반응형
내 맘대로 Introduction

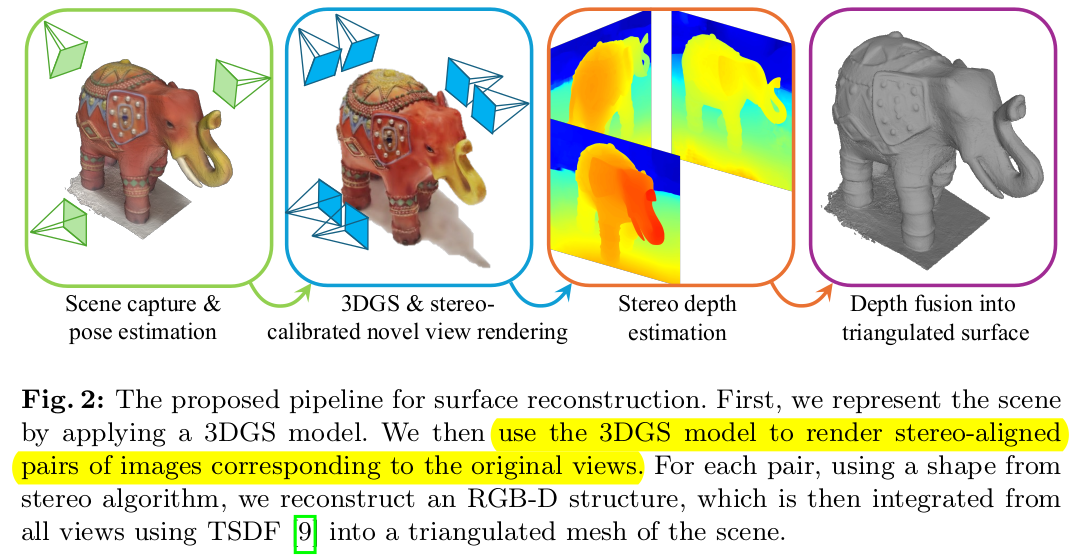
3DGS로부터 어떻게 mesh를 얻을 수 있을지 고민한 논문. baseline을 SuGaR로 잡은 만큼 어떤 방법론으로 Mesh를 만들었을지 굉장히 궁금했다. 약간의 아쉽게도 내용은 3DGS 복원 -> stereo view 렌더링 -> 별도로 feature matching 후 depthmap building -> TSDF recon 이다.
3DGS를 알고리즘적으로 변형했다기 보다 잘 학습된 3DGS로부터 stereo 이미지를 얻어서 시점 별 depth를 얻어낸다는, 어떻게 보면 활용에 관한 논문이라고 볼 수 있다.
stereo view 렌더링부터, 데이터 정리 feature matching, depthmap building, TSDF fusion 등의 과정을 얼마나 빠르게 자동화했느냐에 따라 속도는 달라지는 것이니 저 위에 1 hour로 빨라졌다는 것도 큰 의미가 있는 얘긴지 모르겠다.
메모
 |
|
 |
1) 3DGS 학습 2) 학습 때 사용한 카메라 위치 평행 이동 시켜서 stereo pair 생성 + 렌더링 3) depth map 만들기 4) TSDF fusion |
  |
사실 큰 내용 없다. 이 부분은. 1) COLMAP으로 카메라 자세 찾고 2) 3DGS (2D gaussian으로 찾았다고 하는데 큰 이유는 없는듯) 3) baseline b 만큼 옮겨서 stereo pair 생성 |
 |
feature matching은 여러개 써본 결과 DLNR이 가장 좋았다고 함 이게 DTU 데이터셋같이 open data에서 테스트한 것이라 해당 데이터 distribution과 비슷한 데이터로 학습한 모델이 제일 잘나왔을 확률이 있다. 따라서 모든 상황에서 DLNR이 좋다고 볼 순 없을 듯. --- disparity sanity check로 masking 추가. |
  |
depth가 baseline 4배 ~20배 범위 안일 때만 사용 baseline이 stereo로 구하는 depth 범위를 직접 결정하긴 하니까 합리적인 필터 |
 |
시점 별 depth가 확보된 상황이니 TSDF fusion으로 mesh로 바꾼다. marching cube 당연히 사용. |
 |
 이젠 DTU에서 비교하는게 의미가 있나 싶다.  |
 |
 |
반응형