반응형
내 맘대로 Introduction

미친 논문을 하나 발견했다. 개인적으로 이렇게 파고드는 탐색적 연구가 멋있는 것 같다. 이 논문은 DINOv2, CLIP, SAM 등 foundation model이라고 불리며 general purpose feature를 뽑아주는 모델들을 보고, 단 하나로 융합할 수 없을까 고민한 논문이다. 쉽게 말하면 모든 VFM(vision foundation model)을 하나로 합쳐서 궁극의 모델을 만드는 방법을 고민한 것.
핵심은 기존 VFM 들을 multi-teacher로 두고 하나의 student를 학습하는 knowledge distillation이다. 단순히 결과 feature가 닮도록 loss를 걸어준다고 생각하기 쉽지만, 그 과정에서 각기 다른 dimension, feature magnitude, noise 등을 고려해야 하고 결국 다른 feature space를 합치는 것이기 때문에 extensive experiment를 동반할 수 밖에 없다. 결코 개인이 할 수 있는 수준은 아니다.
구현적으로 각각 엄청 큰 모델들인데, 이걸 GPU에 올려서 multi-GPU 학습시킬 수 있도록 세팅하는 것만 해도 장난이 아니었을 것이다. 여러모로 대단한 논문.
메모
  |
각기 다른 목적으로 학습시킨 vfm 이지만 공통점이 있다는 특징에 착안해서 합치는 방법론을 고민한다. 완성만 된다면 image, text, open-vocab 등 여러 도메인을 전부 담고 있는 궁극의 VFM이 나오는 것. 게다가 다른 VFM 보다 6배 빠르도록 architecture search한 것은 덤으로 알려주니 그야말로 궁극의 모델. |
  |
대상은 CLIP, DINOv2, SAM 각 필드에서 가장 유명한 것들만 하나씩 추렸다. 왜 SD는 안했냐, 왜 Sapiens는 안했냐 물어볼 여지가 없을 정도의 대표 모델들. |
 teacher 모델에서 뽑은 feature (class token이 있으면 class token까지) 를 student 모델의 feature + class token으로 이어주기 위해 dimension을 맞추는 작업이 필요. 2개의 head MLP로 된 걸 붙여서 class token과 feature dimension을 맞춰준다. 단순한 projection head. 데이터셋을 고르는 과정마저 그냥 떄려 박는게 아니라 train/test split이 서로 도메인이 겹쳤는지 아닌지 따져서 정말 student가 잘 배울 수 있는 데이터셋인지 사전평가하고 사용했다. |
  |
  |
summary라고 불리는 class token distillation 파트다. student의 token과 proj(teach class token) 간의 cosine distance로 비교한다. 단순히 l2, l1으로 하지 않기로 결정한 것도 다 실험 결과로 해보고 나서 비교한 것. |
  |
feature를 ditillation할 때는 cosine distnace + smooth l1으로 직접 비교하는 텀 하나더 추가. teacher마다 가중치를 따로 둬서 학습. -> 이것도 실험 무수히 하면서 찾았겠지.  기본적으로 CLIP 1 DINOV2 1 SAM 1 이런식으로 시작하고 SAM class token에 대해서만 0 SAM이 해상도도 1024로 다른 모델 대비 높고, 학습 원리가 달라서 오히려 방해가 될때가 있나 보다. |
  |
random scale, crop 해상도 점점 올리면서 학습 ---- 팁 DINOv2는 bilinear interpolation해도 feature가 쓸만함 |
 |
  이 파트는 진짜 디테일. 참고만. CRopped position embedding을 사용했다는 점만 기억. 이것 때문에 학습 완료 후 PE 모양이 다른 모델 대비 깔끔하고 노이즈가 없음. |
 |
DINOv2 보면 해상도를 높일 때 깨지는 현상이 있는데 노이즈가 끼고, 이게 PE 때문이었구나.  기본적으로 해상도랑 dimension 맞추는건 직관적이기도 한, upsampling / MLP를 사용함. 이부분은 간단 class token을 summary 로. |
 |
|
  |
새로 제안한 구조는 알고리즘적으로 새롭다기 보다 기존 아키텍처 중 좋은 아이디어를 긁어모아 조합한 구조. CNN이 속도가 transformer 대비 빠르다보니 CNN으로 시도했었으나 성능이 구렸다고 함. 따라서 CNN과 transformer를 섞는 방식으로 판단함. patch를 만드는 과정을 Stride convolution으로 진행 2 stage의 CNN block (yolov8 차용) 2 stage 의 transformer block이다. (SWIN 차용) transformer를 설계할 때도 full attention아니고 windowed attention으로 구현해서 속도를 개선함. 결과적으로 성능 저하 없이 속도 6배 빠르게 만들었다고 함. |
  |
|
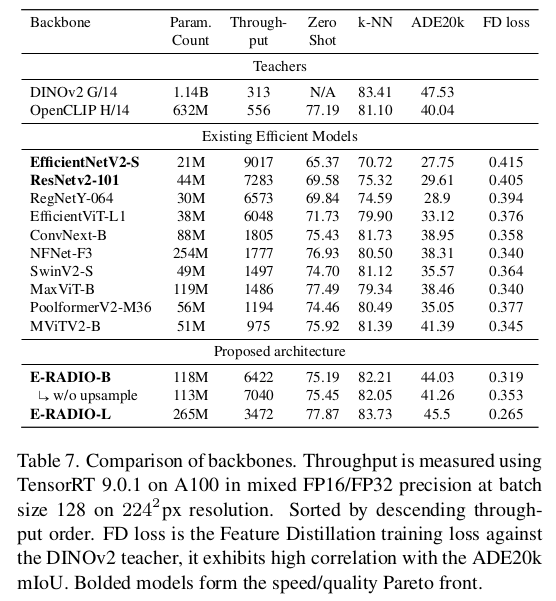 |
 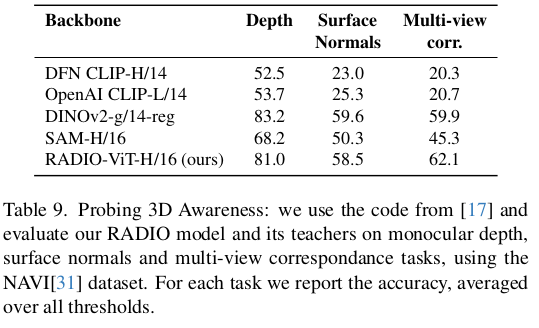 3D awareness는 암묵적으로 dinov2가 깡패라고 여겨져왔는데 dinov2랑 견준다. feature noise를 고려하면 RADIO가 더 좋은듯. |
 |
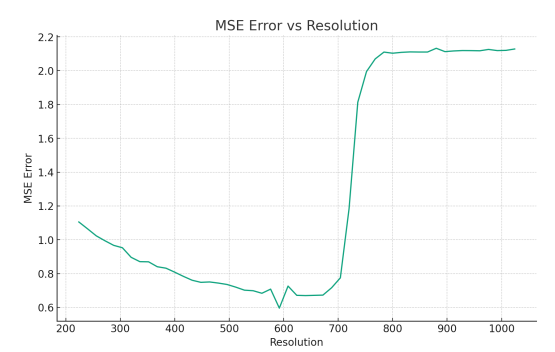 하나의 문제점은 입력 해상도를 자유롭게 바꿀 수 있는데 이 때 720을 넘어가면 feature space가 확 바뀐다는 문제다. -> v2.5 Tech.report에 이유 나옴 |
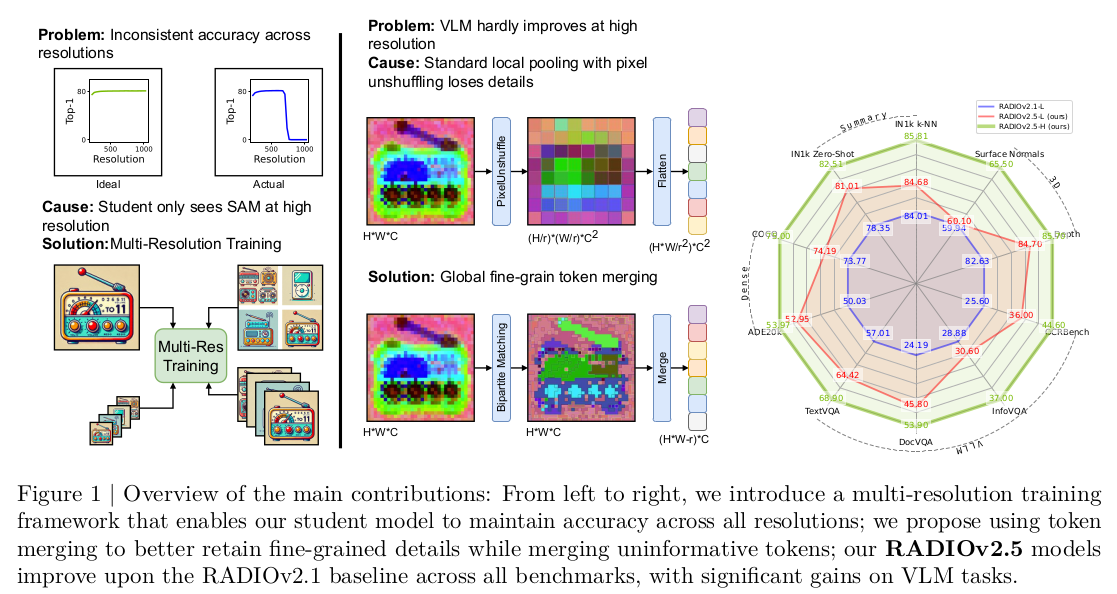 |
|
 |
v2.5 논문을 보면, 위 720px 해상도 이상에서 갑자기 feature space가 바뀌는 문제는 학습 시에 SAM 해상도가 1024, dinov2는 224에서 시작 이런 식이기 때문이라고 한다. 고해상도가 되어서야 SAM이 teacher 역할을 하기 때문에 고해상도일 때 SAM 쪽으로 bias가 걸린다는 것. 그래서 SAM이 개입했던 해상도부터 튀는 문제. -> v2.5에서는 multi-resolution 학습 법으로 이를 없앴다. 더불어 Language model (CLIP)이 high resolution 다룰 때 단점이 있는 local pooling을 포함하고 이쓴데, 이를 token mergin이라는 다른 방식으로 대체해서 성능을 올렸다고 함 -> v2.5는 괴물급이 되었다. |
반응형