반응형
내 맘대로 Introduction

이 논문은 여러개의 object part pointcloud가 주어졌을 때, 하나를 기준으로 나머지 pcd들이 조립되듯이 정렬되는 걸 목표로 한다. 구현을 이렇게 했지만 풀고자 했던 문제를 point cloud generative model이 형상과 구조, 의미를 파악할 수 있음을 보이는데 있다. 어떻게 보면 입력을 pointcloud로 바꾼 diffusion model로 볼 수 있지만 내 생각엔 좋은 insight를 주는 컨셉 논문인 것 같다.
ICP나 여느 registration 논문은 overlapped region에 의존해서 정렬을 하기 때문에 완전 떨어진 pointcloud끼리는 의미론적으로 정렬할 수 밖에 없다. 이 부분을 파고 들어서 minimal overlapped registration을 학습으로 푸는 걸 보여줌과 동시에 pointcloud도 self-supervised로 prior를 형성하도록 만들 수 있다는 걸 보여준다.
하나 아쉬운 점은 pointcloud를 그대로 입력으로 쓰는 것은 메모리를 폭발시키는 일이기 때문에 거의 금지된 듯한 느낌인데 여기선 그건 무시한 체 입력 pointcloud 수를 1000으로 제한하고 그냥 진행했다. scale up될 가능성까지는 보여주지 못했음.
메모
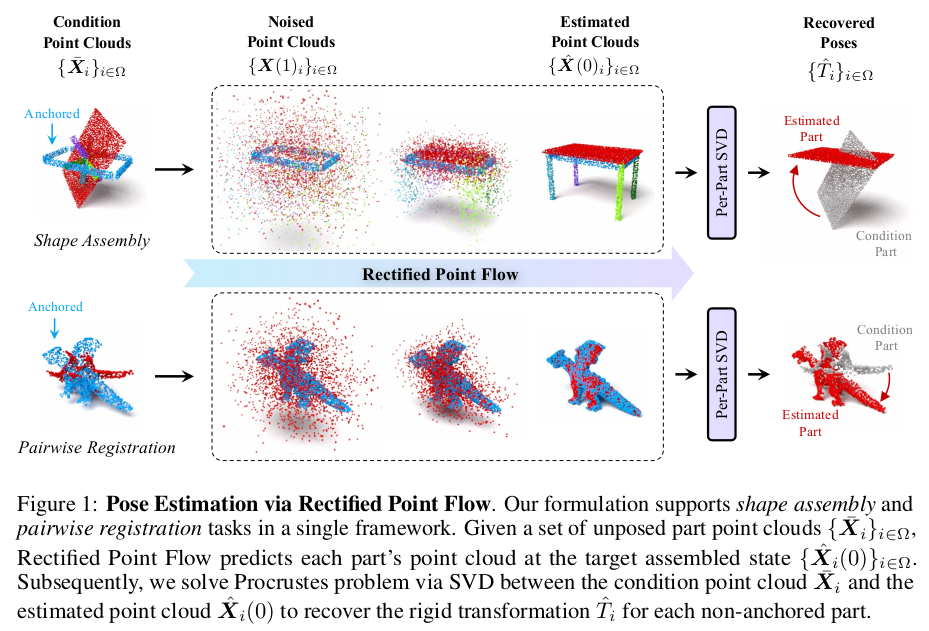 |
|
  |
총 3가지 구성이다. 1) self-supervised로 point encoder 학습해두기 2) DiT 학습하기 -> pointcloud 각 point마다 시간 t에 따른 velocity field 추정 3) procrustes alignment로 point cloud 전체 SE3 계산 |
 |
1) self-supervised는 어떻게 학습시켰을까 이미지같은경우는 mask를 활용한 방식이 정석이다. 하지만 pointcloud에서는 그런게 없음. 여기선 "정렬"이 최종 목표이다보니, 각 pointcloud 별 접합부를 예측하는 것이 정렬에 도움이 될 것이랑 가정을 세운다. 따라서 여러 pointcloud를 encoder에 넣었을 때 각 pointcloud 마다 인근에 다른 그룹 point가 있을 경우 1 아니면 0으로 supervision을 주었다. 완벽 정렬 상태라면 접합부에만 1이 될테고 그림처럼, 그렇지 않더라도 물체간 거리 기반으로 맞닿는 지역을 추정하는 과정에서 geometric 관계성을 학습할 것이라고 본 것 같다. |
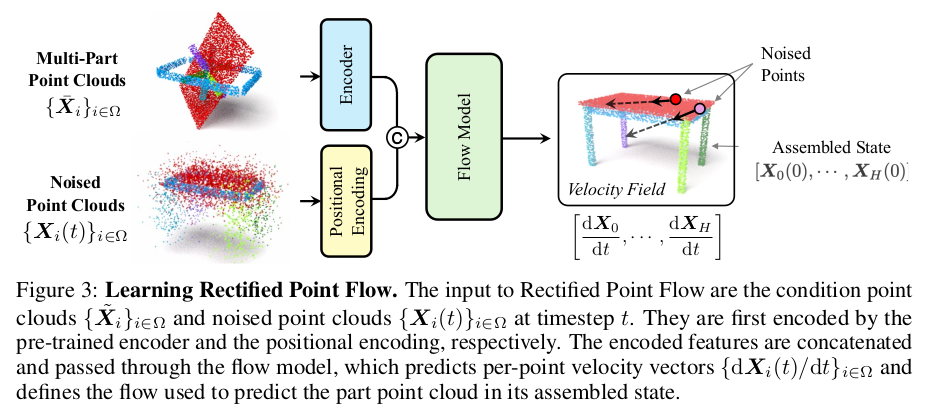 |
|
  |
학습 과정은 two encoder 구조다. 1) randomly posed pointcloud 하나 posed pointcloud + noise 하나 이 둘은 같은 pointcloud set이기 때문에 point 개수가 같다. 따라서 두 셋에서 온 embedding을 point-wise concat해서 DiT에 통과시킨다. 그러면 네트워크가 noised posed pointcloud를 무작위로 돌아가있는 pointcloud를 condition 삼아 제자리로 돌려보내는 volocity field를 예측한다. --- flow matching 컨셉인데 loss function은 수식 3과 같이 제안된 바 있다. |
 |
정렬 전, 후가 각각 t=1, t=0 상태가 되고 그 사이 dX/dt는 선형적이라고 가정한다. 다른 말로 point 별로 출발-도착을 무조건 1초에 완주하도록 속도가 조절되었다고 가정. (서로 가깝게 출발하든 멀게 출발하든 똑같이 도착함) -> 이게 V(t, X(t)의 GT 역할을 함. |
 |
그냥 그림에 대한 세부 설명임. |
 |
point transformer v3 + DiT A100 8 장 썼다. 역시 메모리가 1000 sampling만 써도 크구나. |
 |
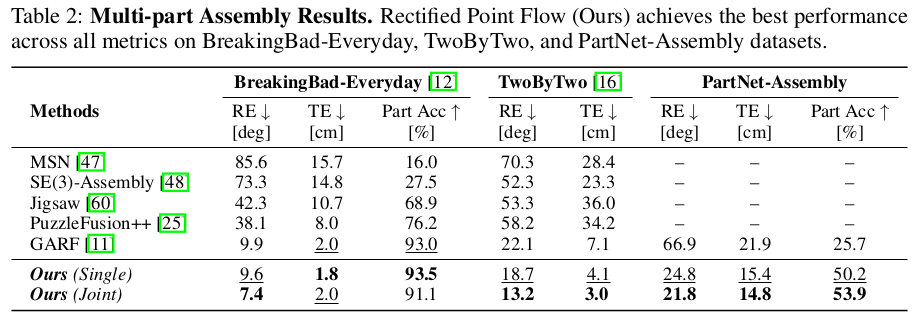 |
 |
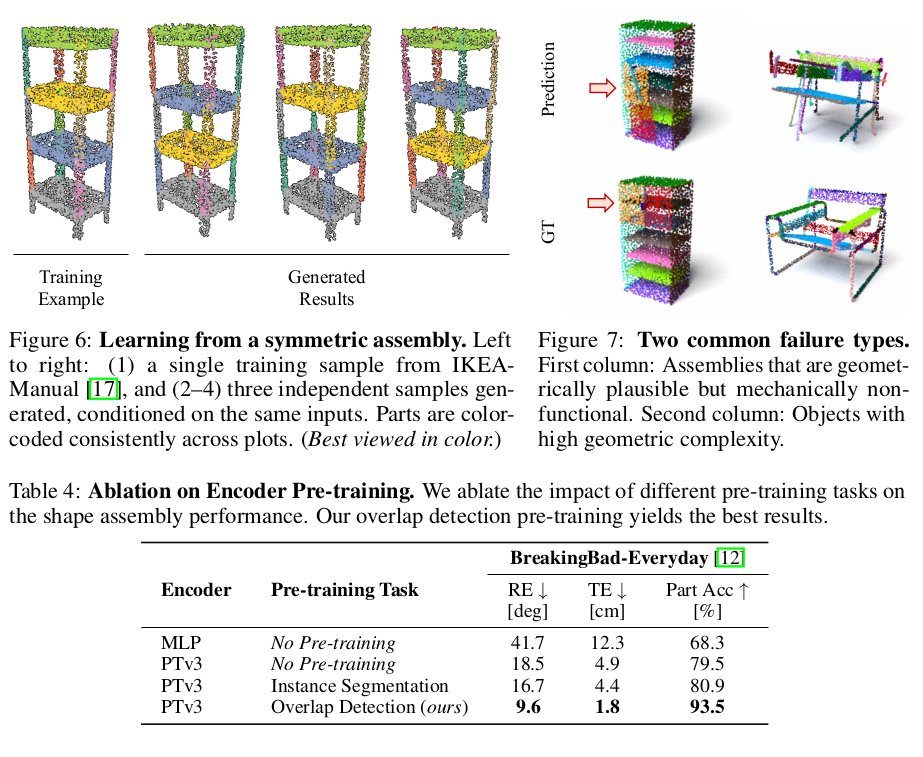 |
반응형
'Paper > Others' 카테고리의 다른 글
| Geometry Distributions (0) | 2025.10.27 |
|---|---|
| Cameras as Relative Positional Encoding (0) | 2025.07.18 |
| Parallel Sequence Modeling via Generalized Spatial Propagation Network (a.k.a GSPN) (0) | 2025.07.08 |
| 4Deform: Neural Surface Deformation for Robust Shape Interpolation (0) | 2025.06.13 |
| Implicit Neural Surface Deformation with Explicit Velocity Fields (0) | 2025.06.12 |