반응형
내 맘대로 Introduction

이 논문은 Preface ++이라고 봐도 무방하다. 저자 라인도 똑같고 데이터도 똑같으며, 약간의 차이는 learnable latent가 함축해야 되는 정보량을 줄이고 decouple해서 성능을 조금 더 올리고 animatable하게 바꿨다는 점이다.
많은 사람 이미지로 학습시킨 NeRF prior model을 기반으로 few shot neural rendering을 잘하자는 논문.
메모
 |
|
 |
그림만 봐도 preface와 거의 동일하다는 걸 볼 수 있음 기존 preface에서 per-subject latent code W 하나만 conditional으로 제공해서 prior NeRF를 학습시켰다면 caface에서는 per-suject identity code, expression code, latent code W 총 3 분류를 conditional으로 제공한다. 직관적으로도, 전반적인 생김새와 표정 정보가 추가로 주어진 것이기 때문에 학습 난이도가 많이 낮아질 것처럼 보인다. ------------ 핵심 전제는 개쩌는 수준의 3DMM fitting이 있어야 된다는 것인데, 놀랍게도 애초에 데이터 자체를 3DMM에다 graphic을 입혀서 만든 것이라 오차 0이다. inference 시에는 약간의 오차가 있을 수 있는데 이 마저도 dense keypoint 500여개로 피팅해서 거의 없다. |
  |
 설명이 길지만 위 그림에서 identity, expression code가 concat되었다는 점 말고는 정확히 preface와 같다. |
 |
 오히려 핵심은 개쩌는 데이터를 만들었다는 점에 있다. 3DMM template mesh를 random generation한 다음, 직접 피부를 입히고, 안경을 입히고, 머리를 입혀서 위와 같이 만들었다.... 실사인 줄...  이정도 퀄되면 이렇게 된다고 한다. |
  |
3DMM code들은 이미 완벽하다고 보기 때문에 freeze 한다. 안경, 헤어같은 개인 외모를 담는 W 하나만 (preface에서 쓰던) 업데이트 한다. NeRF니까 photometric loss가 기본이고 prop은 mip-nerf에서 쓰는 일종의 regularization loss임. |
 |
이렇게 GT로 모델을 만들어두면 나중에 inference할 때 noisy한 3DMM 들어왔을 때 망가지는 것 아니냐고 걱정할 수 있다. ->실제로 망가질 것.  하지만 구글은 이미 500개가 넘는 dense keypoint를 정확하게 뽑는 keypoint detector가 준비 되어있어서 이걸로 피팅하면 사실 상 무시 가능하다고 함. |
  |
이를 이용해 fitting을 최소 3뷰에 대해서 하면, 카메라 파라미터를 역추정할 수 있는데 이게 꽤나 정확해서 뒤에 fine tuning에 바로 쓰인다고 한다. |
 |
few shot 입력이 들어와서 tuning을 할 때는 1) code W만 초반에 먼저 좀 업데이트해주고 2) code W랑 model 파라미터 둘 다 업데이트 -> 초기에 prior model 내에 어느 subject에 가까운지 찾아가도록 조금 기다려준 뒤, -> 주어진 입력에 더 맞도록 튜닝하는 방식. |
  |
튜닝 과정에서 few shot이다보니 artifact 들이 생길 수 밖에 없음  그래서 normal 크기 1로 억제하고, view direction을 encoding하는 파라미터 크기도 억제하고 마지막으로 한 ray 안에서 변화가 스무스하도록 (급격한 변화가 있으면 구름 같은게 껴있다는 소리니까) 강제해준다. |
 |
application 단에서 약간의 팁은 실제로 few shot을 찍는다 해도 싱크가 맞는 카메라로 찍지 않는 한, 약간의 표정 변화가 있을 수 있다. 따라서 few shot 간에 expression 파라미터는 interpolation해서 쓰는 방식이 좋다고 함. |
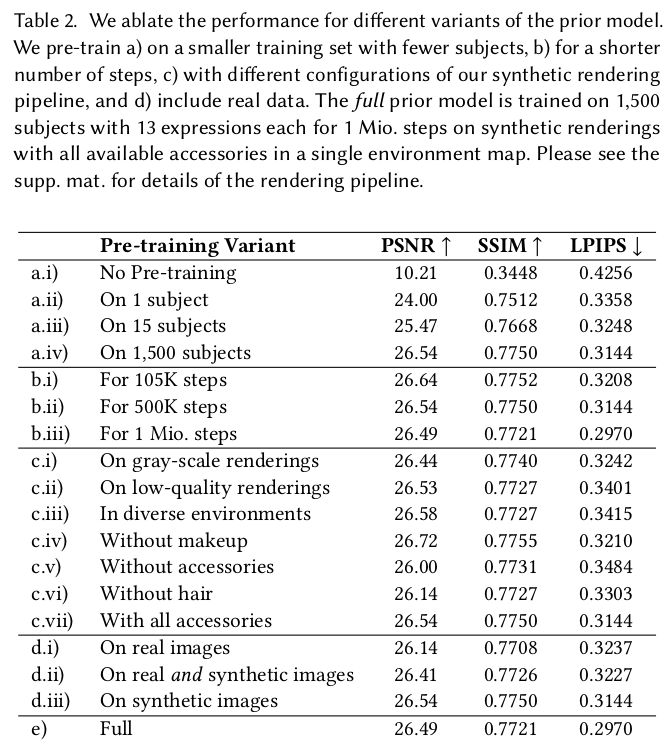 |
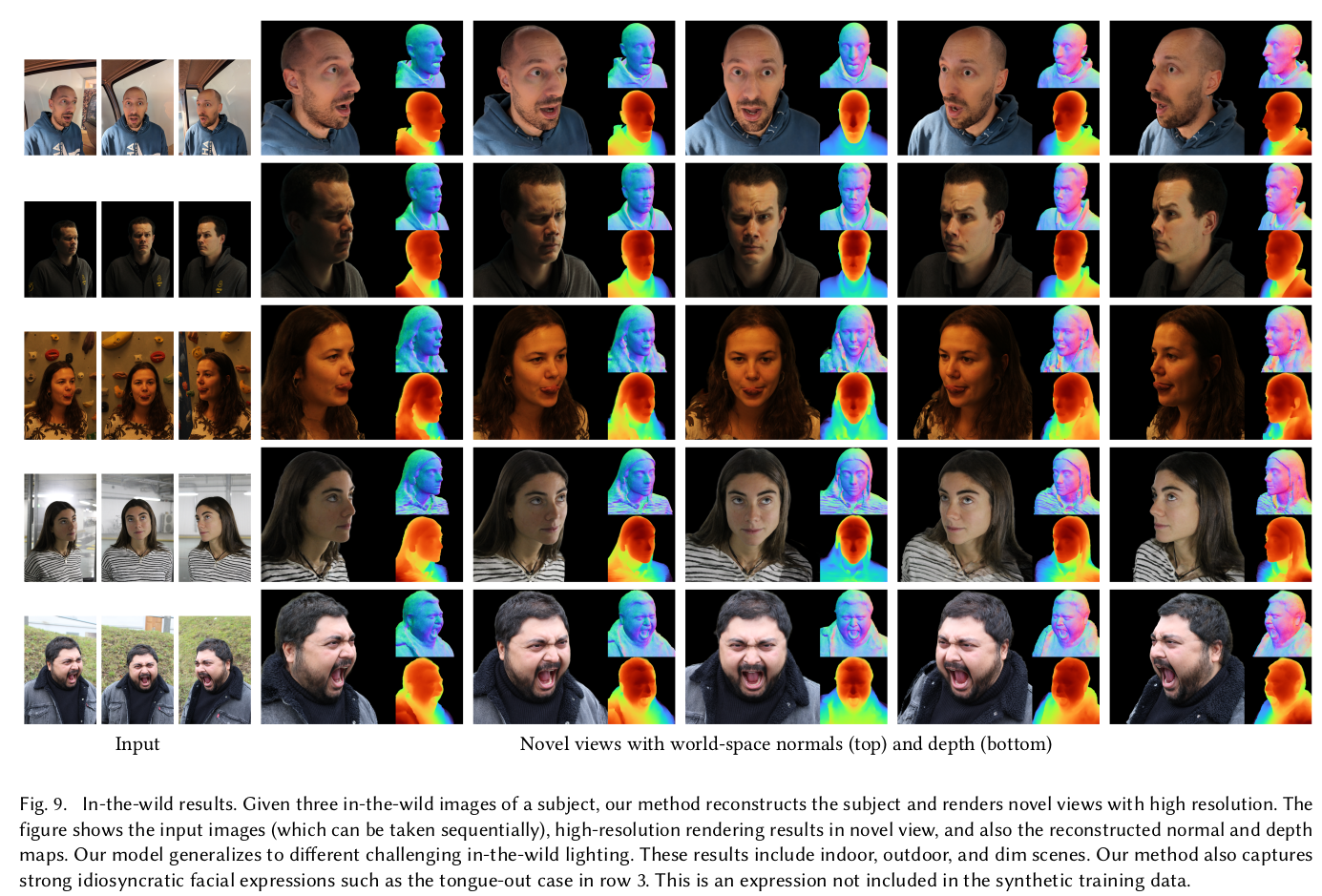
성능 좋다~ |
  |
  |
반응형