반응형
내 맘대로 Introduction
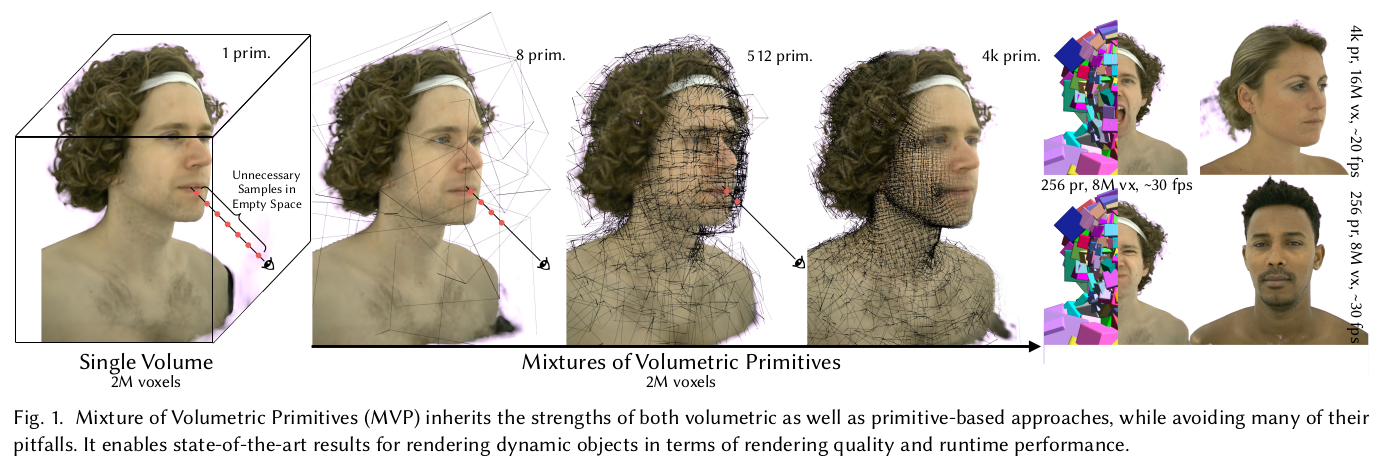
이 논문은 2021년에 나와서 꽤 된 논문이긴 하지만 눈에 띄어서 그냥 읽었다. 핵심은 3D scan sequence (+image)가 주어졌을 때 빠르게 렌더링 가능한 형태로 어떻게 만드느냐 이다. dynamic scene rendering을 어떻게 할 것이냐를 고민한 논문.
핵심 아이디어는 mesh face 마다 직사각형 형태의 primitives를 할당하고, 나중에 렌더링할 때는 이 primitives만 읽어서 빠르게 렌더링하는 방식이다. 요즘 3DGS가 유행하는데, 사실 같은 컨셉을 보다 일찍 구현한 논문이라고도 볼 수 있겠다. 개인적으로 3DGS의 선구적 증명인 것 같다. 이 논문을 개선해서 3DGS가 탄생했다고 해도 괜찮을 수준.
메모
  |
이 당시에는 NeRF가 neural rendering의 정석이었기 때문에 메모리 사용량과 속도를 지적한다. mesh처럼 explicit representation이 있으면 렌더링 속도가 압도적으로 빨라지는 것 가져와서 합치기 위한 고민들. 결과적으로 face마다 뭔가를 할당하고, 이를 이용해 렌더링해서 속도를 빠르게 하자는 결정을 한듯 -> 3DGS의 고민과 정말 유사하다. |
 |
일단 데이터부터 준비한다. multiview sequence가 주어진 상황이니, 자체 개발한 (이전 논문있음) mesh reconstruction + tracking 알고리즘으로 모든 sequence를 같은 topology하에 복원해둔다. |
 |
그리고 각 mesh face 마다 volume primitives (위치, 크기, 방향 포함)을 할당한다. 그리고 각 volume primitives는 세부적으로 voxel로 쪼개져있도록 했다. 초기화만 face를 사용하고 수렴 과정에서 vp가 맘대로 돌아다니도록 하면 의미가 없으니 face에 조금 얽매여있을 수 있도록 위치와 방향은 face 대비 상대값으로 설정해두었다. |
  |
그리고 각 vp가 전체 volume 내에 동일한 값을 갖도록 설정한다면 vp가 조금만 넘어가서 특정 ray에서 쓸모 없다고 판정되면, 다른 ray에서는 쓸모가 있어도 opacity가 낮아질 가능성이 있음. 즉 edge에서 어떤 ray에 걸리냐 안걸리냐 때문에 gradient가 불안정해짐. 따라서 vp 내 voxel마다 가중치 필터를 씌운다. -> gaussian filter 곱해서 scaling하는 것과 같음 -> 사실 3DGS 와 같아지는 컨셉. -> 이게 정말 똑같은 것 같다. |
 |
모델 구조는 VAE가 큰 틀을 잡아줌 매 frame의 mesh 통째로 입력-> latent로 압축 256 decoder가 256을 받고 2D 형태로 uv map 표현법을 갖는 primitives map을 뱉는 형태 |
 |
encoder는 구체적으로 언급하지 않는다. 그냥 Nx3 + Nx3 입력으로 통째로 받는 encoder이겠거니 |
 |
|
  |
decoder는 크게 4개로 나뉘어져있음 vp 단위 1) vp position 예측 2) scale, residual rotation, residual position 예측 vp 내 voxel 단위 1) opacity 2) rgb 전부다 2D convolution을 통과시켜 UV domain에서 map 형태로 예측함 -> 이렇게 하는 것이 convolution 힘으로 locality 챙겨서 더 효과가 좋음. |
  |
배경은 딱히 고려 안해도 될 것 같았지만, 따로 모델을 만들어두었다고 함. 사람이 있는 상태에서 찍은 이미지 말고 사람 없이 찍은 배경 이미지를 이미 들고 있다는 가정 하에 기본 배경 + 사람과 배경의 interaction으로 생기는 차이 (occlusion, 그림자 등) 후자만 학습함. ------ 정해진 각도의 기본 배경 이미지에 더하는 방식이기 때문에 임의의 각도에서 배경 렌더링은 안됨 -> 이걸하는 이유는 대상 복원할 때 배경으로 인한 변화를 담당하는 모델을 따로 두어서 대상 복원 성능을 높이려고 한 것 같음. |
  privimitives를 이용한 렌더링 파트인데 3DGS와 컨셉이 같다. ray마다 intersected privimites 사전 계산해서 빠르게 렌더링. |
 |
 photometric loss가 당연히 기본 |
  GT가 있으니 vertex supervision + vp가 너무 크지 않도록 volume이 작도록 유도. |
  |
|
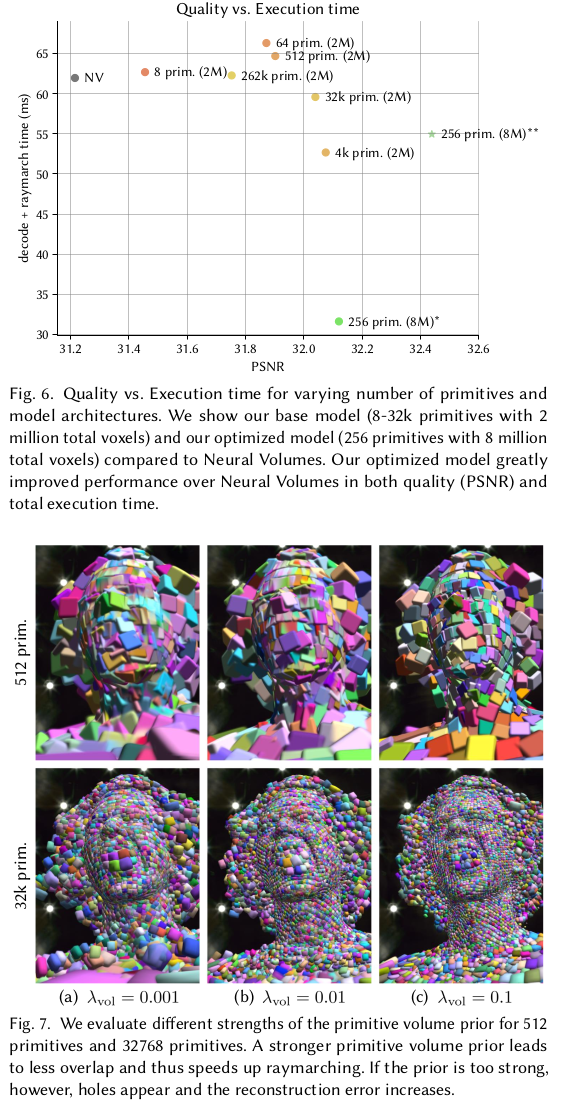  |
 |
 |
반응형