반응형
내 맘대로 Introduction

DUST3R의 dynamic scene용 fine tuning 버전이다. 논문보다 테크니컬 리포트에 가깝고 내용도 굉장히 짧다. 컨셉만 설명하고 마무리함. DUST3R의 아이디어 자체가 굉장히 좋고 성능도 압도적인 탓에 많은 관심을 받는 중인데, 이 논문은 UC Berkeley, Google deepmind, stability AI, UC Merced 등 네임드에 있는 사람들이 모여 프로젝트성으로 진행한 것 같다.
기존 DUST3R가 static scene에 대해 학습된 네트워크이다 보니 dynamic object가 등장했을 때 이 dynamic object 영역을 틀어 맞추려고 하다 망가지는 경우가 있다. 이 문제를 짚으면서 데이터셋을 dynamic object를 커버하는 데이터셋으로 바꿔서 튜닝한 논문이다.
핵심 아이디어는 없다. 그냥 point map GT A, B 가 dynamic object를 포함하는 데이터로 들어가는 것일 뿐이다. 이러면 기존 DUST3R가 static scene과 dynamic scene을 알아서 분리하도록 학습하는 것.
약간의 트릭이라고 하면 scratch 부터 학습하기엔 너무 많은 데이터가 필요하므로, encoder를 고정하고 decoder만 튜닝한 것이다.
메모
 |
DUST3R는 dynamic object 있으면 이렇게 망가짐. |
 |
그냥 dynamic object를 masking out하는 건 성능 drop도 있고, dynamic object 부분 복원을 포기하는 것이라서 딱히 메리트가 없음. |
 |
그래서 DUST3R를 튜닝하되, 이미지 A, B를 인접한 프레임으로 구성해서 dynamic object가 있는 상태로 학습해보는 것. |
   |
데이터는 없다보니 synthetic을 최대한 활용 -> 이 문제 때문에 fine tuning 컨셉으로 간 것. |
 |
1~9 프레임 차이에서 샘플링해서 학습하고 FOV 바꿔가면서 augmentation 512 해상도로 학습. |
  |
학습 후 활용은 DUST3R와 같다. 정확도가 dynamic scene에서도 올라갔으므로, RANSAC으로 static point만 뽑아서 쓰면 된다는 논조. |
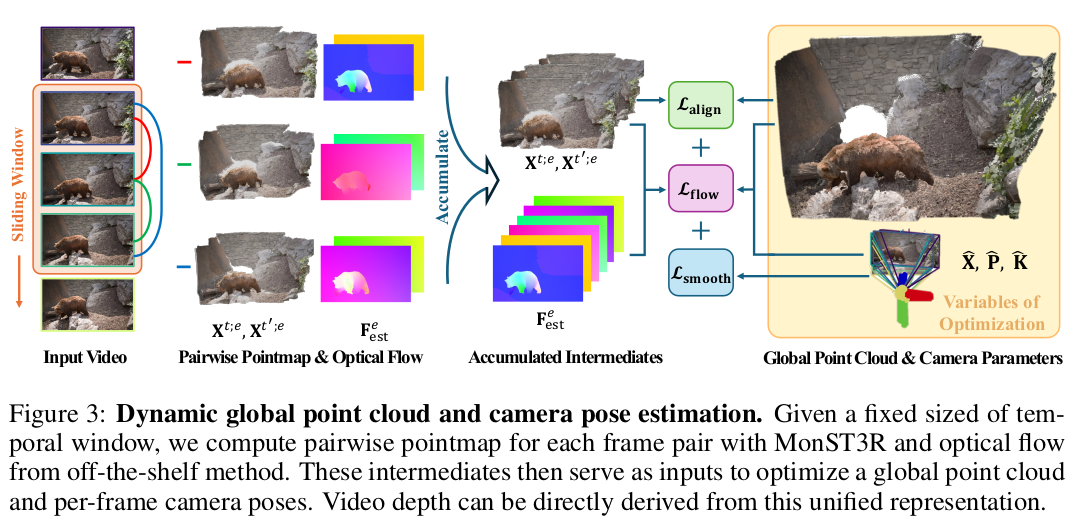 |
optical flow만 붙여주면 통합하는 것도 쉬움. |
 |
 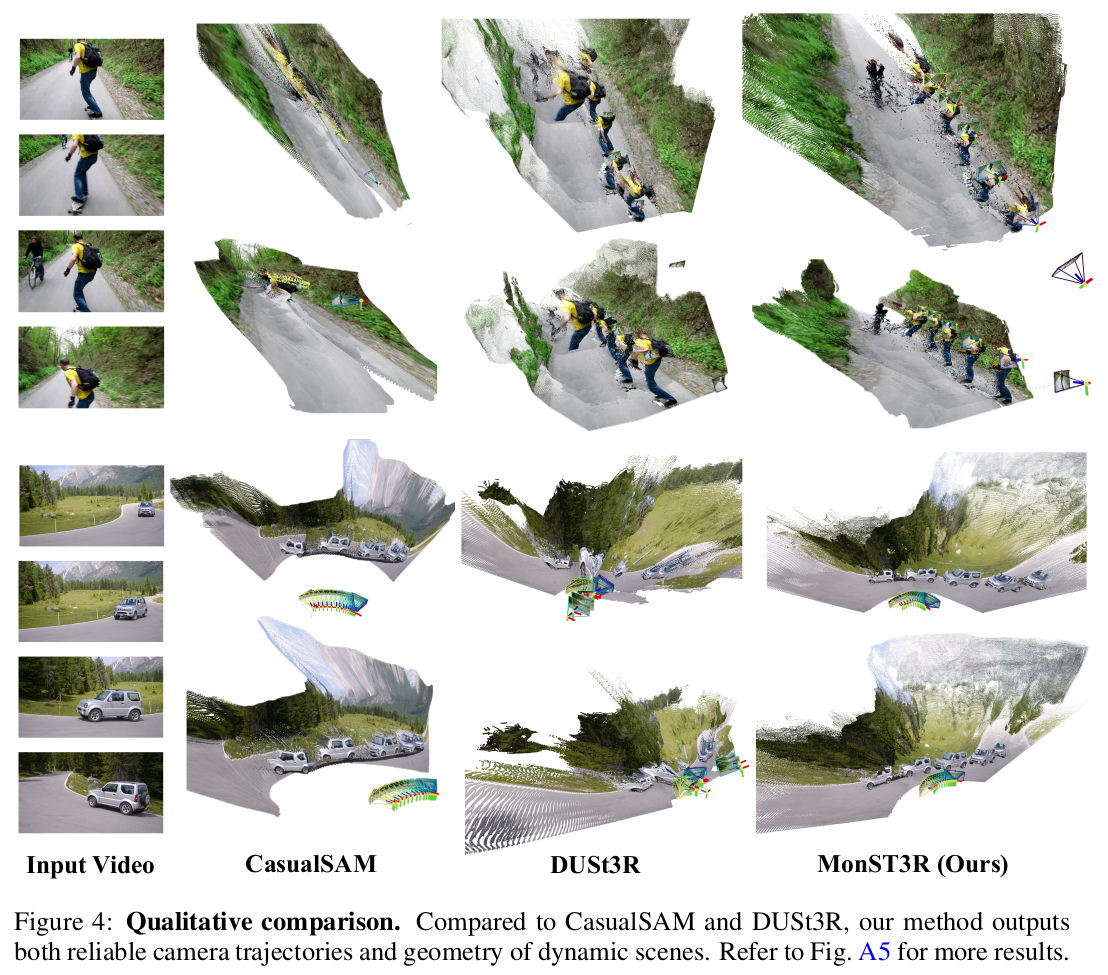 |
반응형