반응형
내 맘대로 Introduction

딥페이크가 한창 유행할 시기, 2020년 디즈니에서도 연구했던 face swap 2D model이다. 이제는 4년 전 알고리즘이라 아주 낡은 기술이 됐다. 앞선 논문 읽다가 래퍼런스 달려있길래 그냥 간단히 읽어봤는데, 구석에 두긴 아까워서 초간단 메모만 남겨둔다.
메모
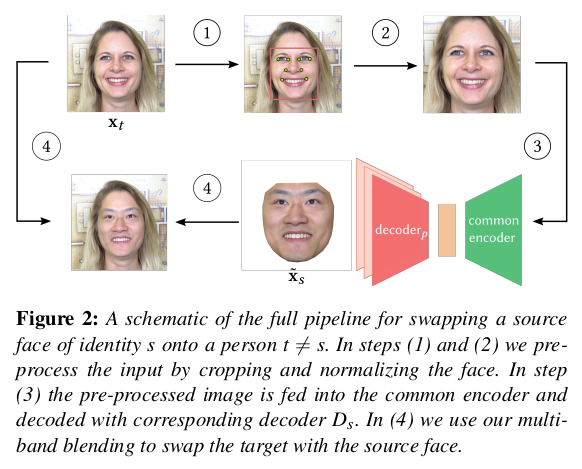 디즈니 연구팀은 예전부터 Auto encoder 구조를 엄청 좋아하는 것 같다. 개인적으로 엄청 효과적인 구조라고 생각하긴 하지만 이런 방식 논문이 자주 등장한다. |
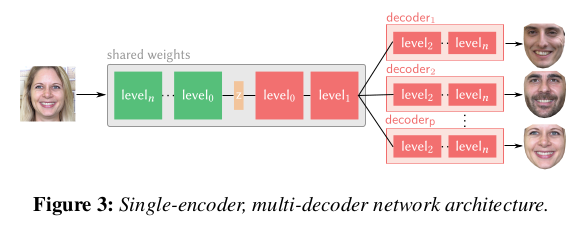 identity에 상관없이 human to latent로 보내는 encoder를 하나 shared weight로 학습해두고 decoder는 일부만 shared weight, 나머지는 사람 specific하게 N개를 따로 두는 구조. |
 |
1) 데이터를 1024 1024로 눈코입 기준으로 이미지 중앙에 얼굴이 위치하도록 normalization해서 준비 -> 아래 논문에서 상세설명 되어있지만, 이건 과거에 각종 off-the-shelf 알고리즘이 없을 시절이라 이제 굳이 볼 필요없음. 2) Auto encoder 통과 (decoder는 원하는 대상) 3) 이미지에 stitching. (denormalize) |
  내용이 길지만 shared encoder, seperate decoder를 주어진 모든 데이터를 활용해서 학습 완료 시키고 loss는 생성된 이미지를 마스크 영역만 SSIM으로 비교하면 끝. |
  |
 2D face swap은 이미 완성된 수준이어서 이젠 그냥 과거의 유물 정도로 보면 될 듯. |
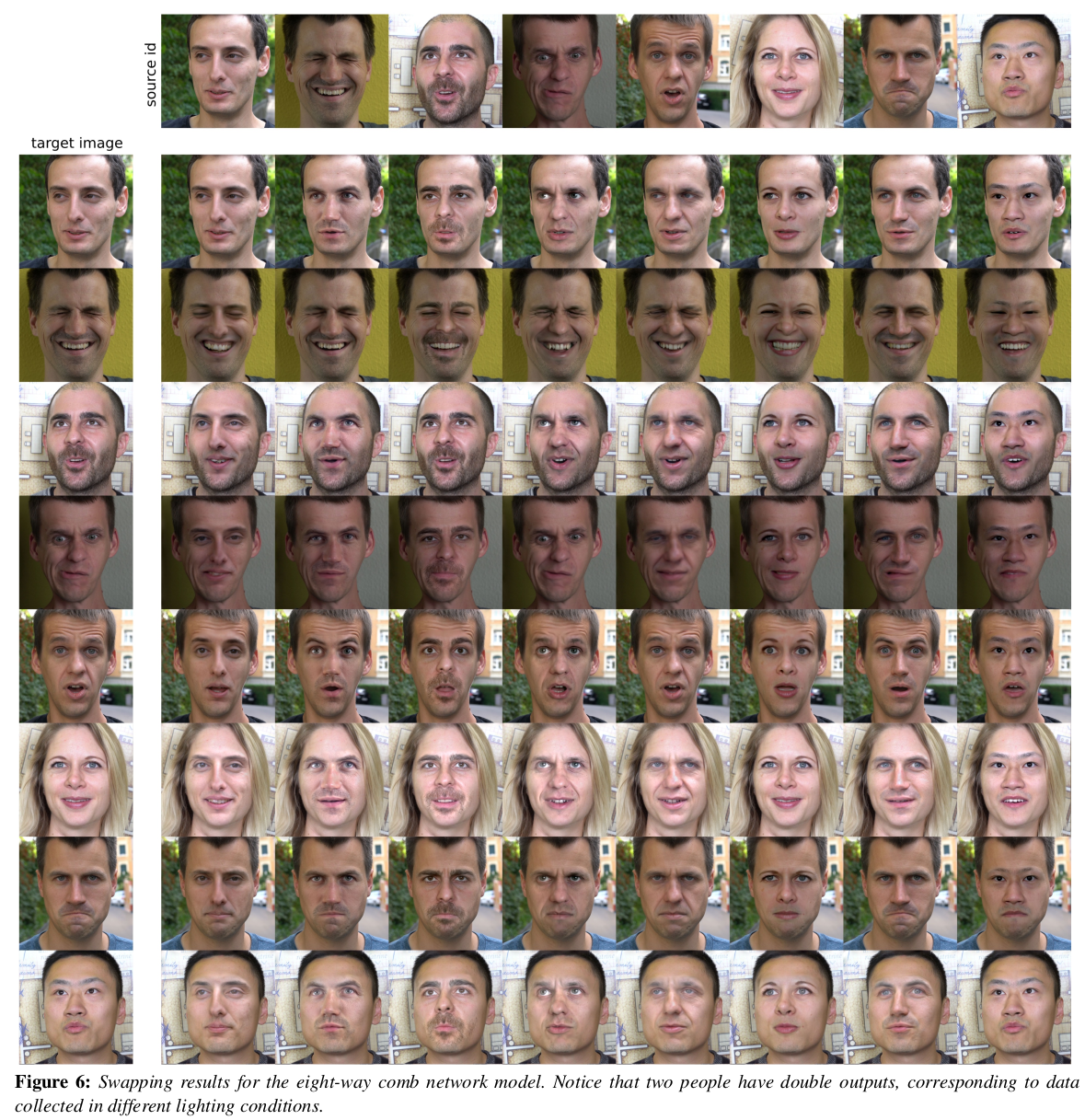 |
 shared encoder를 쓰는게 좋다. N=2라고해서 encoder 마저 speicific 하게 가면 더 잘 될 줄 알았는데 face prior를 오히려 더 못찾아서 성능 저하로 이어지나봄. 이 사실은 참고할 만 한듯. |
  |
반응형