즈만 먼저 매 프레임 피팅을 해둔다. 이건 CSE에서 같이 뽑을 수 있는 keypoint도 있고 CSE map 자체도 있기에 파라미터만 잘 잠궈둔다면 가능. |
  |
global pose를 찾아뒀으니 이제 나머지 관절만 relative form으로 최적화 해줬다. 여기서 카메라 포즈는 이미 알고 있다는 가정 사실 이 카메라 포즈를 알고 있다는 가정이 엄청 큰 건데 이게 더 문제될 것 같기도. 개가 돌아다니는 영상을 찍었는데 틈틈히 보이는 것만 갖고 정확한 카메라 포즈를 SfM 푼다는 것이 가능할지... VGGSfM 같은걸 쓰라고 하는데 잘 될까? |
 |
1) CSE dense map이 있으니 렌더링된 결과랑 직접 비교 2) CSE 네트워크가 keypoint도 몇개 뱉어주는데 이걸 비교 3) texture까지 포함해서 렌더링했을 때 입력 이미지와 비교 4) 마스크가 비슷하도록 비교 5) SMAL 파라미터가 너무 튀지 않도록 억제. |
 성능이 안좋아보여도 개가 들어가니 귀여워 보이는 마법. |
   |
반응형
'Paper > Others' 카테고리의 다른 글
| Stable-SCore: A Stable Registration-based Framework for 3D Shape Correspondence (0) | 2026.01.20 |
|---|---|
| AnyUp : Universal Feature Upsampling (0) | 2025.11.12 |
| DualPM: Dual Posed-Canonical Point Maps for 3D Shape and Pose Reconstruction (0) | 2025.11.10 |
| Geometry Distributions (0) | 2025.10.27 |
| Cameras as Relative Positional Encoding (0) | 2025.07.18 |