반응형
내 맘대로 Introduction
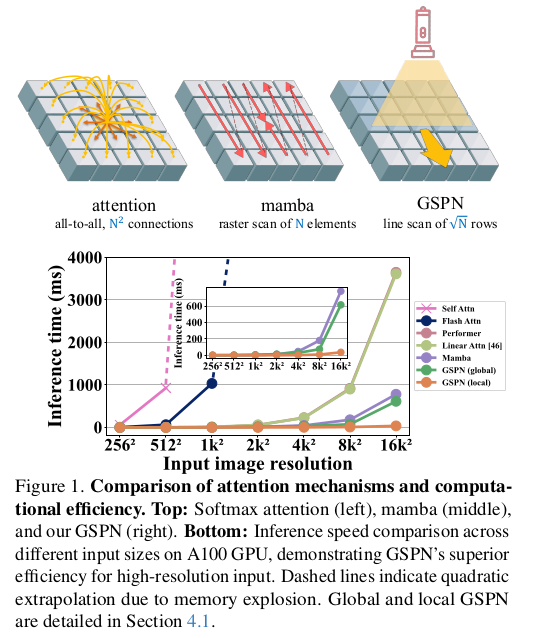
드디어 나왔나?! 쓰기도 쉽고 이해하기도 간단한 transformer 대체재? trasnformer의 핵심 attention meschanism은 효과적이지만 그 연산량이 O(N^2) 이기 때문에 높은 해상도로 학습하는건 기업의 전유물이 된지 오래다. 내로라 할 backbone들 중 개인이 공개한 경우는 거의 없다. 전기랑 GPU 값을 견딜 수 없기 때문이다. 기업에서도 하긴 한다만 부담이 있는 것도 팩트.
그래서 mamba를 비롯한 attention layer를 대체하는 연구에 관심이 많이 쏠리는데, 이번에 NVIDIA에서 깔끔한 논문을 하나 냈다. 개인적으로 mamba는 몇 번 읽어봤지만 아직도 완벽하게 이해가 안간 반면 이 논문은 그냥 바로 이해가 가능해서 좋았다. 실험적 증명도 단순 classification, detection 같은, 이제는 그렇게 관심이 없는, task가 아니라 SD를 학습해버리는 식으로 화끈하게 한 것도 좋은 것 같다.
핵심은 row-wise, column-wise line scan처럼 pixel이 아닌 line 단위로 연산함으로 써 sqrt 배로 연산량을 줄인 것이다. 이전 line이 다음 line을 결정하는 식으로 모델링해서 spatial info나 context info도 그대로 가져가도록 구현했다.
메모
  |
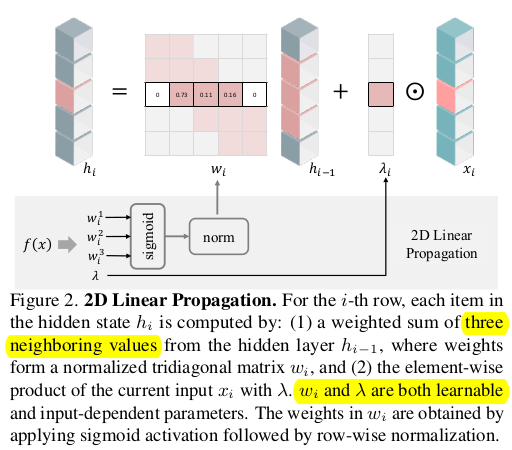 그림을 너무 잘 그려놔서 이해하기 쉽다. 이미지의 한 row를 뗴어왔다고 했을 때 row의 특정 위치 i의 feature를 결정하는 과정은 이전 feature row * weighted sum용 w matrix (전후 1칸씩만) + 입력 * learnable scale factor 다. 라인 1줄 관점에서 전후 위치를 살펴보는 개념이 되겠다. |
 |
이걸 확장해서 같은 line 내가 아닌 line "간" 관계를 모델링하는 것은 matrix 곱 한번으로 끝난다.  요로코롬 생긴 matrix가 될텐데 가 w_i가 위에서 만든 각 line에 해당하는 weight matrix가 되겠다. 이전 line이 다음 line을 결정하는 sequential 구조이기 때문에 lower triangular matrix가 되는게 당연한 모양. 대각 성분에는 scale factor로 차있다. |
 |
그냥 이렇게 하면 attention이 대체되는가? 라고 의문을 품을 수 있는데 구조적으로 보면 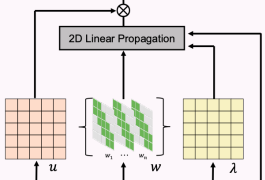 제일 마지막에 곱해지는 u가 query Q와 같고 lambda는 K와 같고, w는 value와 같다는 것을 볼 수 있다. 다른 말로 표현하면 value를 full matrix로 사용하는 것이 아닌 sparse matrix로 사용하는 attention layer랑 동치다. |
  |
이게 학습이 잘되냐? 안정적이냐? 라고 궁금할 수 있는데 수학적으로 설명을 시도한다. weight matrix는 정말 이전 state h_i-1 의 weighted sum용이기 때문에 항상 positive + sum이 1인 조건을 유지한다. (구현은 sigmoid + normalization이 껴있음) 그래서 다음 state h_i는 "무조건" 이전 state 에 의해서만 결정된다. (입력이 들어가긴 하지만 무조건 이전 state 정보가 weight sum 1만큼 유지되도록 강제됨) 따라서 propagation되는 과정에서 이전 정보를 잊지 않음. long range context 유지에 유리하다. + 수치적으로 positive에 합이 1인 matrix는 안정적이다. |
 |
order를 줄이는 것도 의미가 있다만 여전히 N이 겁나게 크면 연산량은 문제가 된다. line 단위로 정보를 계산한다고 하면 이미지의 한 변의 길이가 커질수록 연산량이 크게 늘 것이다. (1024 때보다 2048때 훨씬 클 것) 저자들은 이미지 해상도에 비례해서 늘어나는 연산량을 그리 원하지 않았는지 아주 단순한 트릭으로 이를 푼다. 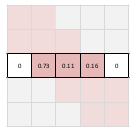 그림이 설명을 앞서갔었는데, 다시 이전 그림은 보면 weight matrix를 이전 1칸 다음 1칸 pixel만 참조하도록 하는 것이다. 이러면 한 line(row나 column) 길이가 아무리 늘어난다 한들 저장해되는 weight parameter는 pixel당 N개가 아니라 3개다. nxn에서 nx3으로 줄어든 것. 저장은 sparse matrix로 하든가 하면 된다. ------------- 추가로 방향 4개를 지정함. 이미지다보니까 한 pixel 기준으로 봤을 때 line을 4방향으로 뻗쳐나갈 수 있게 함. 4방향 propagation을 동시에 처리하고 MLP로 합침. 마지막에. |
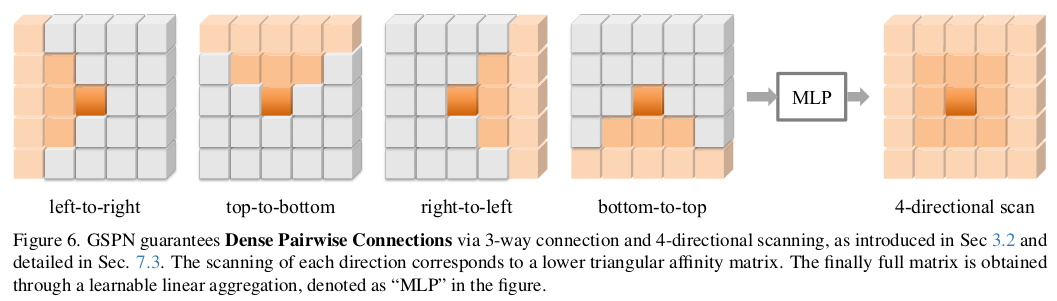 |
|
  |
sparse matrix인데 기존 full matrix 하듯이 하면 낭비니까. CUDA kernel 하나를 짜서 전후 pixel 참조하도록 구현하고 병렬처리할 수 있도록 했다. |
 |
line scan을 처음부터 끝까지 할 수도 있지만 연산량 조절과 효율을 위해 범위를 나눠줄 수도 있다. 만약 classification처럼 이미지 전체를 봐야하는 경우 full scan이 맞지만 dense prediction의 경우 굳이 full scan이 도움되진 않는다. 국소적으로 scan하는 것이 더 나을 수도 있음 따라서 이미지를 patch단위로 쪼개는 것처럼 이미지를 line patch로 겹치는 영역 없이 자른 뒤 line patch 내에서만 GSPN을 실시한다. patch(여기선 group)마다 병렬로 처리할 수 있기 때문에 group을 나눌 수록 속도가 빨라진다. |
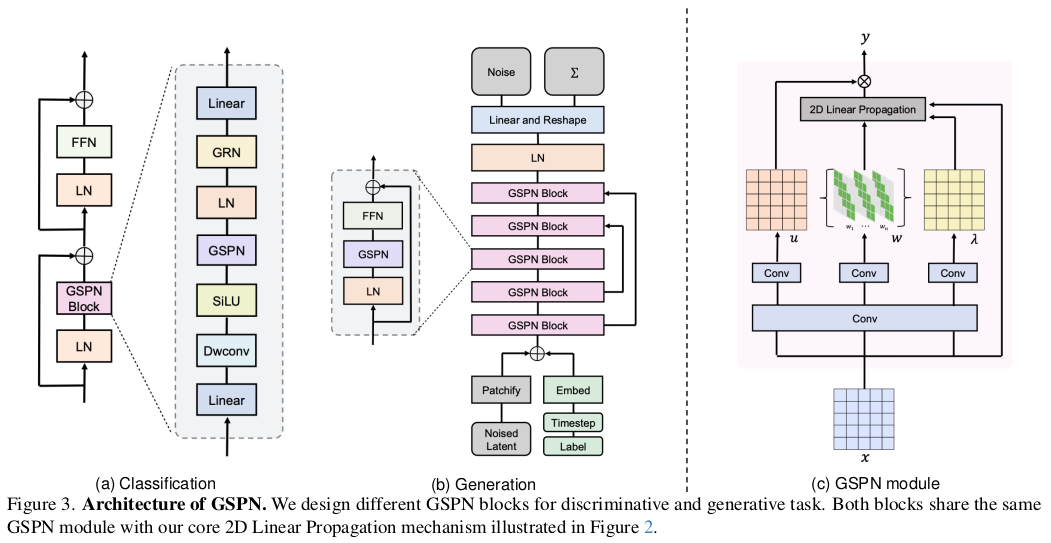 |
|
  |
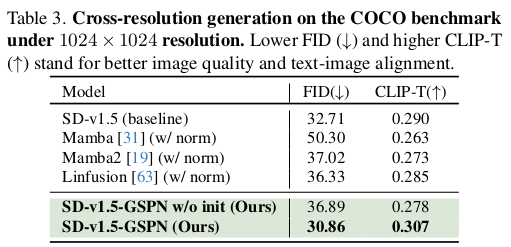
  task 별로 구체적인 디자인을 공유한다. classification은 full scan을 기준으로 그림 (a)와 같이 쌓았고, image generation 때는 (b)와 같다. 기존 positional embedding, 각종 normalization이 섞인 구조에 attention layer만 바꿔치기 했더니 잘 안돼서 이렇게 했다고 한다. ---- 하지만 SD에서는 attention layer만 교체하고 QKV를 가져와서 u, w, lambda를 초기화해줬더니 잘됐다고 함. -> 대체 가능성이 높다! |
  1) 초반에 local 후반에 global하면 fine + high level understanding 둘 다 챙길 수 있다. 2) average pooling보다 MLP로 4방향 feature를 aggregation하는게 더 좋다. |
  3) 방향성이 존재하는 attention mechanism이므로 굳이 positional embedding을 넣지 않아도 효과적이었다고. 4) normalization을 덜 해도 된다. weight matrix, w가 항상 normalization되어있는 상태이므로 안정성이 높은게 이유 5) 이전 state에서 다음 state로 넘어갈 때 GLU 같은 로직을 쓸 필요가 없다. 해봤더니 그리 향상이 없었다. -> 내가 볼땐 weight matrix가 항상 sum이 1이 되도록 유지된게 큰 도움이 된게 맞는듯. |
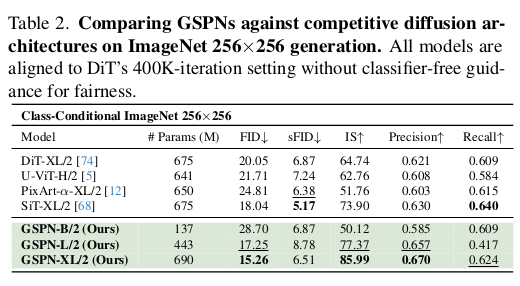
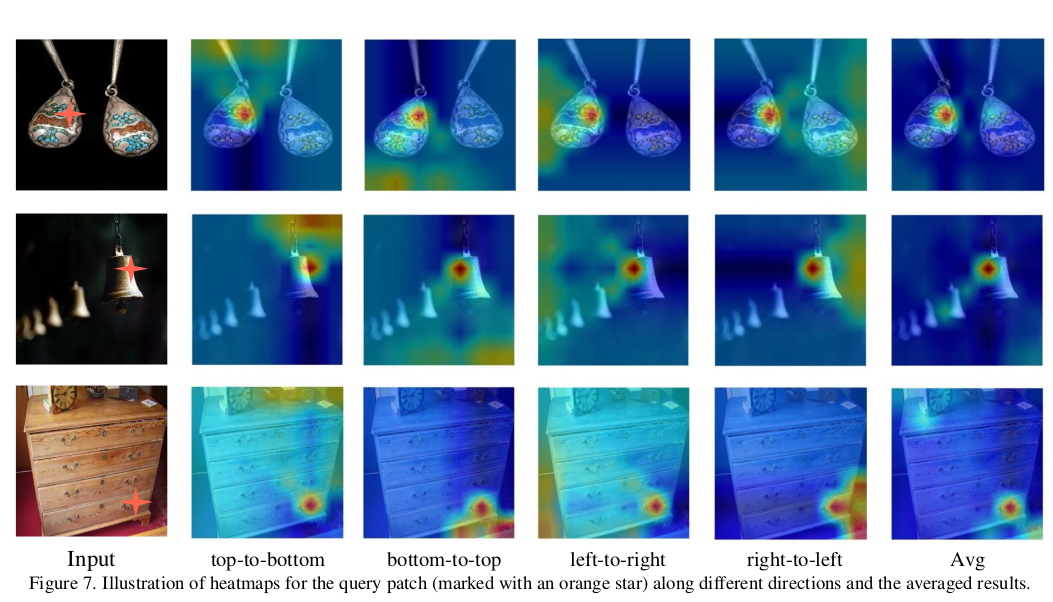
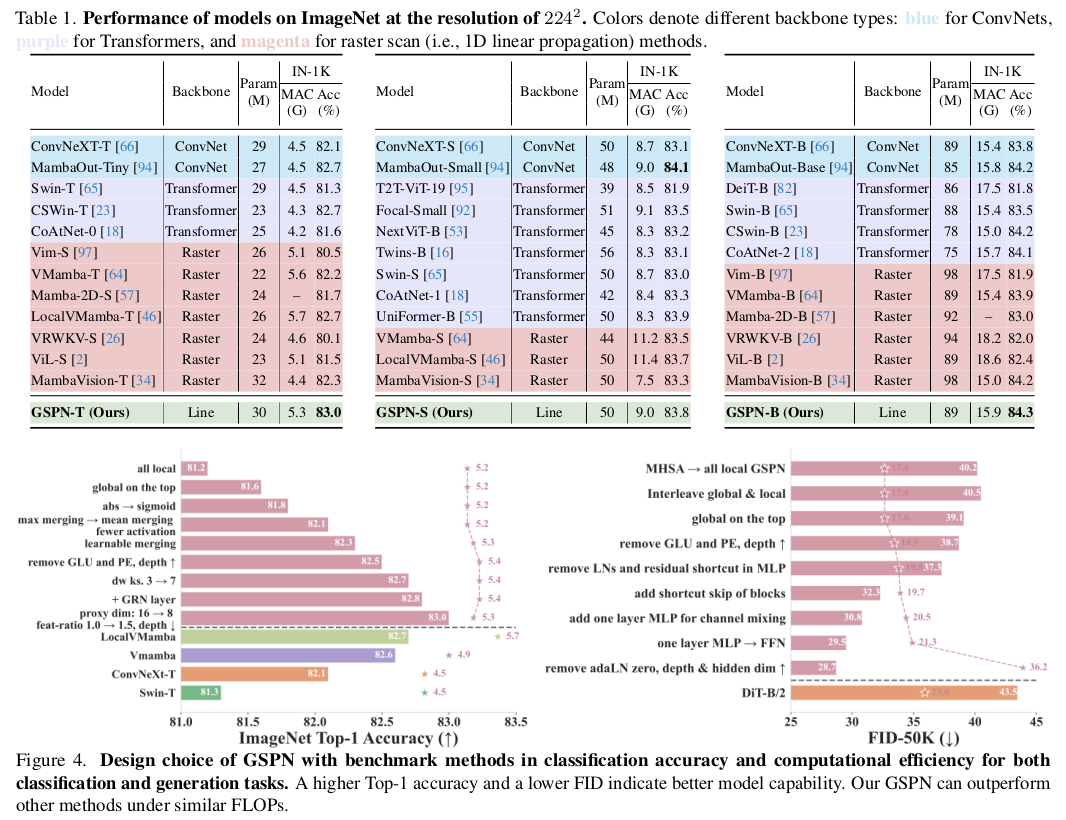 어마어마한 실험 비교. 하지만 뭐가 뭔지 잘 모르겠다. ㅋㅋ 결론은 위에 요약한 5가지인 듯. |
|
 |
 |
 |
 |
반응형
'Paper > Others' 카테고리의 다른 글
| Cameras as Relative Positional Encoding (0) | 2025.07.18 |
|---|---|
| Rectified Point Flow: Generic Point Cloud Pose Estimation (0) | 2025.07.14 |
| 4Deform: Neural Surface Deformation for Robust Shape Interpolation (0) | 2025.06.13 |
| Implicit Neural Surface Deformation with Explicit Velocity Fields (0) | 2025.06.12 |
| Neural Implicit Surface Evolution (0) | 2025.06.10 |