반응형
내 맘대로 Introduction

DUSt3R이 쏘아올린 작은 공 후속편. monocular point map estimation이다. monodepth 추세가 DUSt3R로 인해 mono pointmap으로 넘어온 듯 하다. 단일 입력을 받고, intrinsic에 상관없이 normalized scale의 point cloud가 나오는 방식
DUSt3R과 구조적으로 single input을 받는다는 차이점 외에 focal length ambiguity를 해결하기 위해 scale 에 더불어 translation까지 고려한다는 차이점이 있다. 직관적으로 focal length가 다르면 물체가 다르게 보이기 때문에 같은 위치의 point cloud를 예측하기 힘드니까, translation을 같이 풀어주는 느낌
이외에는 규모의 논문이다. 데이터셋을 21개나 써서 대규모 학습을 해서 성능을 뛰게 만들었다.
메모
 |
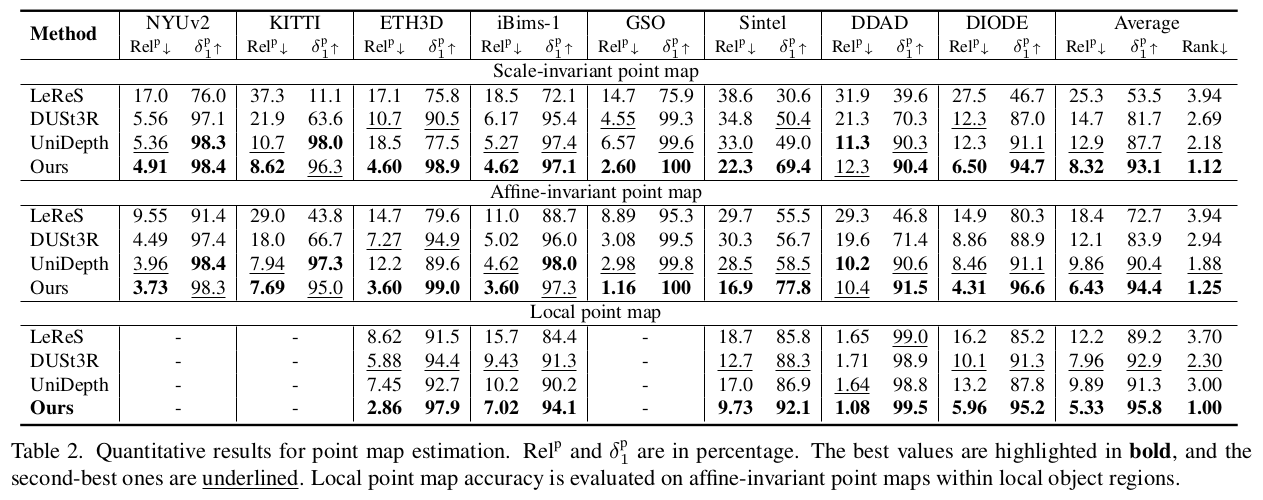
mono pointmap 논문이 기념비적인건 없다보니 monodepth랑 비교를 한다. focal length가 바뀌는 상황에서도 얼마나 invariant하게 예측해내는지 지표가 훨씬 더 정확하다는 점을 짚음. 아무래도 focal length 차이를 커버할 수 있는 translation term을 추가했기 때문으로 보이고 데이터 규모도 한 몫 했지 않을까. |
 |
|
 |
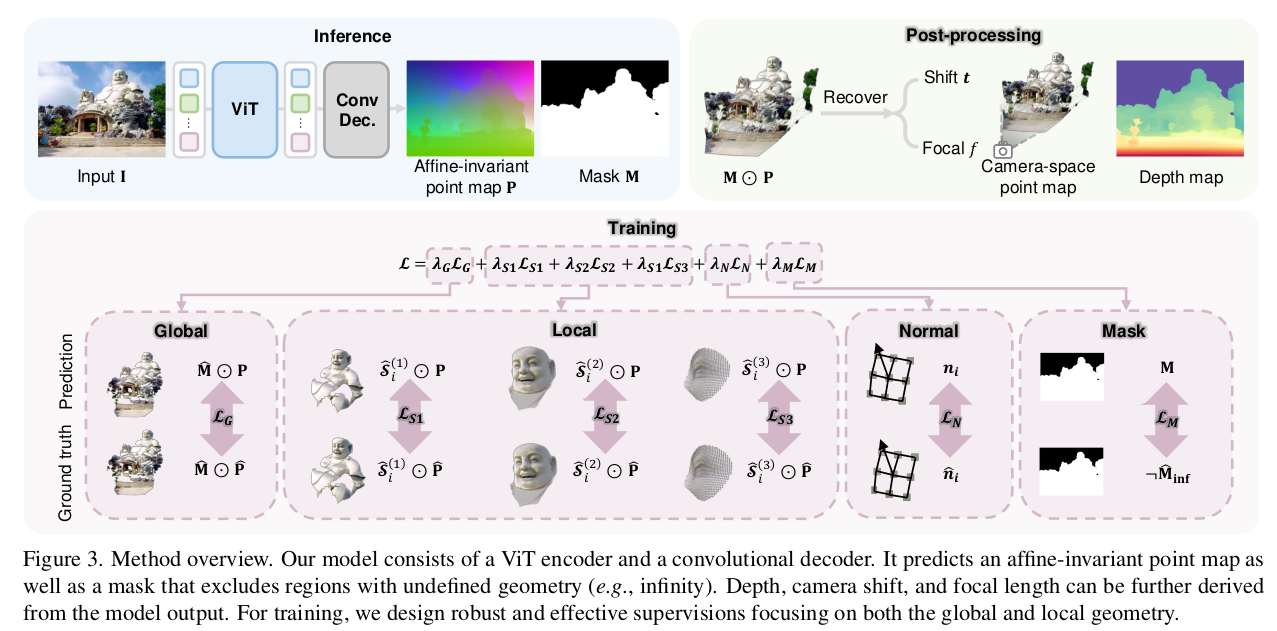
vit (trainable DinoV2) encoder + conv decoder구조 point map xyz + confidence mask loss는 global하게 맵 전체를 gt랑 비교 local 하게 3단계 patch컨셉으로 gt랑 비교 (이건 데이터셋마다 GT 정확도가 다른점 때문에 가장 효과적으로 활용하기 위한 방향을 찾은 것 같음) normal도 supervision에 추가. |
 |
|
  |
가장 가장 핵심은 기존에는 point map xyz가 나오면 그냥 scale만 normalize 해서 사용했던 것을 sP+t와 같이 point map에 residual translation을 더해주는게 추가됐다는 점이다. s(P+t*) 로 쓰는게 더 이해가 쉬워보임. 뒤에서 t*=t/s라고 정의함 이유는 위 그림과 같이 focal length가 다르면 같은 물체도 더 멀리 혹은 더 가깝게 보이는데, 이걸 데이터만 믿고 scale로만 커버하면 정확성이 떨어진다. 실제로 focal length가 다르다는 것은 이미지 평면이 대상과 더 멀거나 가깝다는 뜻이므로 z축 방향으로 이동량이 발생했다는 뜻 따라서 뭔진 모르지만 t(zx)가 있어야 더 정확해진다는 논조다. 여기서 principal point cx cy까지 고려하면 머리가 아프니 일단은 이미지 중심이라고 생각하고 tz만 생각했다. |
  |
문제는 tz를 모른다는 점. GT 조차도 이런 내용을 커버하고 있진 않다. 따라서 후처리로 푼다. prediction값을 이용해 한번 최적화 돌려서 찾은 뒤 이를 이용한다. focal length f와 tz를 unknown으로 놓고 현재 예측 point map이 제 위치로 프로젝션 되도록 최적화해서 f랑 tz를 찾아준다. 이거 suppl 보면 그냥 LM solver붙이면 돼서 scipy로 간단하게 된다고 한다 3ms 내에. -> 찾은 f는 버리고, tx만 뒤에 사용한다. 결과적으로 1) point map prediction 2) solve Eq.2 3) +tz 4) 최종 결과! |
 |
실제 사용할 때 sP+t 형태로 구성된다고 가정해서 후처리로 최종 결과를 만들어내는 만큼, 학습 과정에서도 sP+t 컨셉을 넣고 후처리 됐을 때 정확한 GT랑 맞아 떨어지도록 해야 한다. 근데 문제는 위에서는 point map을 믿는다고 가정해서 focal length, tz를 찾아서 최종 결과를 만들어내기만 하면 되지만 학습 때는 scale도 필요하다는 점. 위와 같이 focal length를 찾아서 역추정하는 방식도 있겠지만 noisy point map을 갖고 그렇게 하는건 수렴을 안할 가능성도 높아 보인다. 따라서 학습 때는 scale, trans를 따로 최적화로 찾아준다. |
  |
학습 과정에서 최적화가 같이 돌도록 GPU solver를 하나 붙였다. 지금 가정이 principal point가 이미지 중심과 일치한다는 가정이므로 수식을 쭉 전개해보면 s* z'+ tz - z = 0 인 상황이 최적값이다. 다른 말로 scale 하고 trans xyz를 풀게 아니라 scale + tz로만 풀수 있다는 것 s*z' + tz -z = 0 과 같이 closed form이 구성되므로 변수 바꿔치기로 scale에 관련한 수식만으로 축소할 수 있다. 그러면 solver 구현도 쉬워서 O(N^2 LogN) 복잡도 안에서 해결이 가능하므로 학습에 이어 붙일 수 있었다고 한다. ------------- 말이 길었는데 predicted point map 갖고 간단하게 scale + tz 찾을 수 있어서 수식(4) loss 빠르게 먹일 수 있다는 것. |
  |
또 하나의 loss는 local patch loss 같은 컨셉이다. point map이다 보니 neighbor point cloud를 단위로 동작한다. 1) 이미지 grid에서 픽셀 크기의 1/4, 1/16, 1/64 총 3가지 크기의 cone을 만들어서 2) 원하는 center point의 주변 반경을 계산한 뒤 3) sphere 범위 내 point 들을 neighbor point라고 분류 4) neighbor point끼리만 앞서 이미지 전체에 걸어줬던 loss 추가 ---- 이렇게 하면 국소적으로 scale, t 최적화해서 loss가 걸리므로 local detail이 살아나는 효과 ++ 데이터 셋마다 GT 정확도가 다르므로 radius를 크게 잡았을 때는 GT 정확도가 낮은 애들, radius를 작게 잡았을 때는 GT 정확도가 높은애들을 쓰는 방식도 가능해진다. |
 이웃 pixel의 point끼리 cross product로 normal 구한 것으로 supervision 추가 smooth한 결과 예측에 도움이 되는 듯. |
 |
  |
 데이터셋을 다 긁어모아 900만장 + curation해서 데이터 도메인 분포가 비슷하게 + GT 정확도에 따라 local loss를 단계 별로 활성화 + DinoV2로 시작해서 다양한 augmentation. |
 |
  |
 |
  |
반응형