반응형
내 맘대로 Introduction

이 논문 역시 요즘 보고 있는 디즈니 시리즈 논문 중 하나. 2016년 나온 논문으로 시간은 좀 됐지만, 지금 다시 봐도 성능이 매우 좋긴 하다. Local Anatomically-Constrained Facial Performance Retargeting 에서 다루는 핵심의 95%는 사실 이 논문에서 나온 내용이고 위 논문은 오히려 이 논문의 활용에 가까운 논문.
bone, bone normal + thickness로 face mesh를 정의하는 것 + patch 단위로 deformation하는 방식 자체는 이 논문에서 나왔다.
이 논문 역시 일반 이미지 입력이 주어졌을 때 face mesh를 복원하는 것이 아니라, face capture system을 이용하여 웬만한 정보 (e.g., bone+jaw fitting, 2d dense face tracking with marker)가 이미 주어진 상황에서 이를 이용해서 face mesh를 복원하는 내용이다. 따라서 일반적인 문제를 풀기 보다 실제 산업에서 겪었던 경험치에서 나온 문제를 푼 논문. 그렇지만 매우 좋은 논문이다.
크게 보면 non-rigid ICP를 대신 하는 방법.
메모
 |
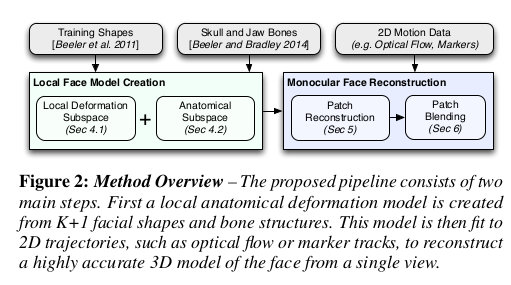 given 1) training shapes : 다양한 표정 SCAN 2) skull and jaw bones : 뼈 fitting 완료 3) 2D motion data : 주어진 이미지 상의 dense face correspondence 확보 estimate 1) mesh를 local patch로 쪼개서 재 정의 2) patch 단위로 SCAN에 맞추어 가면서 blendshape 정의 3) 뼈와 엮어서 최적화 |
  |
 일단 face mesh는 각각 patch로 잘게 쪼개짐. 각 patch는 미리 사전 정의된 위치, 크기이며 각 SCAN마다 patch topology를 유지한 체 patch fitting을 한다. -> 이 때 각 patch는 휘어짐, 꺾임 등 각각 non-rigid deformation 값을 다 들고 있음. 각 SCAN 별 patch 별, blendshape을 들고 있는 모양. patch level blend shape이라고 보면 됨. -> patch 단위로 쪼개서 local하게 변화를 잡아내는 것도 표현력 향상에 큰 도움이 되는데 각 patch가 휘어짐, 꺾임도 들고 있기 때문에 매우 표현력이 좋아짐 patch가 rigid transformation (위치 변화)되는 건 글로벌하게 head pose + jaw pose로 잡아줌. |
  |
각 패치를 정의할 때는 UV map 상에서 고른 면적으로 쪼갬. 따라서 mesh 상에서 patch가 정사각형이 아닐 수 있다. 패치는 서로 약간의 overlap이 있도록 했음. 이는 변형 후에 빈 공간이 생길일을 예방하기 위해서 patch를 넉넉한 크기로 만드는 셈. 움직여도 patch가 mesh를 다 덮고 있도록. |
 |
각 패치 별로 각 SCAN에 fitting을 해보면서 patch parameter를 찾아두어야 함. 이게 D. 이건 어느 방향으로 휠지, 얼만큼 꺾일지 같은 양인데 D 가 일종의 plane deformation을 결정하는 eigenvector 같은 것이다. 이걸 미리 찾아뒀다고 가정하고 시작함. 어떤 patch가 어떤 표정일 때는 어떻게 휘어있는지 미리 찾아둔 것과 같음. 특정 표정의 patch 상태는 이렇게 미리 찾아둔 patch 상태의 blended sum으로 결정되는데 이 때 blend weight, alpha를 최적화하면 문제가 풀리는 것. |
  |
patch 단위로 최적화를 해서 잘 풀리면 다행이겠지만, patch 단위로 쪼개서 자유도를 열어준 만큼 최적화 난이도가 기하급수적으로 올라간다. 따라서 그냥 최적화했다간 제대로 수렴하지 않는다. 이를 해결하기 위해서 미리 SCAN에 fitting 해두었던 뼈 mesh를 이용한다. 간단히 말해 patch 중심점의 위치를 xyz 그냥 자유롭게 최적화되도록 냅두는 것이 아니라 patch 중심점 위치 = 뼈 + normal * 피부 두께 로 정의해두었다. 이렇게 하면 뼈가 고정값이기 때문에 자유도가 낮아지고, 피부 두께가 너무 크지 않도록 regularization할 수 있는 선택지가 늘어나기 때문에 최적화 난이도를 크게 낮출 수 있다. 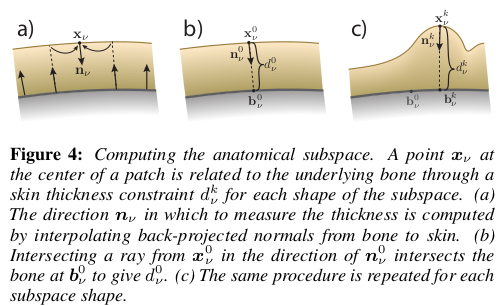 |
  |
patch 중심점 위치 = 뼈 + normal* 피부 두께를 수식으로 쓰면 수식(2)와 같이 됨. 이 때 뼈 b, normal, n, 피부두께, d도 앞서 patch가 사용하는 blend weight를 공유한다고 가정함. 추가로 여기서 k번째 표정일 때 뼈 b_k는 수식 상 다양할 것 같지만 표정이 바뀐다고 뼈가 바뀌는 것은 아니기 때문에 턱뼈가 움직여서 뼈에 변화가 있는 표정이 아니라면 그냥 상수다. 따라서 자유도가 낮아짐. |
 |
최적화 energy function은 크게 4 종류 1) 2D dense face correspondence + patch 와의 correspondence까지 사실 상 모든 correspondence가 주어졌다고 가정하고 reprojection error를 사용함 -> 이는 사전에 SCAN 당시 얼굴에 마커를 부착해서 3D SCAN과 이미지 상의 correspondence를 찾아둘 뿐만 아니라 매 SCAN 간의 correspondence도 다 찾아놨기에 가능함 -> 일반적인 상황에서는 이런 데이터가 없기에 사용 불가능한 loss 2) patch smoothness, 인접한 패치라면 위치가 변형 전후로 다 비슷해야 함 3) 뼈 + normal*피부 두께 에서 normal, 피부 두께가 잘 찾아지도록. 4) 시간 축에 따라 consistent하도록 -> 다양한 표정 변화 SCAN을 뜰 때, video 로 촬영해서 sequential 정보가 있음. |
 5.1이 온갖 correspondence 활용해서 만든 reprojection error 5.2가 인접 패치 별로 가까울 것. 5.3이 뼈 normal, 피부 두께로 잘 맞는지 5.4가 시간 축 consistency 유지하는지 |
  |
  |
구현 디테일인데, energy function 즉 loss를 구현했지만 대부분 on-linear term이라 taylor expansion해서 1st order만 잘라내서 jacobian을 계산하는 식으로 했음 -> 이때는 pytorch 같은 auto grad가 잘 지원되지 않을 때인 걸 감안. |
 |
 patch 최적화가 끝나서 blend weight, alpha를 잘 찾았다고 해서 문제가 끝난 건 아니다. overlapping patch를 사용했기 때문에 위 그림 a처럼 patch가 서로 어긋나서 2번 덮는 영역이 생겨있음 이를 단순히 vertex 별로 평균내면 살짝 아쉬움 따라서 vertex 별로 엮여있는 중복 patch의 값을 평균내되, 각 patch가지 거리를 기준으로 weighted average를 취했다. 그럼 c 처럼 조금 더 자연스럽게 됨. |
 |
 패치 크기가 얼만큼 커야 좋을지는 실험적으로 최적값이 있음. concave하게 성능 지표가 나오므로 해당 적정값을 찾아서 사용하면 됨. |
  |
 반면 표정, 즉 SCAN의 개수는 많을 수록 좋다. 특히 extreme 표정이 많으면 도움이 더 많이 된다. |
 |
|
 |
 |
 |
 in the wild라고 해서 진짜 in the wild 아니고, dense correspondence는 다 이미 갖고 있어야 한다. |
 patch 단위로 하는 것의 장점은 만약 표정이 아니라 바람 에 눌린 것처럼 국소적인 변화도 최적화만 잘되면 표현이 된다는 것. |
 dense correspondence가 얻기 힘드니 만약 sparse이면 어떻게 되나. 그래도 나름 잘 동작한다. |
 만약 2D correspondence를 임의로 옮겨서 최적화하면 표정 변화도 가능. |
 |
반응형
'Paper > Human' 카테고리의 다른 글
| EMOPortraits: Emotion-enhanced Multimodal One-shot Head Avatars (0) | 2024.07.08 |
|---|---|
| Face Reconstruction in the Wild (0) | 2024.07.07 |
| Local Anatomically-Constrained Facial Performance Retargeting (0) | 2024.07.02 |
| High-Resolution Neural Face Swapping for Visual Effects (0) | 2024.07.01 |
| Learning Dynamic 3D Geometry and Texture for Video Face Swapping (0) | 2024.07.01 |