반응형
내 맘대로 Introduction

Meta가 요즘 Visual geometry group이랑 연구를 활발히 하는 것 같은데, 아무튼 meta에서 DUST3R와 결을 같이 하는 3D geometry estimation 논문을 공개했다. 아카이브 공개가 3월 14일이니 일주일도 안된 논문.
head에 따라 camera parameter, point map, depth map, feature point 등 동시에 예측할 수 있고, 수백장을 동시처리하는 성능을 보인다고 한다. 핵심은 DUST3R와 거의 유사하지만, backbone을 transformer 1개로 묶어버림으로써 N장 처리 능력을 확보하고, 어떤 구조가 좋을지 고민했다는 점이 차이점.
메모
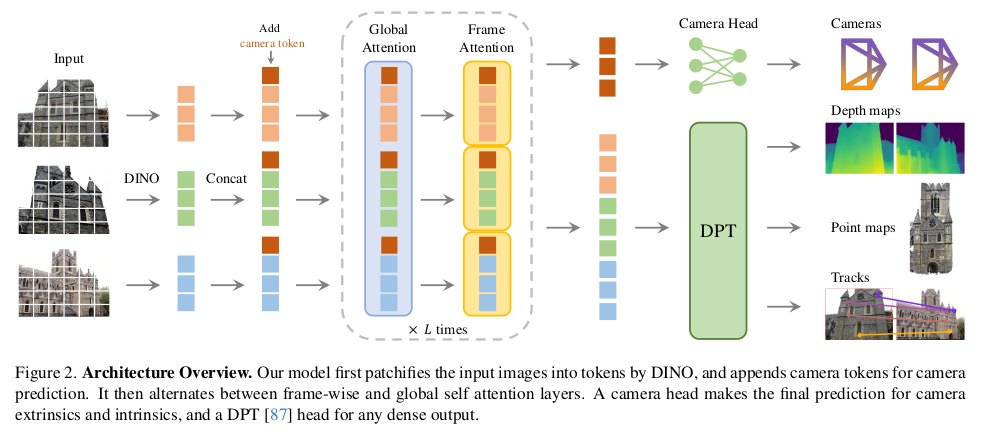 | |
 | 이미지 N장을 DINOv2를 통해 token화 하고 입력으로 받는 구조. 초거대 Transformer 1개가 본체. 뒤에 DPT를 붙이면 dense prediction이 필요한 depth map, point map, feature map이 나오고 MLP를 붙이면 camera parameter 가 나오는 방식 동시에 학습했다. -> 덩치가 어마어마하게 크고 64 A100으로 9일 학습시켰다고 할 정도. |
  카메라 파라미터는 fx, fy (cx,cy는 이미지 중심으로 가정해서 생략), quaternion, translation 이다. depth map은 normalization 없이 그냥 통째로 학습함. [0, inf) 범위로 그냥 학습. 데이터셋 규모를 키워서 해결하는 방법. |  새로운 downstream task로 keypoint tracking을 들었다. 약간 feature matching head 같은건데, query y에 대해서 N-1장 내 correspondence를 찾는 문제를 tracking으로 풀었다. Cotracker2에 입력으로 넣을 수 있는 feature map을 출력으로 내도록 했다. |
  | 첫 프레임이 무조건 처음으로 들어가고, 특별 대우함. 첫 프레임이 reference가 되기 때문. 뒤에 추가되는 token들도 첫 프레임 것들은 독립적으로 구성했다. ---- head를 보면 camera parameter는 point map을 역추정할 수 있고, point map은 camera parameter와 depth map으로 추정할 수 있는 서로 얽힌 관계임에도 별개로 head를 만들어 두었다. closed-form으로 얽힌 문제를 굳이 독립적인 것 마냥 head를 구성한 이유는 단순히, 이렇게 하는게 성능 gain이 있었기 때문 --- depth map + camera params > point map 성능 구도가 나온다고 짧게 적어주기도 함. |
   | backbone은 DINOv2 토큰들을 입력으로 받는 거대 Transformer다. DINOv2를 Freeze했다는 말이 없는 것으로 보아, 학습을 같이 하는 것 같은데, 이를 포함하면 더 크다. --- 거대 트랜스포머의 세부 구조는 전부 self-attention으로만 구성되어 있다. 전체 N 시점 통째로 self attention 각 시점 k 마다 self attention 을 반복하는 식이다. 전체를 봄과 동시에 개별적인 시점 정보가 분리되도록 계속 반복해주는 구조. ----> 나중에 결과물을 시점 별로 꺼내쓰기에도 용이함. |
  | 카메라 파라미터를 예측할 때는 camera token 1개 register token 4개 ( 그냥 dummy token이고 학습 끝나고도 그냥 무시하는 token인데, 이렇게 여분을 넣어두면 성능이 뛴다는 meta 논문이 있기 때문에 추가한 것) image token k 번째 시점 1개 가 입력이다. |
  | 첫 프레임이 기준이므로 0번째는 identity로 남아있고, 나머지 N-1 프레임에 대해서 quaternion, translation, focal length (총4+3+2) 개를 예측 |
 depth map, point map, feature map은 전부 DPT를 붙여서 예측 DPT를 각각 붙인게 아니다. DPT 1개가 모든 걸 채널 방향으로 한번에 예측 (이게 잘되네...) |   DPT 결과 중 feature map에 해당하는 채널부터는 잘라내서 뒤에 CoTracker2(transformer 기반 feature matcher)에 입력으로 넣는다. DINOv2 + VGGT + DPT + CoTracker2까지 한번에 학습한셈.... 엄청 거대하다. |
 |  loss는 최고 단순하다. HUBER LOSS를 썼다는 사소한 점을 빼면 단순히 distance 기반 loss로 최적화했다. depth, point map는 raw vs GT normalization 없이 박치기 했다. (데이터 셋이 엄청 커서 가능한 듯) gradient term이 하나 추가 되어서 smoothness를 챙긴 점만 차이점. |
 | data normalization을 별도로 하면서 학습하지 않지만 이미지가 resize 되거나, reference frame이 바뀌면 scale이 달라질 수 있는데 이를 해결하기 위해서 reference frame의 scale에 맞춰서 각 시점 k 도 맞췄다고 한다. 단 output을 건들지 않고, 학습할 당시에 GT를 그렇게 자동 scale했다는 것. 네트워크가 이것마저 알아서 배우도록 했다. |
 1.2 billion..... 해상도는 518X518을 aspect ratio를 1/3-1조절하면서 학습 |  이 세상 존재하는 거의 모든 3D scan 데이터를 다 쓴 것 같다. |
   | |
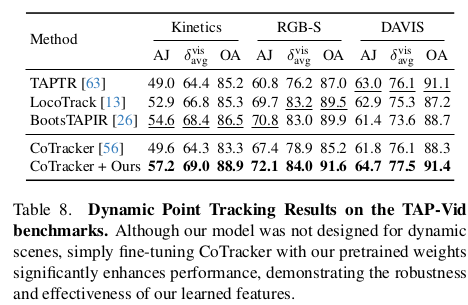
 RoMa 마저 이기는 성능. head를 다 같이 붙여서 학습하는게 성능에 좋다. 다른 task에 사용될 feature가 또 다른 task에 도움이 되는 현상. |   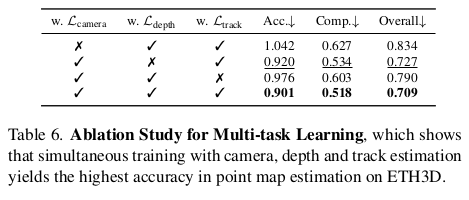  |
 |   |
 |
반응형